One static model does not fit all😭
We just dropped our latest work: Functional Neural Memory. Instead of static models, we generate custom "parameters" for every single input.
✅Prompt your model anytime
✅Instant personalization
✅Better instruction following
✅Flexible & dynamic memory (w/o memory bank✌️)
(🧵1/6)
I am going to give a talk at the Lock-LLM #NeurIPS2025 workshop ( https://t.co/RDyhhRWaTY ) at Room 1AB (Upper Level) 10 am (PST). Join me to discuss the dark knowledge for LLMs.
If the #NeurIPS2025 app is crashing for you (like it’s for me) to the point that’s unusable, here a website with all the content/sessions:
https://t.co/u3OyKEa6vt
🚨 🤯 Wow! Yi Lin is an amazing researcher, who works on very hard and important problems in LLM and VLM training, RL, PEFT, Quantization, etc. -- ironically, he had several other top offers just a few months ago!
Hire him ASAP if you want to pick up a top talent (and several other affected amazing folks)!
👇👇
🚀Founded by four dedicated MIT graduates, Eigen AI is the world's first company focusing on AEI – Artificial Efficient Intelligence, making AI accessible for all.
Today OpenAI dropped GPT-OSS. We teamed up with our partners SGLang @lmsysorg and @NVIDIA to deliver open-source support of the model with blazing-fast performance on Hopper and Blackwell GPUs just within 4 hours of the release. 🔥
With @YottaLabs, we're stoked to launch a free GPT-OSS-120B playground chatbot & API at https://t.co/BQfsnXIGFo 🚀 Easy-to-use, high-performance, and ready for your projects. Share with us what you are building with it! 🌟
Join us to unlock AI’s potential. Let’s democratize efficient AI for everyone! 💪 #AI #Innovation #EfficientAI #Chatgpt #GPT #performance #LLM #openai #eigenai
At WWDC we introduce a new generation of LLMs developed to enhance the Apple Intelligence features. We also introduce the new Foundation Models framework, which gives app developers direct access to the on-device foundation language model.
https://t.co/SnjCXrIyYj
Cursor Agent is just wild.
Now i use Gemini PRO 2.5 to scan the codebase and sonnet 3.5/3.7 to execute code.
In this workflow you need 3 things:
1. Detailed project documentation
2. Use multiple AI coding models
3. 50-step implementation plan
I spend 30 hours/week on cursor. I've found out the best cursor practices and the workflow.
I attached the best practices below and here's the best workflow.
Your project docs (PRD, Tech stack & APIs doc, app flow doc stec) works like a knowledge base for AI models.
If AI models find all necessary information within the knowledge base, they don't hallucinate, assume things and don't ruin the codebase.
So must add project docs in your root directory. Ideal place is add them under project rules (.cursor/rules)
Then you need to use multiple AI models. Now I am using Gemini PRO 2.5 to scan the entire codebase (cus it has 1M context) and find errors or update docs.
And I use Sonnet 3.5 to execute code. If it's a bit complex step then I also use Sonnet 3.7.
Sometimes I also use GPT o1 model to debug but rarely (mostly done by Gemini pro 2.5)
So 2.5 to scan, update, and 3.5/3.7 to execute.
Each model has its superpowers. We need to maximize those.
Lastly, you need to write an end-to-end plan to code your app. I call it "implementation plan."
This implementation plan works as a blueprint for Cursor Agent and it just follows the tasks and executes those.
I use @CodeGuidedev to generate coding docs + it provides 50-step implementation plan to code the entire app.
Now it also supports MCPs. Imagine Cursor using Supabase MCP to create database tables, and add policies autonomously. It just saves so much time.
So wrap up of the workflow is:
Attach your coding docs + use multiple AI models in your flow + have a solid 50-step implementation plan.
And you'll see how powerful Cursor Agent is.
I hope this'll refine your Cursor coding workflow. Let me know your findings.
I'm on the job market! Please reach out if you are looking to hire someone to work on
- RLHF
- Efficiency
- MoE/Modular models
- Synthetic Data
- Test time compute
- other phases of pre/post-training.
If you are not hiring then I would appreciate a retweet!
More details👇
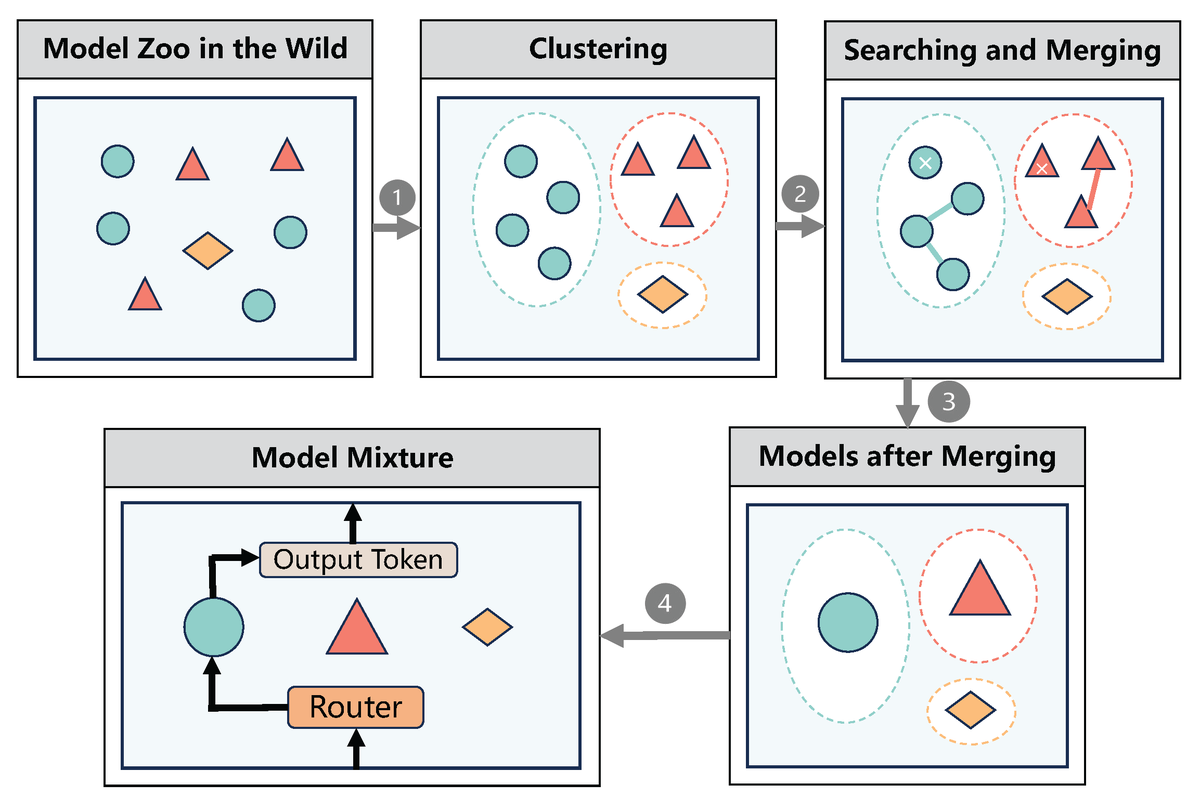
With countless open-source LLM checkpoints available, each specializing in unique domain knowledge, how can we tap into their full potential? Check out Model-GLUE! 🚀 We introduce a framework that integrates model merging, mixture, and stacking to unlock new possibilities.
1/ 🌟 Excited to announce #Model-#GLUE (#neurips2024 D&B), a new framework designed by an extensive team from UNC, UMD, UT Austin, HKUST, Google, and CMU to #scale pre-trained LLMs efficiently!
🚀 Tackling the challenge of #aggregating disparate pre-trained LLM, we introduce a holistic guideline and benchmarking if you have a large, diverse model zoo "in the wild"! #LLM #AIresearch
🎉 Check out our new preprint - GLIDER!
How do we solve held-in/-out tasks with a collection of specialized experts like LoRA? 🤔
GLIDER Improves generalization across held-in and held-out tasks by combining the power of:
🪂LLM-guided task instructions for global routing btw specialized experts.
🪂Local token-level routers refine the expert selection, optimizing which modules contribute.