A lot of thought goes into designing harnesses, algorithms, objectives, etc. for parallel test-time compute and GRPO-style policy gradients for LLMs. Sampling is usually an afterthought: just use a bunch of independent rollouts.
However, this misses out on a rich design space of non-iid samplers, particularly from Quasi-Monte Carlo methods. You can think of these as choosing a joint distribution on [0,1]^k such that each sample is marginally uniform, but the k samples collectively cover [0,1] better than iid.
In QuasiMoTTo, we revisit these classic ideas, showing how they fit into the age of LLM test-time compute (pass@k, online RL). On tasks like Maze/Sudoku, swapping out iid sampling with QMC accelerates RL training (by lowering the fraction of zero-variance groups) and even saturates an upper bound on pass@k.
The idea of coordinating a group of rollouts by simply sharing the sampling noise is really elegant IMO, and there's lots of potential directions to take this idea. Super fun working on this project with @michaelyli_ !
Also stay tuned for the codebase dropping in a few days🫡
You're wasting FLOPs when scaling inference compute: by independently sampling parallel attempts, you burn compute rediscovering the same solutions.
Introducing QuasiMoTTo: we scale parallel sampling with correlated samples instead! These samples have higher coverage, are marginally exact draws from the LLM, and can be generated in parallel.
Result: same performance with 25-47% fewer samples in test-time scaling + 50% fewer training steps in RL!
In our new paper, we explore the design space of correlated samplers. Work with co-authors @probablynotaz9 (co-lead), @gandhikanishk, @noahdgoodman, and Emily Fox!
You're wasting FLOPs when scaling inference compute: by independently sampling parallel attempts, you burn compute rediscovering the same solutions.
Introducing QuasiMoTTo: we scale parallel sampling with correlated samples instead! These samples have higher coverage, are marginally exact draws from the LLM, and can be generated in parallel.
Result: same performance with 25-47% fewer samples in test-time scaling + 50% fewer training steps in RL!
In our new paper, we explore the design space of correlated samplers. Work with co-authors @probablynotaz9 (co-lead), @gandhikanishk, @noahdgoodman, and Emily Fox!
Excited to present this at ICML next week! ✈️🇰🇷
I'll be there in person from Monday to Friday. If you're also in Seoul and interested in RL/diffusion or more generally LLM post-training/inference, let's chat :)
🚨 Solo-author ICML paper alert 🤫
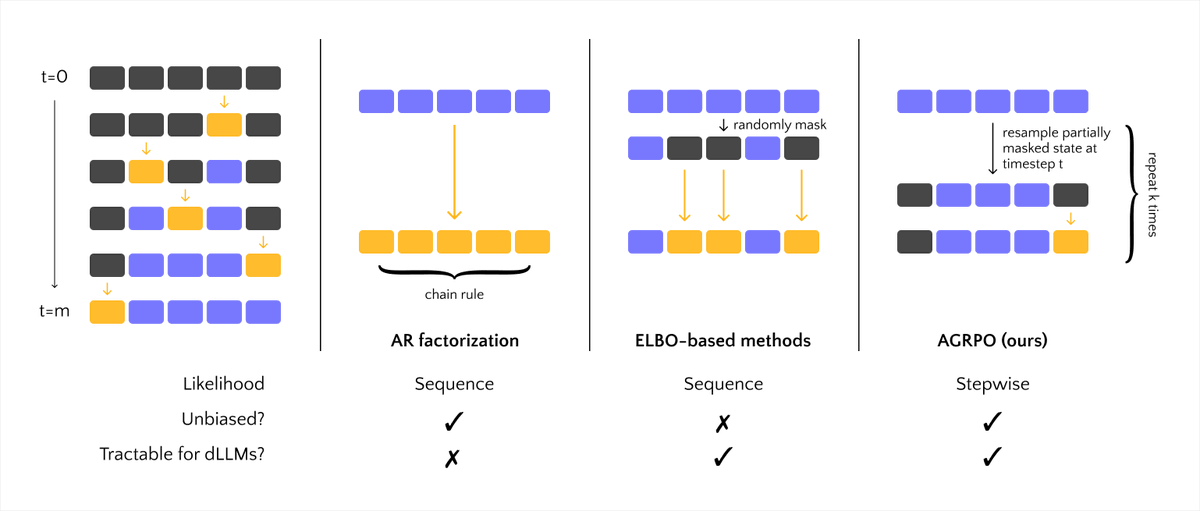
Ever wanted to post-train your diffusion LLM with good old policy gradients, without having to deal with ELBOs or surrogates?
In Simple Policy Gradients for Reasoning with Diffusion Language Models, we show how to make this tractable in a straightforward way.
Our framework, Amortized GRPO (AGRPO), lets the model learn from unbiased PG updates via timestep estimation, naturally aligning with dLLM inference while remaining efficient + scalable.
Paper: https://t.co/nrG2bjgrZ7
Code: https://t.co/BJ5Kh02NVt
1/n
Check out the full paper for more details, like variance reduction with entropy importance sampling and GPU memory optimizations.
Shoutout to @jiaqihan99, @aaron_lou, and @michaelyli__ for valuable feedback during the early stages, @therealgabeguo and @StefanoErmon for supporting this project throughout, as well as @modal for sponsoring compute!
6/n
🚨 Solo-author ICML paper alert 🤫
Ever wanted to post-train your diffusion LLM with good old policy gradients, without having to deal with ELBOs or surrogates?
In Simple Policy Gradients for Reasoning with Diffusion Language Models, we show how to make this tractable in a straightforward way.
Our framework, Amortized GRPO (AGRPO), lets the model learn from unbiased PG updates via timestep estimation, naturally aligning with dLLM inference while remaining efficient + scalable.
Paper: https://t.co/nrG2bjgrZ7
Code: https://t.co/BJ5Kh02NVt
1/n
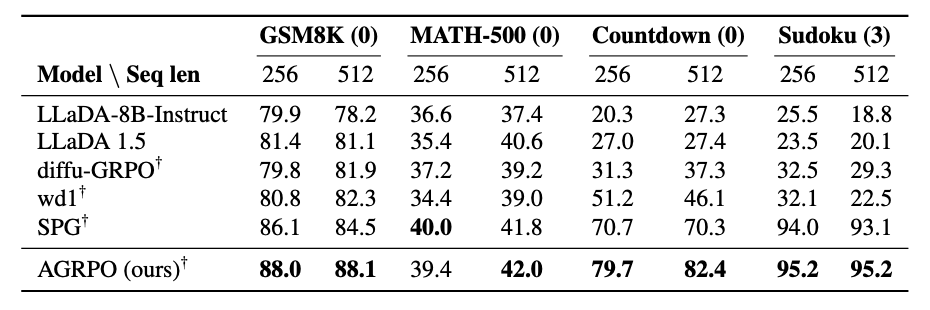
Empirically, with only k=24 MC samples, AGRPO surpasses every comparable ELBO-based RL method across four reasoning tasks: GSM8K, MATH, Countdown, and Sudoku. These gains persist even for different context lengths and # of denoising steps (m) than what the model was trained on.
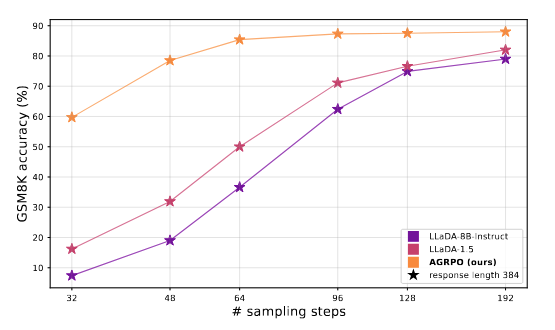
A neat dLLM-specific result is that post-training completely changes the inference speed/quality frontier: AGRPO lets you achieve the same quality as the base LLaDA model with 4x fewer steps.
In the real world, if you're serving a model to users, this would let you drastically cut inference costs by amortizing that cost into training.
5/n
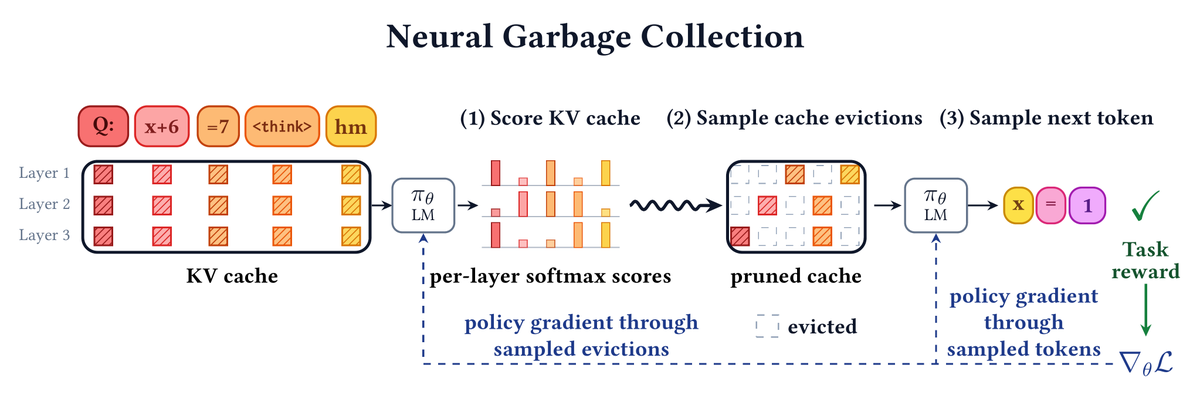
Can a language model learn, end-to-end, what to keep in its own KV cache and what to throw away? Can it learn to forget while it learns to reason?
Deep learning's central lesson: capability emerges from end-to-end optimization, not heuristics/strong inductive biases. But for efficiency, we rely heavily on hand-designed approaches.
🗑️ Introducing Neural Garbage Collection (NGC): we train a language model to jointly reason and manage its own KV cache, using reinforcement learning with outcome-based task reward alone. No SFT, no proxy objectives, no summarization in natural language.
New paper with @jubayer_hamid, Emily Fox, and @noahdgoodman!