I just spent months handwriting a 200 page guide on the entirety of ML foundations and math from scratch.
The guide features:
- Neural Nets (Backprop, Adam, SGD, Batch Norm)
- ML Algorithms (SVM, Grad Boosting, K-means, PCA)
- Hardware (Tensor Cores, Systolic Arrays, CUDA)
- Transformers (Multi-Head Attn, KV Cache, LoRA)
- Vision (ViT, Convolutions, MAE, IoU, NMS, VLM)
- Agents (OpenClaw, ReAct, Memory, Orchestration)
Everything I wish I had years ago, for free.
1. Blackwell (and to some extent hopper) is insanely powerful. Understanding all its features itself is hard
2. GPU programming, no matter which DSL thingy you picked, still depends on compilers
3. A lot of optimization is probably done when designing the kernel. after that,
All these fucking dorks at Anthropic do is yap about how insane their product is and how end-of-the-world it will be
Someone tell these jabronis to shut the fuck up, holy Christ they're so annoying
anthropic blog was quite pragmatic.
as an human, you have got 3 comparative advantages which will matter the most (at least for now!)
> research taste and judgement (choosing which problems matter)
> which results to trust
> when an approach is dead end.
Read this to get started learning ML infra.
This is an excellent high-level overview of important considerations in ML training from CMU. It touches on:
- hardware
- memory
- the ML experimentation process
https://t.co/RTWm0Ecni1
Interested in learning how to run RL at scale? Here are the best resources to read…
Research on Scaling RL
1. The Art of Scaling RL compute for LLMs: https://t.co/PGjI6Gwgv0
2. Scaling Behaviors of LLM RL Post-Training: https://t.co/2u2saB3C0h
3. Optimally Scaling Sampling Compute for LLM RL: https://t.co/rUSdUvJyNH
4. Scaling up RL: https://t.co/O8vV6z8ymx
5. ProRL V2 - Prolonged Training Validates RL Scaling Laws: https://t.co/vu72juvRW4
6. Polaris - A Recipe for Scaling RL with Reasoning Models: https://t.co/rMibSAeJbg
RL Frameworks
1. Hybrid Flow (early outline of the verl framework): https://t.co/GnWXx131uD
a. More up-to-date info can be found here: https://t.co/j801HcJmPP
2. AReal - Large-Scale Async RL: https://t.co/qhOvsQK09N
3. PipelineRL - Fast On-Policy RL: https://t.co/iRM7KzySXe
4. AsyncFlow - Async Streaming RL: https://t.co/YwmzFtiU2q
RL for Agents
1. DeepSWE - Open Coding Agent Trained w/ RL: https://t.co/GHQHcmtE6F
2. AutoForge - Environment Synthesis for Agentic RL: https://t.co/mr3WDIL5vq
3. Agent-R1 - Training Agents w/ End-to-End RL: https://t.co/xpfQJGgzEv
4. AgentRL - Scaling RL for Multi-Turn, Multi-Task Agents: https://t.co/7fbVl0RWXG
5. The Landscape of Agentic RL: https://t.co/OMnSV4rgdW
6. Training SWE Agents with RL: https://t.co/YqMqySbyXS
Case Studies & Tech Reports
1. Kimi tech reports:
a. Kimi K2 - Open Agentic Intelligence: https://t.co/aAw17SXrIw
b. Kimi End-to-end Agentic RL: https://t.co/ProBpOPIiI
c. Kimi K1.5 - Scaling RL for LLMs: https://t.co/kRGOxY9Jvp
2. Composer series from Cursor:
a. Composer 2: https://t.co/K0v8rNCE6Z
b. Composer 2.5: https://t.co/D9PYimfOMU
3. Olmo 3 (also has open code / data): https://t.co/khetJFvp6N
4. MiniMax tech reports:
a. MiniMax-M2: https://t.co/HApb0OB80S
b. MiniMax-M1: https://t.co/mZj9UQsrnC
5. Nemotron 3 (NVIDIA): https://t.co/lCpE1GzxSi
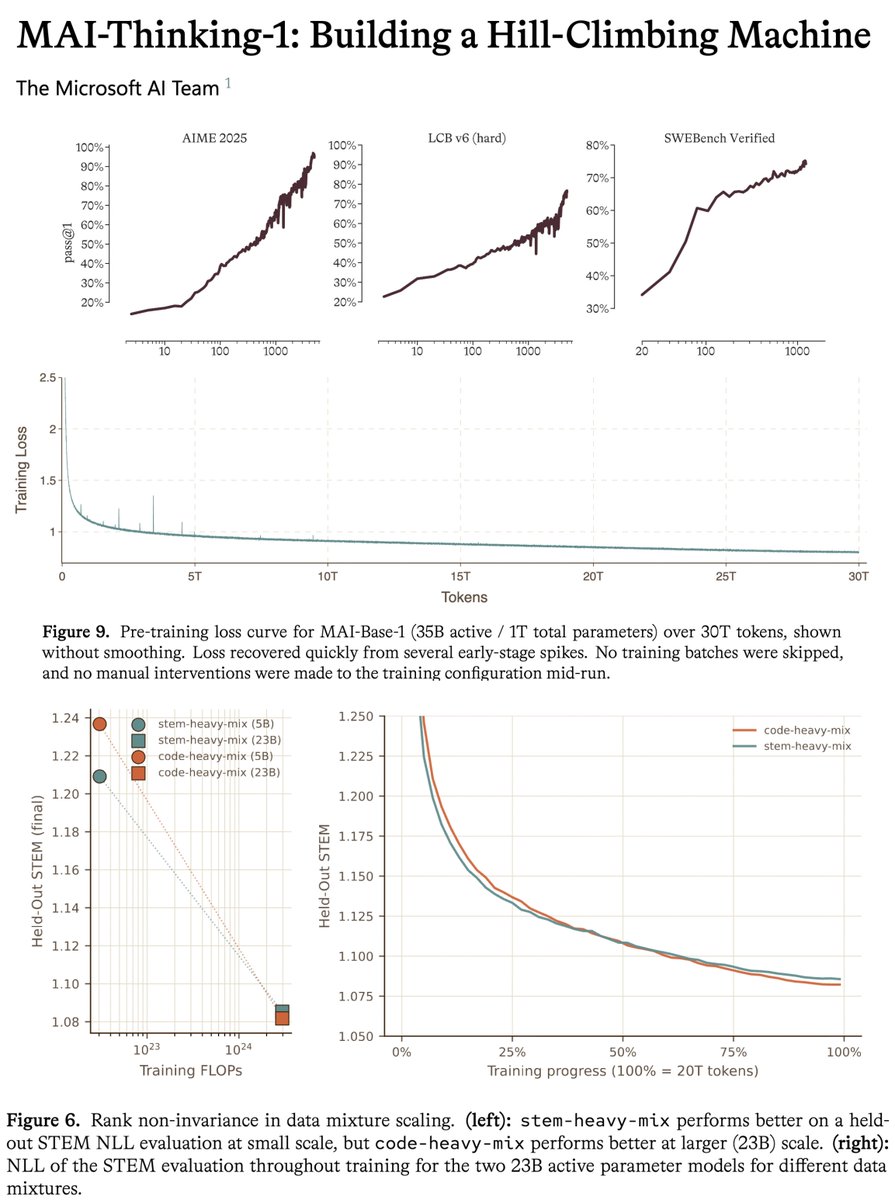
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
New devlog post from yours truly: When does fragmentation occur in the CUDA caching allocator? https://t.co/ocAdv4mjy2 -- this post is LLM authored but I heavily prompted/edited, and Natalia also helped fact check.
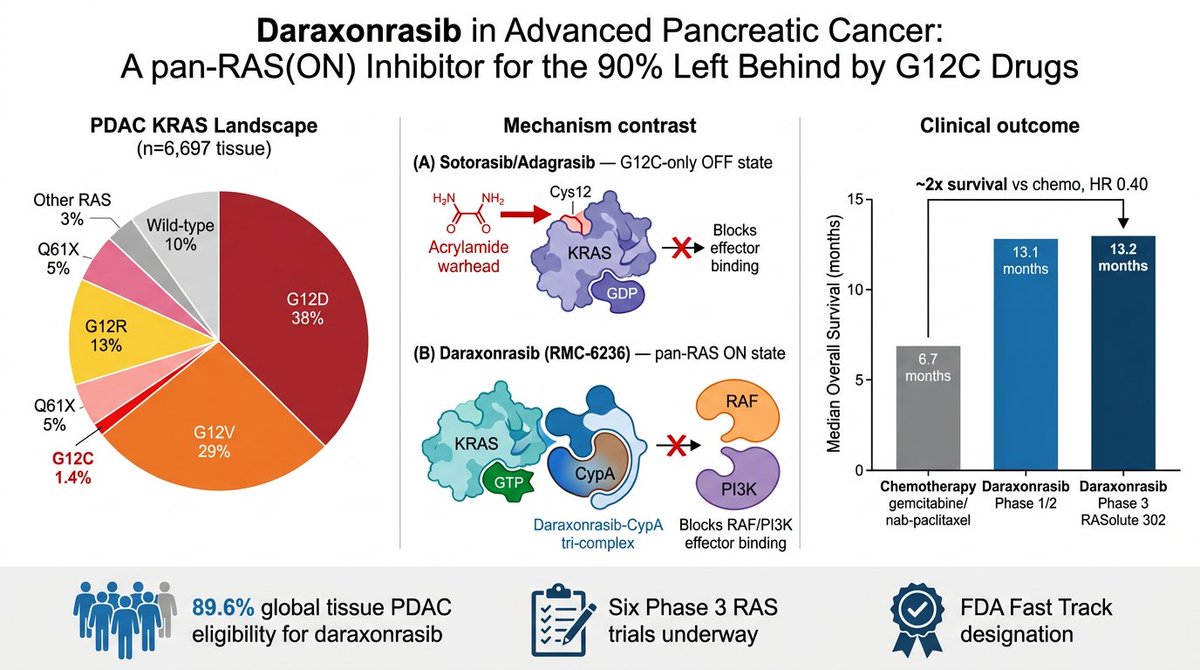
RAS finally getting drugged is one of the great stories in modern biology, and almost nobody outside oncology understands why it's such a big deal.
YOU'LL LEARN SOMETHING AWESOME TODAY.
i am going to keep this as understandable (and simple) as i can.
OPEN THE THREAD.
🧵
Cheers, chills, and a standing ovation when RASolute 302 showed unprecedented survival on daraxonrasib for patients with progressive pancreatic cancer
Seldom do you sense you’re witnessing a historic moment in cancer care but this feels like ras targeting has arrived
#ASCO26