PyLO is accepted to MLSys 2026! 🎉🚀
A PyTorch-native library bringing SOTA learned optimizers to the codebases most of us actually use — with fast CUDA kernels and real speedups on large-scale training. Drop-in ready, no more JAX-only barriers.
Library: https://t.co/NTjBF64jD3
Have you ever trained a neural network using a learned optimizer instead of AdamW? Doubt it: you're probably coding in Pytorch! Excited to introduce PyLO: Towards Accessible Learned Optimizers in Pytorch! . Accepted at @icmlconf ICML 2025 CODEML workshop 🧵1/N
🎉 Our paper "𝗙𝗿𝗼𝗺 𝗠𝗲𝗺𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝘁𝗼 𝗣𝗮𝗿𝗮𝗺𝗲𝘁𝗲𝗿 𝗜𝗻𝘁𝗲𝗿𝗳𝗲𝗿𝗲𝗻𝗰𝗲: 𝗛𝗼𝘄 𝗢𝘃𝗲𝗿𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 𝗛𝗮𝗿𝗺𝘀 𝗠𝗼𝗱𝗲𝗹 𝗠𝗲𝗿𝗴𝗶𝗻𝗴" was accepted at ICML 2026!
🔎 Do better expert models always lead to better merged models? Not necessarily!
📜Read the paper: https://t.co/aJN7Oi8Dw2
🧵 1/9
Training big models gets painful once a full replica won't fit on one accelerator.
You end up with model-parallel methods or techniques like FSDP that are communication-heavy and limited in how far they parallelize.
We tried a new axis that lets you split the model the way model parallelism does, but communicate gradients instead of activations.
🧵 1/N
🚨Excited to announce our workshop Context Beyond the Window hosted at COLM in SF! 🚨
LLMs have finite context windows, yet real-world tasks demand absorbing, retaining, and acting on information that far exceeds any single prompt.
1/3
We're looking for submissions across:
https://t.co/6y1ILeeC9A
• Context compression 🧃 — token compaction, recursive subagent calls, and external memory for storing and retrieving information
• Efficient architectures 🚀 — sub-quadratic attention variants that make extremely long context computationally feasible
• Continual training 🌱 — test-time training on streaming data, context distillation, and knowledge accumulation through continued pre-training
• Agentic memory systems 🐘 — scaffolds and test-time scaling techniques that improve knowledge retention and acquisition in LLMs
• Evaluation 🎯 — benchmarking models on increasingly long-horizon tasks
I’ll be at #MLSys2026 this week to present “PyLO: Towards Accessible Learned Optimizers in PyTorch”!
Come listen to @janson002’s presentation today from 3:45PM – 4:00PM in room 2 or join us at poster 29.
If you work on similar topics or just want to chat — DM me. 1/2
Presenting today at @MLSysConf 2026: PyLO🚀
Learned optimizers (like VeLO) have been stuck in JAX. PyLO brings them to PyTorch via the standard torch.optim interface, with CUDA kernels and HF Hub weight loading. #MLSys2026
https://t.co/NTjBF64jD3
This is like a good stress test for optimizers.
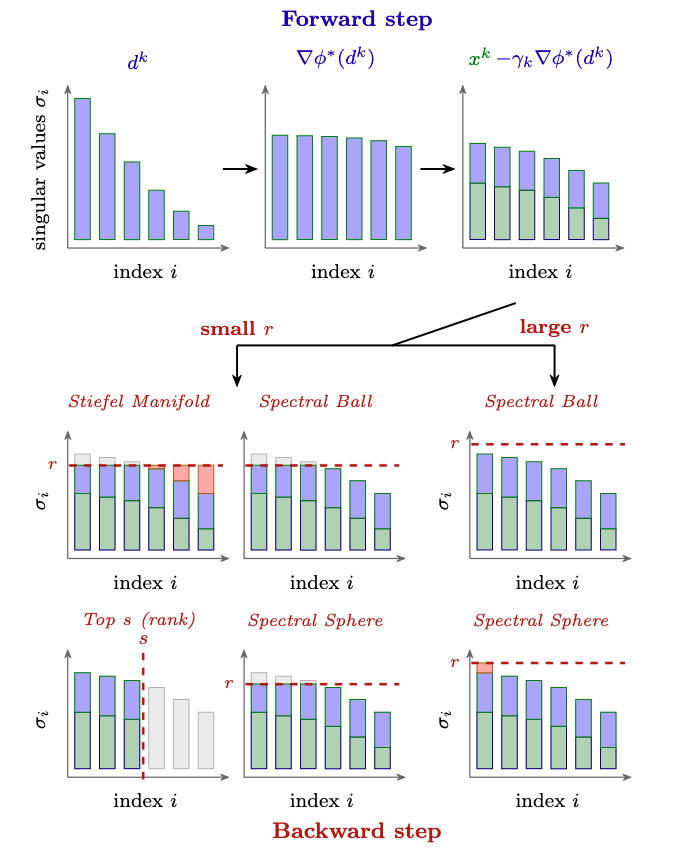
Kaon is basically Muon/lmo + spectral noise. It preserves the singular vectors of the gradient and randomizes only the positive singular weights. For exchangeable noise, the conditional expectation is the spectral-norm-ball lmo direction up to scale. Individual draws are not necessarily lmos tho.
Freon’s map for c>1/2 is decreasing on the singular values, so the operator is non-monotone. Exact fixed-step Freon can fail even on a simple convex quadratic minimization near rank deficiency.
Freon’s map for c<=1/2 (i.e., the monotone case) can also be analyzed using phi-convexity. Shameless plug: https://t.co/nm16wKDz9L
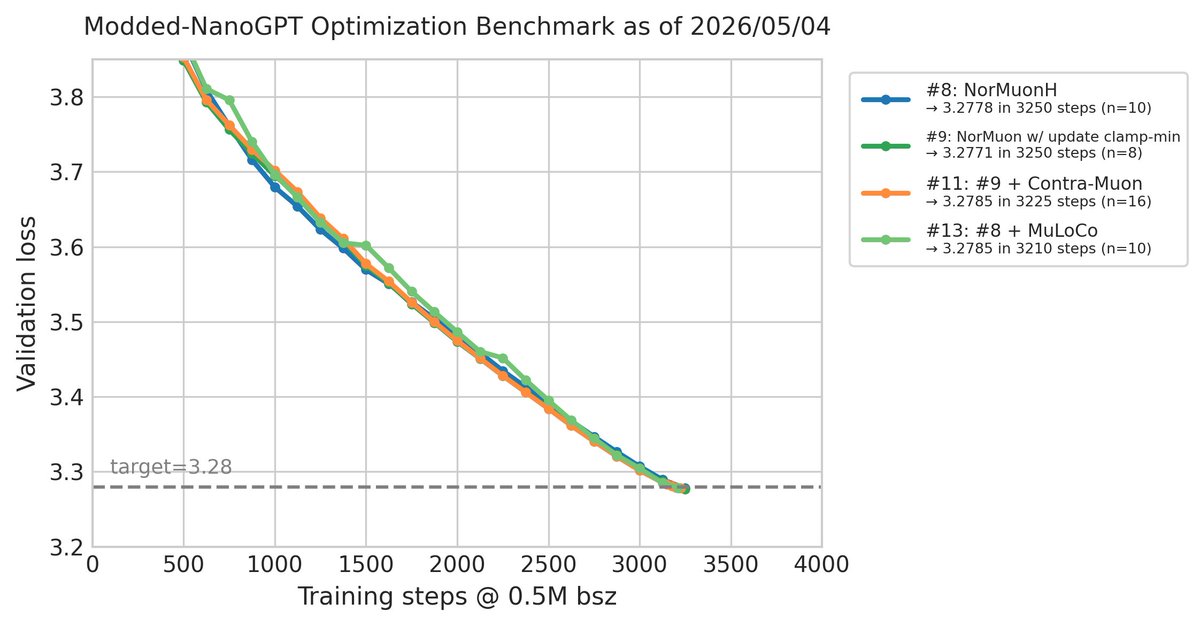
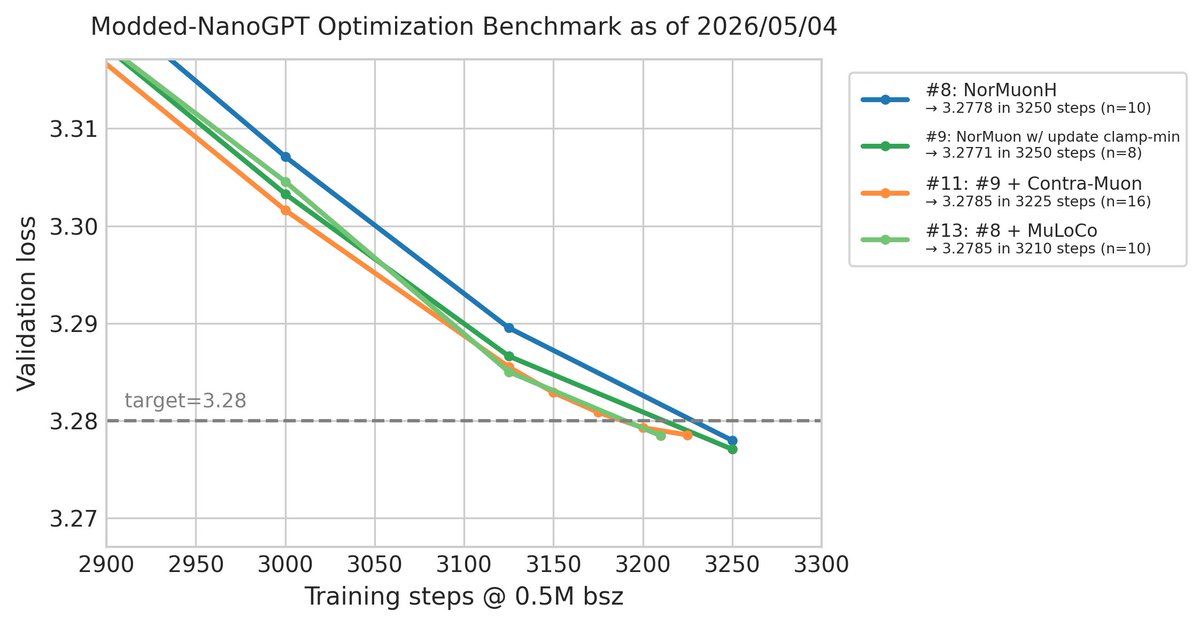
Modded-NanoGPT optimization result #13: @benjamintherien has achieved a new record of 3210 steps (-15), by wrapping NorMuonH in a MuLoCo-style outer Nesterov SGD.
Compared to the target loss, this result has a p-value of p=1.3e-4. Compared to result #11, it has p=0.099.
@WorldEdServices@WorldEdServices Applicants paying for credential evaluations deserve a two-way communication channel. Contact forms with no-reply responses aren't workable when documents go missing. DMing reference number and asking for a named case owner. Hoping for real help.
I’ll be at #ICLR2026 🇧🇷 this week to present “μLO: Compute-Efficient Meta-Generalization of Learned Optimizers” and give a talk about SparseLoCo at the Protocol Learning Workshop!
If you work on these topics or just want to chat — DM me. 🧵1/3
Heading to Rio 🇧🇷 to present our Celo line of work at #ICLR2026!
Get in touch if you are curious about new avenues in neural network training or how we scaled learned optimizers from CIFAR-10 to GPT-3 🚀
Details ⬇️
PyLO is accepted to MLSys 2026! 🎉🚀
A PyTorch-native library bringing SOTA learned optimizers to the codebases most of us actually use — with fast CUDA kernels and real speedups on large-scale training. Drop-in ready, no more JAX-only barriers.
Library: https://t.co/NTjBF64jD3
PyLO is accepted to MLSys 2026! 🎉🚀
A PyTorch-native library bringing SOTA learned optimizers to the codebases most of us actually use — with fast CUDA kernels and real speedups on large-scale training. Drop-in ready, no more JAX-only barriers.
Library: https://t.co/NTjBF64jD3
Have you ever trained a neural network using a learned optimizer instead of AdamW? Doubt it: you're probably coding in Pytorch! Excited to introduce PyLO: Towards Accessible Learned Optimizers in Pytorch! . Accepted at @icmlconf ICML 2025 CODEML workshop 🧵1/N
Latent CoT is an alternative LLM reasoning scheme hypothesized to enable “superposition” allowing models to hold uncertainty over multiple concepts during reasoning 💭
We revisit superposition in 3 latent CoT approaches and find that it is largely an illusion 🔮!
More in 🧵
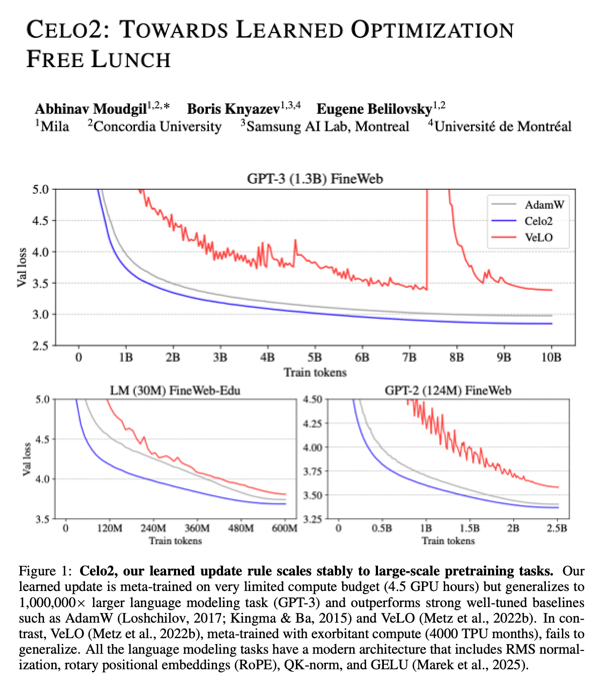
Introducing Celo2: Towards Learned Optimization Free Lunch
We show that learned optimizers can generalize to practical tasks like GPT-3 1.3B pretraining and several out-of-distribution vision/RL tasks from limited meta-training (~4.5 GPU hours)!
🧵
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n
🚨 New Tech Report: Covenant-72B 🚨
TL;DR we use SparseLoCo to pre-train a 72B model on 1.1T tokens over the internet! This is the largest decentralized training run to date.
https://t.co/vucL1Asr6w
Masked Diffusion LMs (MDLMs) are the most exciting paradigm shift in AR generation because they can decode in parallel, infill, and self-correct.
But they are bottlenecked by the transformer's quadratic attention, making throughput fall apart for long contexts.
We offer a simple solution. Introducing DiffuMamba: first diffusion LM with a bidirectional Mamba backbone. Better quality. Up to 8.2x faster.
🧵1/N