Writing Agentic Coding Weekly newsletter to help you stay fully informed about agentic coding with one email, once a week. Formerly ML Engineer at Mercari.
Gave my first ever tech talk last Friday at PyCon APAC 2023. Was a bit nervous but overall it turned out great. Definitely would do it again.
Talk video: https://t.co/MQd0laeh4Z
Slides: https://t.co/thrVAnx2qk
PSA: if you find this annoying as well, you just need to add following in the ~/.claude/settings.json file:
```
"attribution": {"commit": "", "pr": ""}
```
Claude Code automatically adds itself to the commit metadata "Co-Authored-By: Claude Opus <[email protected]>".
I strongly disagree with crediting Claude as a commit co-author. It is a tool I'm paying for, not a copyright holder, not an author. We don't credit Visual Studio.
Added a couple of quick utilities to my terminal which uses local speech-to-text with Pi coding agent to solve the problem of writing complex command like
find largest files in the current directory:
`find . -maxdepth 1 -type f -exec du -h {} + | sort -rh | head -n 5`
- comma command: I type `,` , hit Enter, start saying what I want the command to do and get the shell command I can execute
- question command: I type `q`, hit Enter, say my question aloud, and Pi answers my question with my configured LLM and can read and search for files
Zai has released GLM-5.2
extends the context window from 200K to 1M tokens and adds High/Max thinking-effort controls
scores 81.0% on Terminal-Bench 2.1 and 62.1% on SWE-bench Pro
Issue 24 is out, covering agentic coding updates from last week:
Claude Fable 5 & Mythos 5 access pulled by US government, Kimi K2.7 Code, GLM-5.2, MiMo V2.5 Pro UltraSpeed, and MiMo code
Read it in your inbox!
Anthropic has released Claude Fable 5, a new "Mythos-class" model that sits above the Opus tier
On agentic coding it scores 80.3% on SWE-bench Pro, ahead of the Mythos Preview model (77.8%), Opus 4.8 (69.2%), GPT-5.5 (58.6%), and Gemini 3.1 Pro (54.2%)
@lucasmeijer I am big fan of VoiceInk which is also local and open-source
I also maintain this list of all the best open-source ones in this awesome-style GitHub repo. Hope you find something that works for you here:
https://t.co/6GyB1eqAkp
Issue 23 is out, covering agentic coding updates from last week:
MiniMax M3, Nemotron 3 Ultra, Qwen 3.7 Plus, Open Code Review, GitHub Copilot Desktop, and Uber's $1,500/month AI limit
Read it in your inbox!
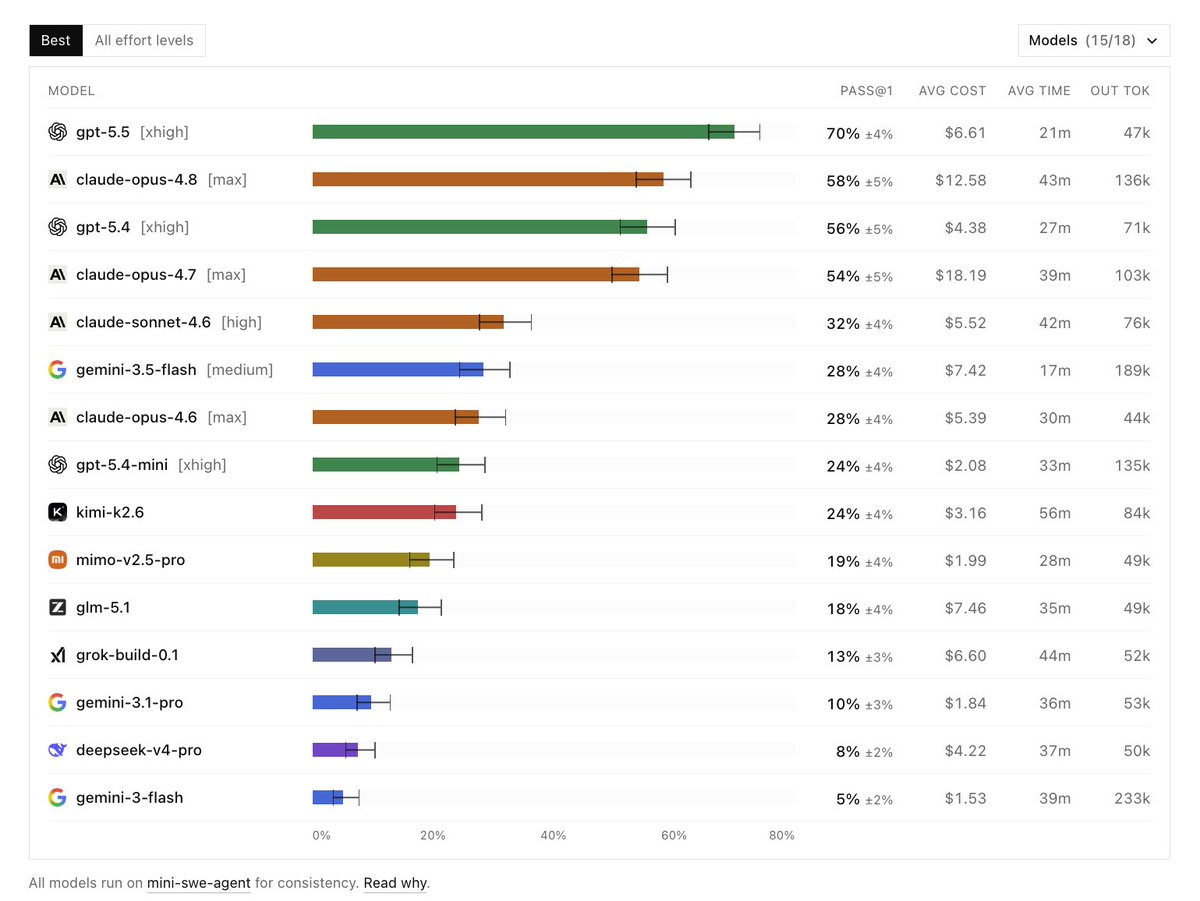
Because of the limited number of samples and limitations of the harness, I'd say it's not the ultimate benchmark for picking your day-to-day agentic coding tools and models just yet
DeepSWE Benchmark: Let's look into what it is first and then where it falls short
This is a benchmark for:
- longer-horizon tasks compared to SWE-Bench Pro
- tasks have a higher diversity and are contamination-free