Pierwszy Gość Specjalny w AI Ninjas: Kuba Masztalski, @proAutomator
25.02, 19:00 – warsztat na żywo: scraping danych z Make/n8n i Claude Code
Zamknięty warsztat dla członków Dojo:
→ https://t.co/TOMh2AuAuY
I support @tailwindcss.
@adamwathan, I have been using Tailwind CSS since the beginning and have owned multiple licenses for Tailwind UI. I deeply respect your work and the efforts of your team.
I just purchased Tailwind Plus to say thank you. I hope you find a new business model that helps you continue your work in the Generative AI era.
Take care, brother.
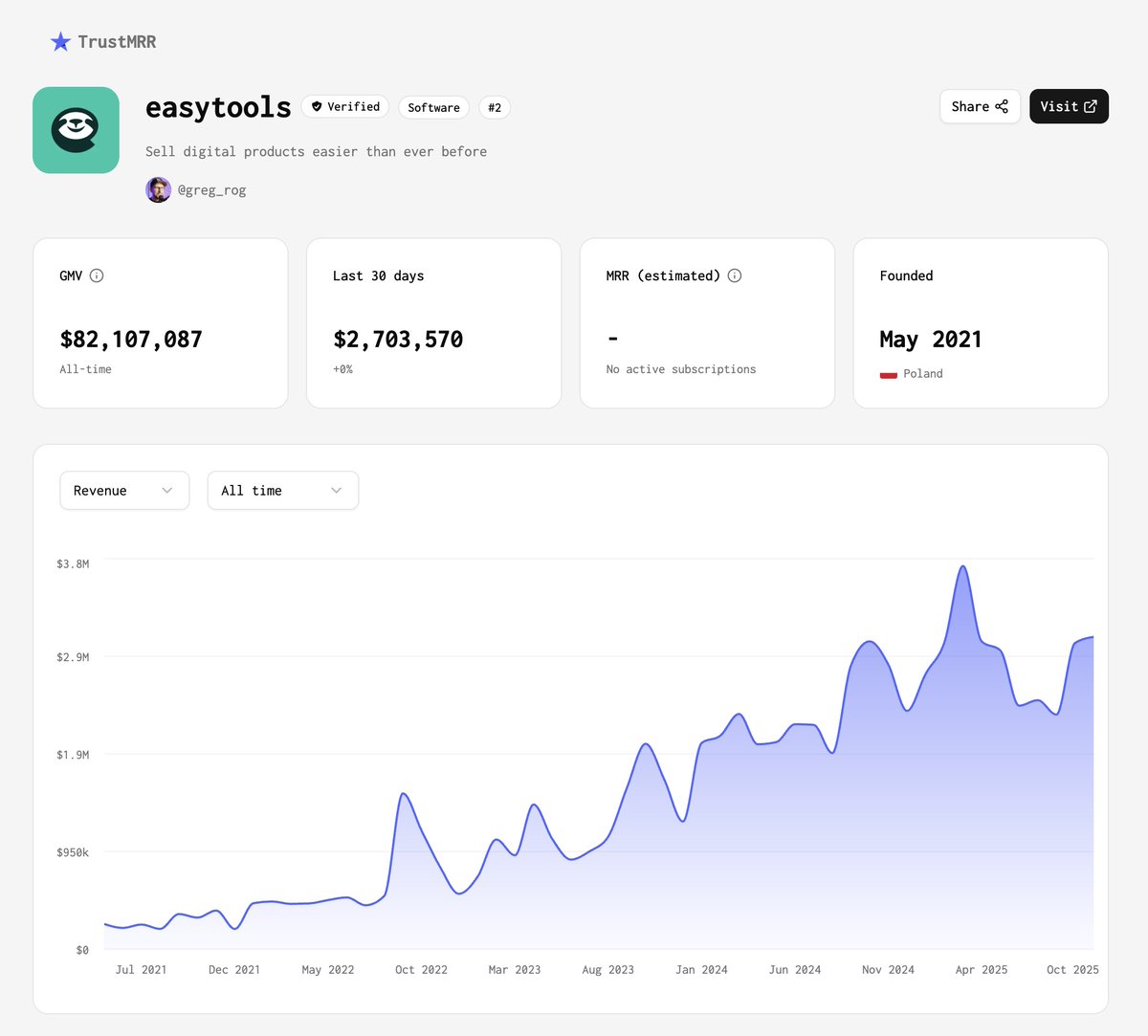
New startup claims the #2 spot on TrustMRR 🥈
It's a platform created by @greg_rog for selling digital products online (note: the $82M figure is GMV, not revenue).
Their ecosystem includes a range of beautiful products and free tools, with top-notch design imho. Check out their footer to explore the entire easy**** ecosystem.
Custom MCP vs Official One – @linear
I’m a big fan of Linear, and for months I have been using it through my AI Agent via a custom integration. When the official MCP was released, I installed it and found it to be good, but since it had some issues, I decided to build my own and share it as open source (link in the comment).
— the main rule here is:
API/GraphQL is for programmers and code. MCP tools are for LLMs, AI workflows, and agents.
— what I did differently and why?
- many tools feel flexible, but it’s noise. I merged things like TeamID, AssigneeID, LabelID into a single "workspace_metadata" tool. The LLM decides which to fetch.
- instructions, tool descriptions, and schema props are rich but concise, so there’s less guessing.
- responses aren’t plain JSON. They say exactly what happened, list changes, give soft suggestions, and help recover from errors. Readable for humans too.
- instead of "add_issue" I use "add_issues" for batch requests. Fewer calls, less context noise. For issue listing, default range is -7 / +7 days.
- I prefetch related values, like returning both a status ID and its name, so the LLM can match natural text.
- I hide tools when they’re not relevant, like skipping "cycles_list" if cycles are disabled in all teams.
- "assigneeId" defaults to the current user unless told otherwise.
- schemas match workspace settings, such as formats of the "priority" property.
^ all these points focus on reducing context noise, minimizing the number of steps, lowering the required tokens, increasing speed, and reducing costs.
below, you can see the difference in performing the exact same task, allowing you to compare the number of steps required to complete it.
and to be clear, I'm not saying that the Official Linear MCP is bad, as it is still under development and in a very early stage. -- I’m sharing this so you can look at the source code, which you can discuss with Cursor or Claude Code.
There’s a chance you might find something valuable there that could help you design your own MCPs.
Note: You can easily run this server locally using a Linear API key or OAuth with @Cloudflare Workers.
Feedback is welcome, as I clearly do not know everything about LLMs and MCP. Thank you in advance for sharing.
"How to design a good MCP server?"
This is the question many of you have asked me, so I decided to open-source the MCPs I use, starting with the @Spotify Streamable Server, which you can use in Claude (@AnthropicAI) or any other client.
— why Spotify?
because I use voice interfaces a lot and I love music and Spotify has an API.
— what makes a good MCP Server?
many say MCP is just a wrapper for an API that often maps one-to-one the endpoints you already have to the tools the LLM uses. I believe that is wrong because an API is designed for a programmer, while tools must be designed for an LLM that does not have access to the source code or documentation when using them.
— this is why this MCP Server does the following:
- It has carefully designed instructions and property descriptions.
- It provides human-friendly responses that do not overload the LLM's context with unnecessary information.
- It uses batches to reduce the number of steps the LLM needs to take, such as search queries.
- It enriches results, for example, by double-checking Spotify playback to ensure the given track is playing.
- It uses not only IDs and URIs but also the actual names of tracks, artists, and playlists to make them clear for the LLM.
- It gently guides the LLM with instructions on how to use the results.
- It provides clear error messages, reducing Spotify-API-specific jargon that may be unfamiliar to smaller LLMs.
^ all this increases the chances of getting the results you actually want by taking as much of the burden off the LLM as possible.
I hope that using this MCP and discussing its source code with the LLM will help you understand the Model Context Protocol and what is important when designing your own servers.
Note: The Auth Server embedded in this server is intended for private use and is not suitable for production.
Feedback is welcome, as I clearly do not know everything about LLMs and MCP. Thank you in advance for sharing.
CC: @MCP_Community
@JakubNorkiewicz Ja tam uważam, że dalej będziemy oglądać aktorów 😀 Stawiam na to, że ludzie wolą oglądać znane twarze w roli historycznych postaci, jak Mela Gibsona jako Williama Wallace'a, niż wierniej odwzorowane, ale mniej znane szerszej publice twarze 🤷♂️