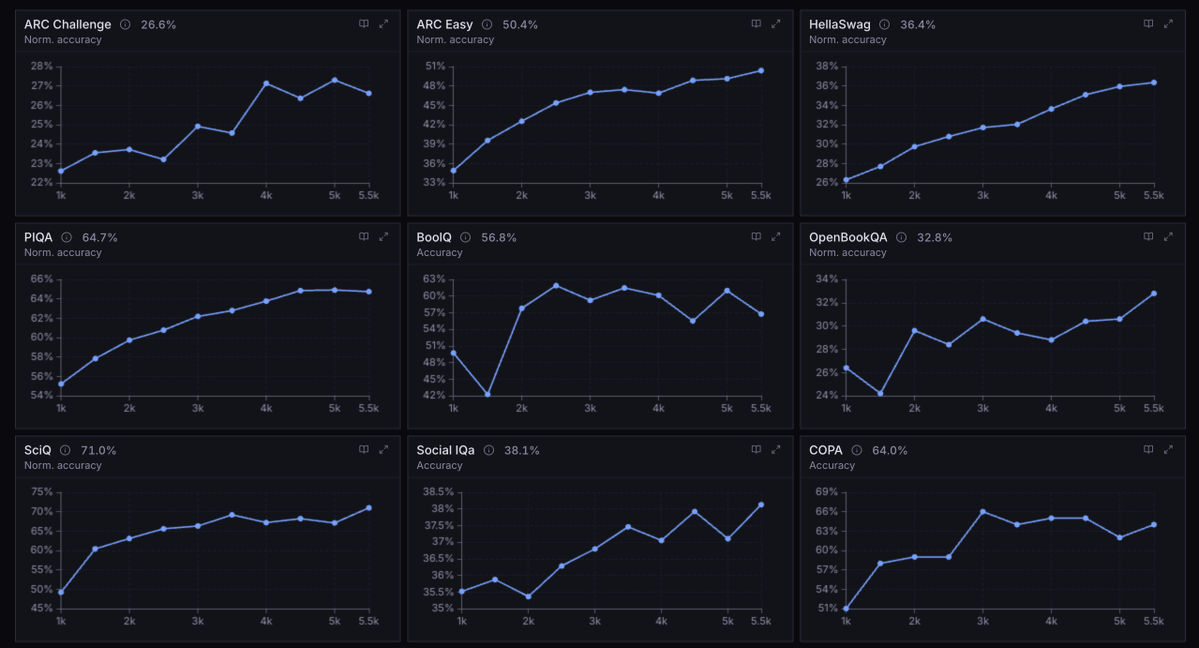
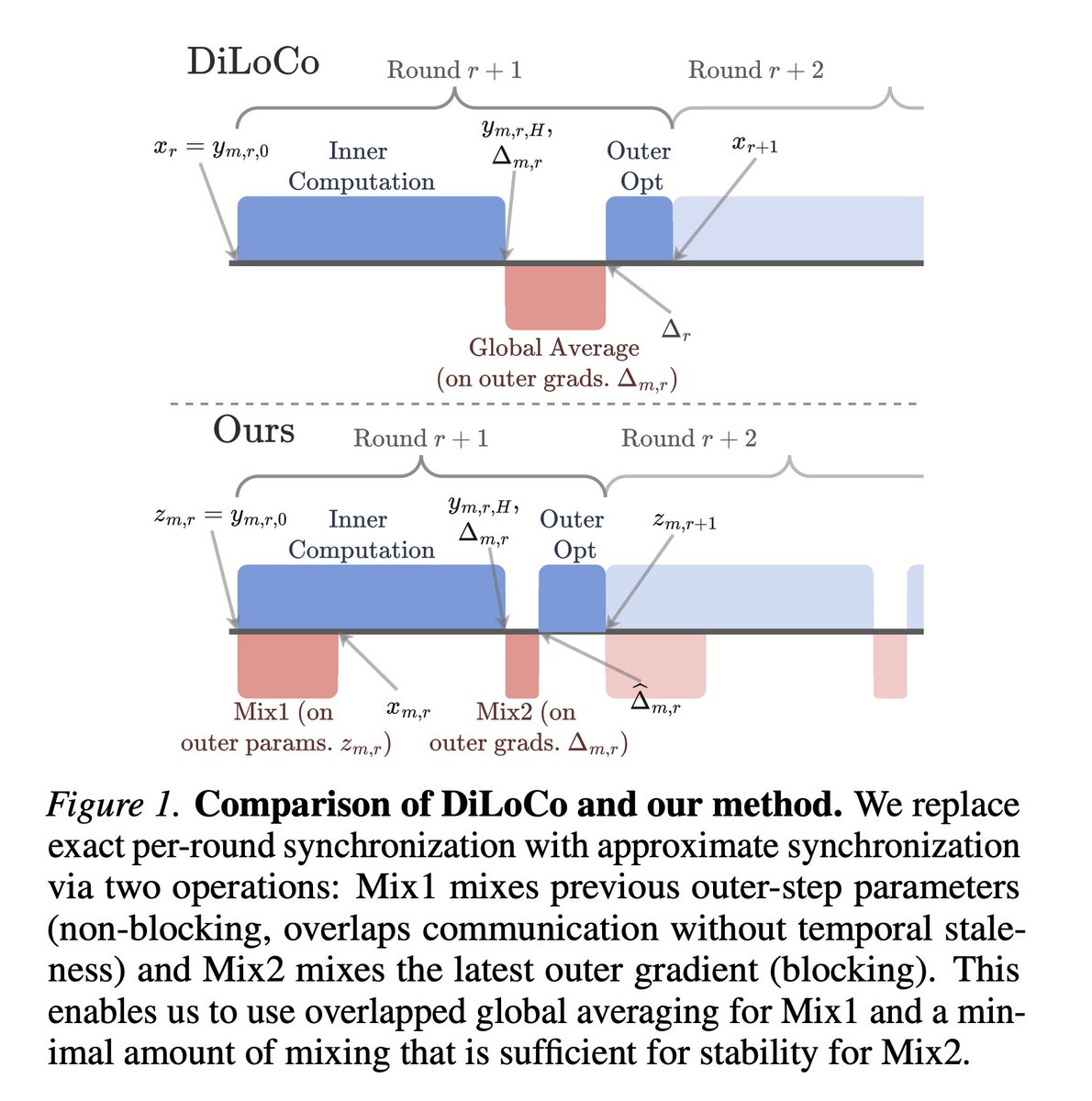
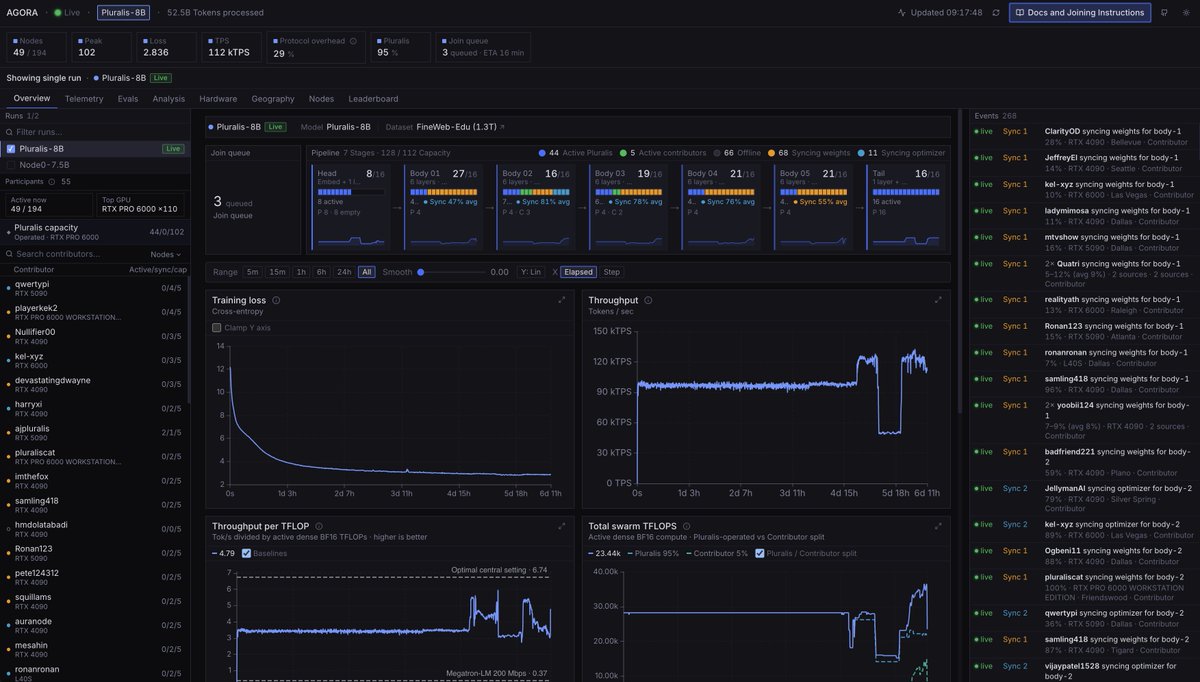
Today we're releasing Agora: the first ever pretraining stack that allows non-collocated consumer GPUs to be competitive with centralized clusters
Agora is 15x faster than Megatron-LM in this setting and is only 1.5x less efficient in terms of tokens per unit compute than TorchTitan on H100s, despite running on devices that have no NVLink or InfiniBand support.
#ICML26 is around the corner, and I'm excited to be already in Seoul for the conference! 🇰🇷
At @Pluralis , we're building decentralized training over the internet with the goal of making AI development more open, distributed, and democratic.
I'll be around throughout the week, so if you're interested in decentralised AI, collective training, frontier risk, or new approaches to AI infrastructure, let's grab a coffee ☕
A few things we're involved in during ICML...
Sunday, July 5th: I'll be at Foresight Institute workshop "Supercooperation: The Future of AI for Democracy," alongside @AsherT
Monday, July 6th: @hmdolatabadi and I will be at @farairesearch Seoul Alignment Workshop, discussing frontier risks in decentralised AI.
Tuesday, July 7th: @ChaminHewa will present our paper, "Factored Gossip DiLoCo: Reducing Blocking Communication in DiLoCo," in the main conference. Paper: https://t.co/MIAjzyH0aB
Thursday, July 9th: We're running an official ICML social with a panel on "Collective, Decentralized Training as a Hedge Against AI Power Concentration." RSVP: https://t.co/vbYpBhhHoM
Friday, July 10th: We're hosting the 2nd Workshop on Protocol Learning with #POSTECH, with a fantastic lineup of speakers. Register: https://t.co/Kg8xNLL1lV
Looking forward to seeing old friends and making new ones in Seoul.
#ICML2026 #MachineLearning #DecentralizedAI #ForesightInstitute #FARAI #POSTECH
Saw this person say "maybe only one of you will even watch half of this"... "but this is some of the deepest alpha around" so I got curious...
Ran the full Pluralis Protocol Learning Workshop videos through @NousResearch Hermes using the youtube-content skill - Structured summaries w/ timestamps for all 7 main talks + 6 lightning talks (including Agent instructions to call full transcripts).
Jump straight to talks/topics of interest or provide your agent at the .md and ask away!
Full Markdown: https://t.co/rqfCY8K9Pb
Original workshop: @Pluralis via @AsherT
Stable APIs made intelligence easy to consume. Training protocols can make it something we build together; not a checkpoint someone releases but an economy people can participate in. That's what we've been building at @Pluralis.
A masterclass on the future of collectively owned AI from the @Pluralis Workshop at ICLR.
Covers distributed model training, low-bandwidth parallelism, unextractable models, and more from: @niclane7@m_ryabinin@AlexanderLong@oguzer90@SameeraRamasin1
https://t.co/xgvcMatpHX
New speaker confirmed for the Protocol Learning Workshop at ICML:
@aaron_defazio "Making your Theory-to-Practice Work: Online-to-Batch via Schedules & Schedule-Free Learning" via a remote presentation.
View our updated agenda + register here: https://t.co/slAqXcuxjP
It's now clear both labs will restrict access to the best modes to a small group of trusted parties. Unlike other technology, not having access fundamentally reduces your value/effectiveness as an individual or company, and you have effectively no recourse. The impact of this is hence very severe. However, there are reasons to be very optimistic - the engineering and research required to coordinate large swathes of independently controlled compute and to construct an independent and a sovereign model supply chain is hitting the tipping point of feasibility at the exact same time the world is waking up to what is effectively an existential threat. Many people are completely unaware of how progressed the research in decentralized training/training in protocols is - things are looking extremely promising. If we were starting from scratch today, the situation would be far worse.
The primary problem these approaches have to address is that compute cannot be pooled for training without compression (as you don't have fast interconnects you have in a datacenter). However, if you have big nodes, and every node keeps a copy of the model, DiLoCo (@Ar_Douillard ) and variants (SparseLoCo from @amir_sarfi , Factored Gossip DiLoCo from @ChaminHewa) solve this problem. SPARTA from @exolabs is also very promising, and these two classes of approaches can also be combined. The common argument is then "ok so everyone training needs multiple 8xB200 nodes which only exist in datacenters that doesn't seem very decentralized". Subspace Networks from @SameeraRamasin1 address this compressing activation and activation gradients, which then allows a large model to be split over participants (pipelined with each holding a layer or sequence of layers). This is the fundamental technology that really allows anything to work; SSNs + SPARTA is whats live in Agora right now with each participant serving a small shard. It allows consumer cards to be productive (of which there are A LOT - far more than people think), and also lets the approach scale to large models.
Even with this level of compression - which unlocks this class of approaches in theory, there remains many other problems. Verification is often considered very difficult - however it's actually easier than the deterministic verification normally required - the models are inherently robust - a large amount of training is actually injecting randomness and pertubations to induce generalisation. Methods such as SENTINEL by @hmdolatabadi can hence be extremely effective here and are specific to large model training - you can't do this for arbritary computation.
There is much more work than what I've listed, and there is also so much work to do - but how can this not be exiting rather than distressing to people - this can work! From an ML research perspective it's incredible - suddenly there is a new substrate to work on - every modelling and arch design decision can be rethought. Growing the networks within swarms actually feels MORE correct to me than in monolithic blocks of datacenter compute. There are scenarios here where you actually decouple productive capacity from the old control structures - that's never happened before - it's never even been close to possible... if you have any ability to work on these area's how could you be spending a second doing anything else.
An over-looked property of Subspace Networks (SSNs) which we've been using in Agora and I'm personally fond of is its transformability into a regular, full-rank model without the compression heads. You can simply fold the low-rank compressors into the projection matrices and so you don’t have to keep special compression heads around at inference time.
This is an important property for decentralised training infra: communication-saving architecture changes are much more useful if they don’t lock the final model into a nonstandard final format.
The workshop also includes a poster session featuring the following work:
@itsmaddox_j – LoRDO: Distributed Low-Rank Optimization with Infrequent Communication
• Xingyu Qu – Can Muon Fine-tune Adam-Pretrained Models?
• @benjamintherien – MuLoCo: Muon is a practical inner optimizer for DiLoCo
• Jin Lee – SPARe: Stacked Parallelism with Adaptive Reordering for Fault-Tolerant LLM Pretraining
• @sungbin_shin – Mitigating Staleness in Asynchronous Pipeline Parallelism via Basis Rotation
• Jeffrey T. H. Wong – A3: an Analytical Low-Rank Approximation Framework for Attention
https://t.co/N1XewsUhrY
We are hosting a workshop during ICML on Protocol Learning to examine the key open challenges in collaborative training across distributed networks.
Talks by @Ana_koloskova@sam_hrvth@hmdolatabadi & more speakers to be announced
Register here: https://t.co/slAqXcuxjP
Factored Gossip DiLoCo (by @ChaminHewa) has been accepted to ICML 2026. It removes the all-reduce required to compute the outer-optimiser step, improving robustness to failed nodes. In a collective training setting, this allows nodes to leave arbritarily with minimal impact.
After what Anthropic just did, it's clear that the only way to make sure AI is good for humanity is decentralized AI.
So I decided to join @Pluralis as a research scientist to build models no one can own or switch off, building on my work making RL weight sync ~100x more efficient (now in trl, slime, composer 2), as well as other contributions to the field like Covenant72b.
The 8B model currently training on Agora is 350B tokens in and continuing to converge. The top level metrics and evals look almost exactly like a centralised run. But;
- 133 external contributors total bringing 4090's, 5090's, L40S/RTX 6000 and RTX 6000 Pros. These are cards that people actually own - there are no H100, B200's etc.
- The max number of nodes the system can support (104) was filled almost immediately. The authorization layer is receiving approximately 100 requests/minute to join.
- The total tokens/per second processed moves directly with amount of compute in the swarm, with Agora constantly optimising to make most efficient use of what hardware is present.
- MFU is approximately 20%, TPS is 170k tok/s. There are near constant communication failures which Agora is completely absorbing without slowdown.
- The system is effectively on auto-pilot, requiring very little intervention from us. Bad nodes are purged immediately before training is affected and new nodes take their place.
I would like to make a few brief points;
- Opensource ai is not the same thing as opensource software. The models cost tens to hundreds of millions to make. This is not gonna be a volunteer effort from people doing stuff after work for free.
- the second you release a weight set, you lose any ability to make money serving your own model and recoup the training cost. This very simple property means open-weights is unsustainable.
- the things you ACTUALLY want from opensource ai is: transparent behaviour, dispersed ownership and control, a guarantee of access, the ability to build on it/modify it, and privacy.
protocol learning gets you all 4 and is the only alternative to closed models that makes any kind of sense.
By protocol learning I mean a very specific, novel thing; collaborative training and development of the models without anyone ever being able to see the complete weight set.
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
The single most immediate, impactful downside to AI is concentration of power risk. This is 1/100th of how bad it's going to get.
The only way out of this is to have an independent model supply chain via pooled compute.