The Top AI Papers of the Week (April 19 - 26)
- Skill-RAG
- DeepSeek V4
- Autogenesis
- Attention to Mamba
- Stateless Decision Memory
- Self-Evolving Logic Synthesis
- Self-Generated World Knowledge
Read on for more:
PyLO is accepted to MLSys 2026! 🎉🚀
A PyTorch-native library bringing SOTA learned optimizers to the codebases most of us actually use — with fast CUDA kernels and real speedups on large-scale training. Drop-in ready, no more JAX-only barriers.
Library: https://t.co/NTjBF64jD3
Heading to Rio 🇧🇷 to present our Celo line of work at #ICLR2026!
Get in touch if you are curious about new avenues in neural network training or how we scaled learned optimizers from CIFAR-10 to GPT-3 🚀
Details ⬇️
NEW paper from Apple.
Interesting idea: "Attention to Mamba".
The paper introduces a two-stage recipe for cross-architecture distillation from Transformers into Mamba.
Naive distillation collapses teacher performance. Their trick: first distill the transformer into a linearized-attention student using a kernel adaptation, then transfer that student into a pure Mamba with no attention blocks.
On a 1B model trained on 10B tokens, the Mamba student hits 14.11 perplexity against a 13.86 Pythia-1B teacher, nearly matching quality at linear-time inference cost.
If you can reliably convert trained transformers into state-space models without retraining from scratch, the entire open-weights ecosystem becomes cheaper to serve at long context. This is the kind of quiet infrastructure work that decides which architectures actually get deployed in agent stacks.
Paper: https://t.co/h7k7OrG8Qj
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Yes, exactly! We started this project with the goal of understanding representation capacity of Mamba modules and wanted to see how close we can get to Attention-based teacher model with pure Mamba architecture. Our two-stage approach is simpler + more principled and we do initialization with a lot of care so the underlying mechanics of sequence processing / performance of teacher model are retained as much as possible in every stage.
Attention → Mamba cross-architecture distillation is real
Transformer doesn't need to stay just a transformer – Apple showed how you can transfer it into a State Space Model (SSM)
▪️ It happens through a linearized-attention intermediate:
1. Distill the Transformer into a linearized attention model using a kernel trick:
→ Approximate the softmax exponential similarity in attention as a dot product of transformed features. This turns quadratic attention into linear attention.
2. Distill that model into Mamba SSM with proper initialization.
This method helps in 2 aspects:
- It avoids hybrid architectures
- And allows Mamba to reach perplexity 14.11 vs 13.86 for the original Transformer.
So the lesson here is not to start Mamba from random weights, but start it from a sequence mixer already aligned with the teacher Transformer.
So glad to see this release! Just look at that huge leap in CharXiv figure understanding 🤯
Our tiny team in London worked insanely hard to contribute in this area and even the initial results blew our minds completely. No surprise it's SOTA in this category :)
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
@Antrunt@BorisAKnyazev@ebelilov Thanks! It's the same as in standard optimizers: performance degrades smoothly as you deviate more from optimal LR. 1e-4 or 1/20x tuned AdamW LR are good starting points for Celo2.
More on LR sensitivity in appendix:
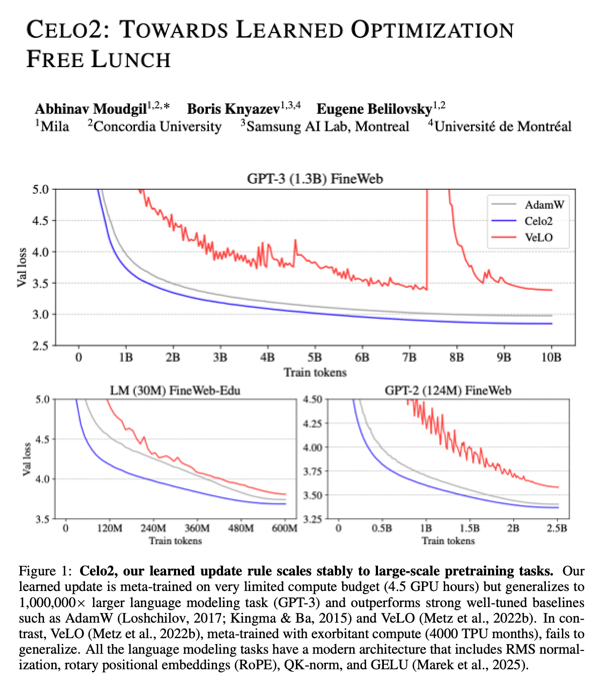
Introducing Celo2: Towards Learned Optimization Free Lunch
We show that learned optimizers can generalize to practical tasks like GPT-3 1.3B pretraining and several out-of-distribution vision/RL tasks from limited meta-training (~4.5 GPU hours)!
🧵
Finally, I'd like to acknowledge the Google TPU research cloud program that made this research possible and sincerely thank @mrtnm@kvfrans@_chris_lu_ for their open-source contributions by releasing clean jax codebases with TPU/FSDP support.
Work done with @BorisAKnyazev and @ebelilov. If you are interested in this line of research or related topics, our lab is hiring:
https://t.co/Z9FUIkY5dR