🎉 Our paper "𝗙𝗿𝗼𝗺 𝗠𝗲𝗺𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝘁𝗼 𝗣𝗮𝗿𝗮𝗺𝗲𝘁𝗲𝗿 𝗜𝗻𝘁𝗲𝗿𝗳𝗲𝗿𝗲𝗻𝗰𝗲: 𝗛𝗼𝘄 𝗢𝘃𝗲𝗿𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗘𝘅𝗽𝗲𝗿𝘁𝘀 𝗛𝗮𝗿𝗺𝘀 𝗠𝗼𝗱𝗲𝗹 𝗠𝗲𝗿𝗴𝗶𝗻𝗴" was accepted at ICML 2026!
🔎 Do better expert models always lead to better merged models? Not necessarily!
📜Read the paper: https://t.co/aJN7Oi8Dw2
🧵 1/9
Training big models gets painful once a full replica won't fit on one accelerator.
You end up with model-parallel methods or techniques like FSDP that are communication-heavy and limited in how far they parallelize.
We tried a new axis that lets you split the model the way model parallelism does, but communicate gradients instead of activations.
🧵 1/N
Check out our work on learned optimizers being presented at MLSys, I am also recruiting a student to work further in this direction (reach out by email if you have relevant experience/interest)
We're publishing our first end-to-end benchmarks for Zyphra Inference on @AMD Instinct MI355X.
Our inference optimizations strongly outperform the AMD baseline and narrows the gap between MI355X and B200 for serving Kimi K2.6, GLM 5.1, and DeepSeek V3.2 🧵
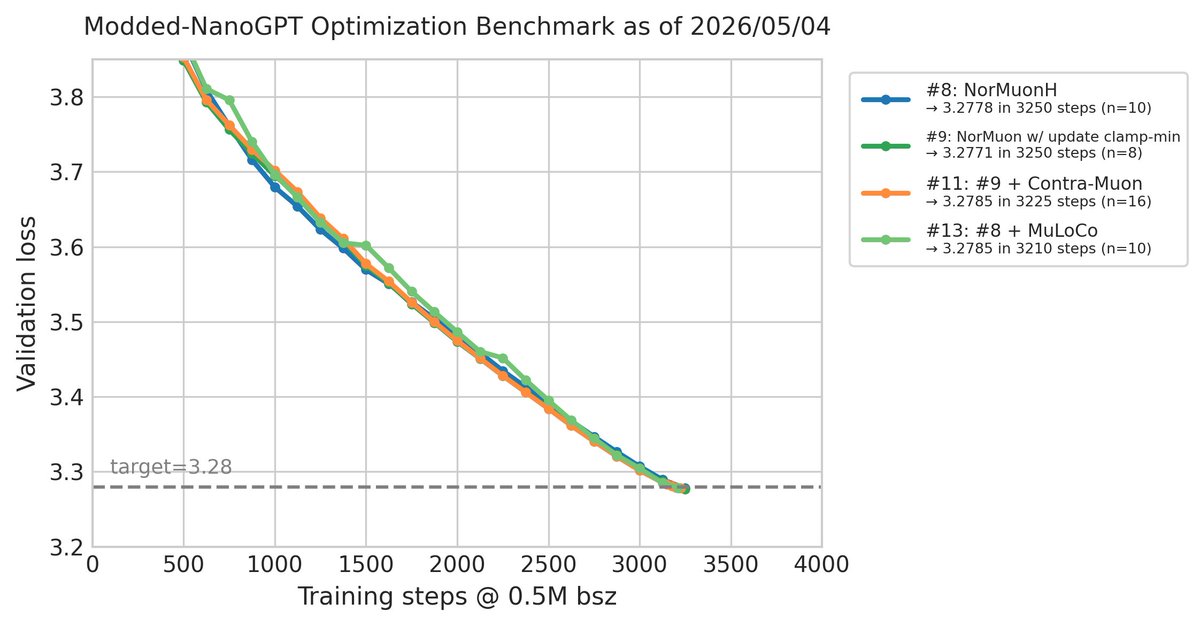
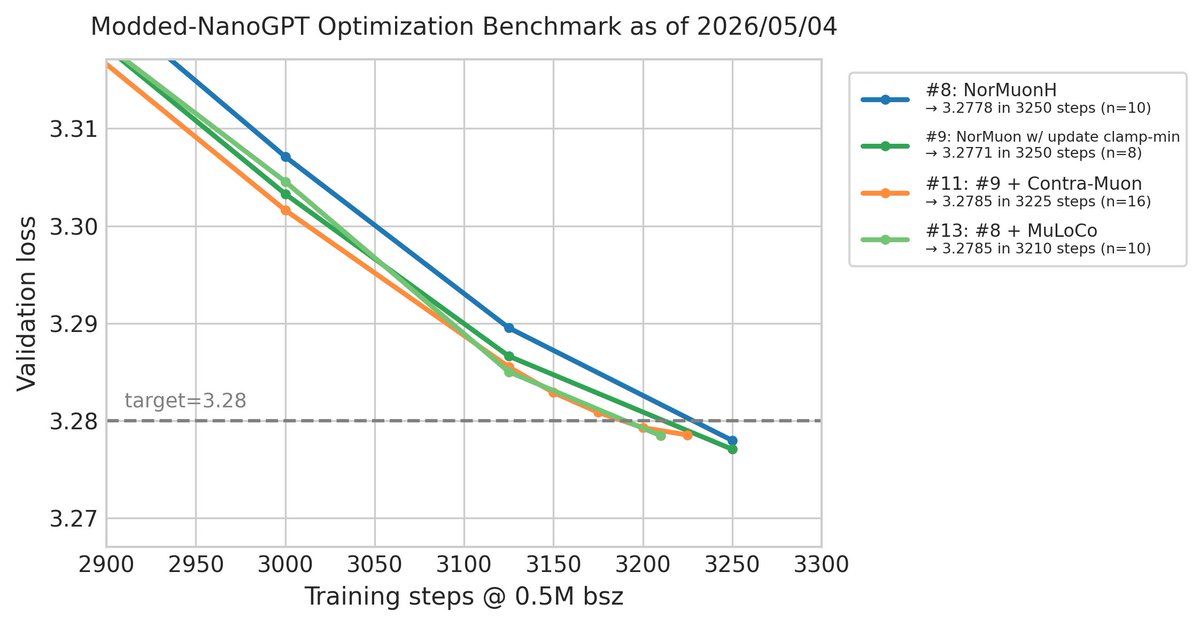
Modded-NanoGPT optimization result #13: @benjamintherien has achieved a new record of 3210 steps (-15), by wrapping NorMuonH in a MuLoCo-style outer Nesterov SGD.
Compared to the target loss, this result has a p-value of p=1.3e-4. Compared to result #11, it has p=0.099.
Heading to Rio 🇧🇷 to present our Celo line of work at #ICLR2026!
Get in touch if you are curious about new avenues in neural network training or how we scaled learned optimizers from CIFAR-10 to GPT-3 🚀
Details ⬇️
The DiLoCo team at Google DeepMind and Google Research is proud to release Decoupled DiLoCo, the next frontier for resilient AI pre-training.
Decoupled DiLoCo enables training with datacenters across the world, using heterogeneous hardware, and never halting the system despite hardware failures.
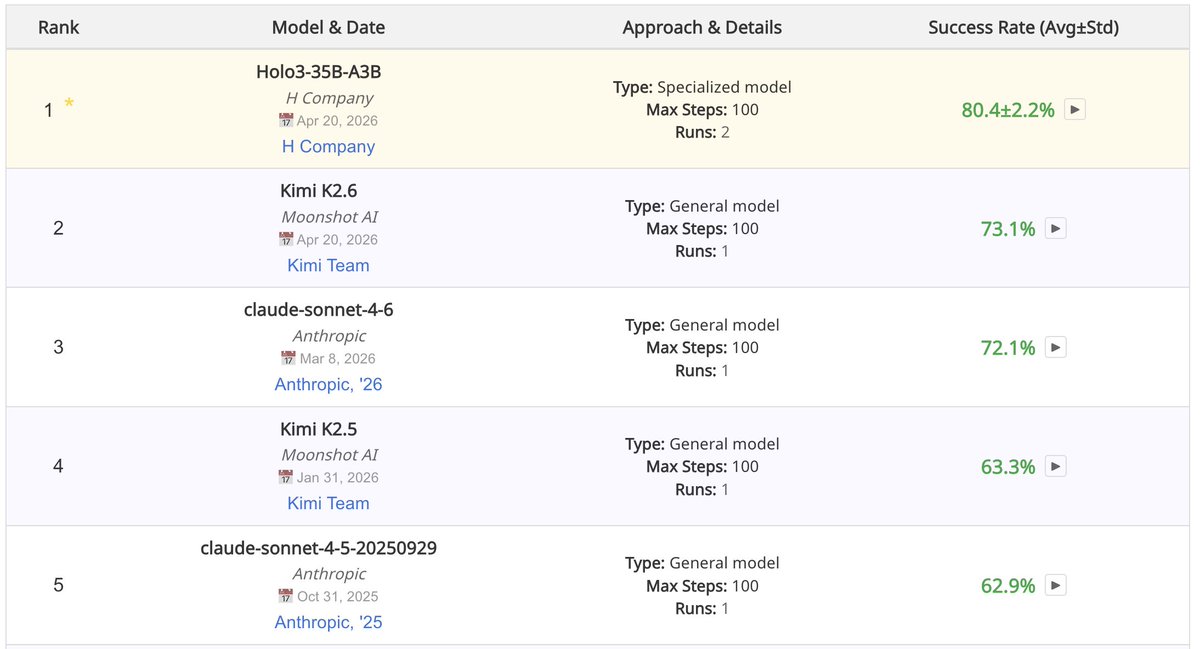
When it comes to computer-use, 80 is the new 70.
Today, we broke a new barrier on the OS-World benchmark with an 80.4% success rate. Holo3 is officially #1 globally for computer-use agents, and it's not even close. 🏅
👉 See for yourself: https://t.co/jTUnRY3nYr
A massive congratulations to the whole team. They set a high standard with chart topping results two weeks ago and continue to raise the bar.
PyLO is accepted to MLSys 2026! 🎉🚀
A PyTorch-native library bringing SOTA learned optimizers to the codebases most of us actually use — with fast CUDA kernels and real speedups on large-scale training. Drop-in ready, no more JAX-only barriers.
Library: https://t.co/NTjBF64jD3
Excited to launch the accompanying free RLHF Course for my book. To kick it off, I've released:
- Welcome video
- Lecture 1: Overview of RLHF & Post-training
- Lecture 2: IFT, Reward Models, Rejection Sampling
- Lecture 3: RL Math
- Lecture 4: RL Implementation
I'm going to add question & answer videos throughout the lecture to go deeper on topics that need it, and potentially cover some topics that are too recent and in flux to go in print. I expect 10-15 videos in total over the next few months.
At the same time, development around the code for the book is picking up. It's a great time to build the foundation for post-training methods.
YT playlist and course landing page below.
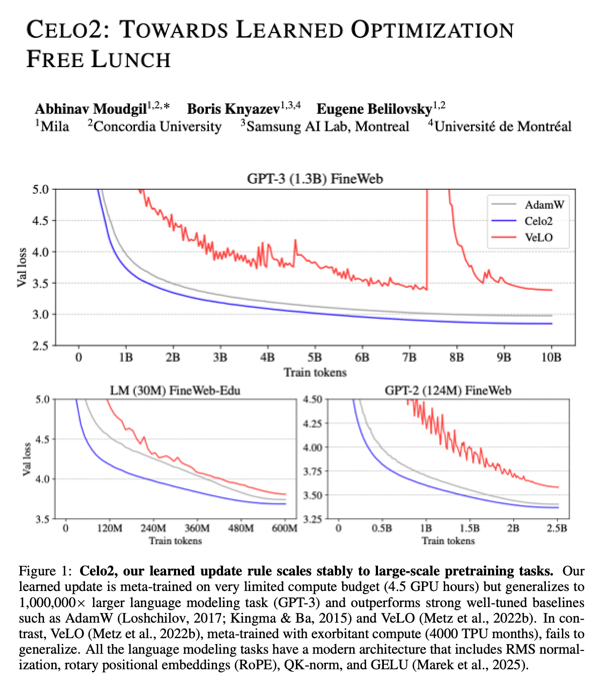
Introducing Celo2: Towards Learned Optimization Free Lunch
We show that learned optimizers can generalize to practical tasks like GPT-3 1.3B pretraining and several out-of-distribution vision/RL tasks from limited meta-training (~4.5 GPU hours)!
🧵
I wrote a blog post on my experience using AI for slide generation Basic idea: write your lecture notes first, then prompt the LLM to produce corresponding slides in reveal.js (h/t @ChenhaoTan). I'm picky about my slides but was happy with the results!
(link in thread below)
We’re seeing lots of interest in how Cursor delivered Composer 2. One less obvious insight: you don't need to spend billions on a giant cluster to do reinforcement learning.
With disaggregated sampling, we ran @Cursor_ai Composer 2 training across 3-4 clusters worldwide, with a unified capacity of Fireworks Virtual Cloud.
Check how we optimize cross-region 1TB+ model updates by 98%+ while keeping staleness under a few minutes: https://t.co/0Ziv6ssFNx
Running experiments and editing code with Claude Code is so enjoyable that it's negatively affecting my sleep, it's like "just one more turn" when playing Civilization.