Enquanto a maioria dos usuários passa o dia inteiro digitando prompts em uma janela de chat, engenheiros da Anthropic já estão pensando uma etapa à frente.
A mensagem é simples: pare de dar ordens para a IA. Construa um sistema capaz de dar ordens para si mesmo.
Segundo um engenheiro da Anthropic, o maior erro dos usuários do Claude é tratar a ferramenta como um chatbot, quando ela foi projetada para funcionar como uma equipe completa de especialistas.
O vídeo revela detalhes que passam despercebidos para quase todo mundo:
• O CLAUDE.md pode definir até 14% do desempenho antes mesmo da primeira mensagem.
• Plugins e servidores MCP ampliam capacidades que a maioria dos usuários sequer explora.
• Configurações de cache podem manter taxas de acerto próximas de 95%, reduzindo drasticamente custos.
• Reiniciar conversas do zero desperdiça contexto, memória operacional e produtividade.
A demonstração vai além da teoria.
Um único operador cria agentes especializados para atuar como gerente de produto, designer, engenheiro de software, especialista em segurança e analista de dados. Cada agente recebe uma função específica, trabalha em paralelo e entrega resultados coordenados.
O conceito muda completamente a lógica de uso da inteligência artificial.
Não se trata mais de perguntar e esperar respostas.
Trata-se de construir sistemas autônomos capazes de planejar, executar, revisar, corrigir erros, testar, implantar aplicações e gerar análises sem intervenção constante do usuário.
A diferença entre um usuário comum e um usuário avançado não está no prompt.
Está na arquitetura.
Quem ainda usa apenas a janela de chat está contratando um funcionário.
Quem domina agentes, memória, MCPs, cache e contexto persistente está operando uma empresa inteira.
Oi @ClaroBrasil, eu estou recebendo cobranças diariamente no meu e-mail do remetente [email protected]. Gostaria de saber se esse e-mail é mesmo de vocês, e como faço para não receber essas cobranças que são para uma pessoa com nome bem parecido com o meu.
Eu depois de aprender com o time da Anthropic como fazer agentes que trabalham por horas sem dormir no ponto.
O vídeo legendado tá logo abaixo.
Salva e comenta se foi útil.
Esse CEO demitiu 22% da empresa no MELHOR trimestre da história.
E ofereceu $1 milhão de dólares de salário para quem ficou.
Zeb Evans, CEO da ClickUp, publicou ontem um post de 1.500 palavras redesenhando como a empresa funciona. Não é um post de "decisão difícil". É um manifesto operacional.
O argumento central destrói o consenso da indústria:
→ IA não torna todo mundo mais produtivo. Torna os melhores 100x mais produtivos e transforma o resto em gargalo.
→ Empresas celebrando "500% mais pull requests" estão medindo volume de código. Resultado para o cliente não acompanha sempre.
→ Os melhores engenheiros pararam de escrever código. Agora orquestram agentes de IA e revisam output. O que importa é julgamento.
Evans chama isso de "o grande acerto de contas do AI coding" e diz que toda empresa vai enfrentar isso em breve.
Mas a parte que mais repercutiu foi compensação.
ClickUp vai introduzir bandas salariais de $1 milhão de dólares por ano em cash. Qualquer cargo. Engenheiro, PM, designer.
A condição: demonstrar impacto 100x criando ou gerenciando sistemas de IA.
A conta fecha. Se uma pessoa com IA entrega o que antes exigia 10, o capital dos 9 que saíram pode ir para ela.
Cargos que não existiam há 12 meses estão surgindo. "Agent Managers": pessoas que automatizaram o próprio trabalho e agora gerenciam os sistemas de IA que fizeram isso possível. Quem se automatizou, ficou. Quem resistiu, saiu.
Toda empresa de tech vai ter que responder uma pergunta nos próximos 18 meses:
Reestrutura agora ou perde seus melhores talentos para quem já reestruturou?
A era do headcount como métrica de força acabou ontem à noite.
Here’s a more engaging version:
He spent 50 years teaching at MIT.
Near the end of his life, he gave one final lecture.
One hour.
No fluff. No performance.
Just a lifetime of knowledge compressed into a talk that still feels impossible to ignore.
Five months later, he was gone.
This is that lecture.
Watch it once.
You may think about life, work, and learning differently after.
Bookmark it for later 👇
Instead of watching an hour of Netflix, watch this 2-hour Stanford lecture on AI careers. It will teach you more about winning in the AI race than all the AI content you’ve scrolled past this year.
MIT published 12 AI textbooks written by the top researchers who built the field.
These are not just books these are primary source material behind the world top AI ChatGPT, Claude, Gemini... (save this!)
1. Foundations of Machine Learning https://t.co/cyIHr6qm2z
2. Understanding Deep Learning https://t.co/5XUo4bPHRu
3. Machine Learning Systems https://t.co/l5bCCyXSV0
4. Algorithms for Decision Making https://t.co/1ZNU1XvSYK
5. Deep Learning https://t.co/JAo52d4JTI
6. Reinforcement Learning: An Introduction https://t.co/0XqopIY5CR
7. Distributional Reinforcement Learning https://t.co/z7bqEUK2ky
8. Multi-Agent Reinforcement Learning https://t.co/KgOtpxXAUc
9. Algorithms for Decision Making (Long Game) https://t.co/F6J9Za0igV
10. Fairness and Machine Learning https://t.co/r9egFAY6tL
11. Probabilistic Machine Learning: An Introduction https://t.co/xmmj7Ev7Of
12. Probabilistic Machine Learning: Advanced Topics https://t.co/6lUCb9blt8
I hope you found this helpful,
For more such useful resources you can follow me @ZabihullahAtal
AI agents are systems, not single models. 🤖🏗️
To build production-ready agents, you need the right stack:
🧠 GPT/LRM – For reasoning & complex planning
⚡ MoE/SLM – For scale, speed & cost-efficiency
👁️ VLM – To "see" UI, diagrams & screenshots
🛠️ LAM – To take real-world actions via APIs
Master the agentic stack in our FREE AI Agents Program! 🚀
🔗 Join here: https://t.co/p6Je0puq6L
BREAKING: AI can now analyze any stock like a Wall Street analyst (for free).
Here are 10 insane Claude prompts that replace $2,000/month Bloomberg terminals:(Save for later)
Google just dropped another banger!
the figures in this paper were drawn by the system described in the paper.
PaperBanana is an agentic framework that generates publication-ready academic illustrations from methodology descriptions.
no manual design, no Figma, just your method section and a caption.
here's how it works:
five specialized agents collaborate in sequence:
> Retriever: finds relevant reference diagrams from a curated set of NeurIPS papers. matches by visual structure, not topic.
> Planner: translates your methodology text into a detailed visual description using in-context learning.
> Stylist: applies aesthetic guidelines (color palettes, typography, layout) auto-summarized from hundreds of top-tier papers.
> Visualizer + Critic loop: generates the image, critiques it against source text, and refines. repeats for 3 rounds.
one surprising finding: randomly selected examples work nearly as well as semantically matched ones. what matters is showing the model what good diagrams look like, not finding the topically perfect reference.
in blind evaluations, humans preferred PaperBanana outputs nearly 3 out of 4 times.
it also extends to statistical plots using code-based generation for numerical precision.
link in the next tweet.
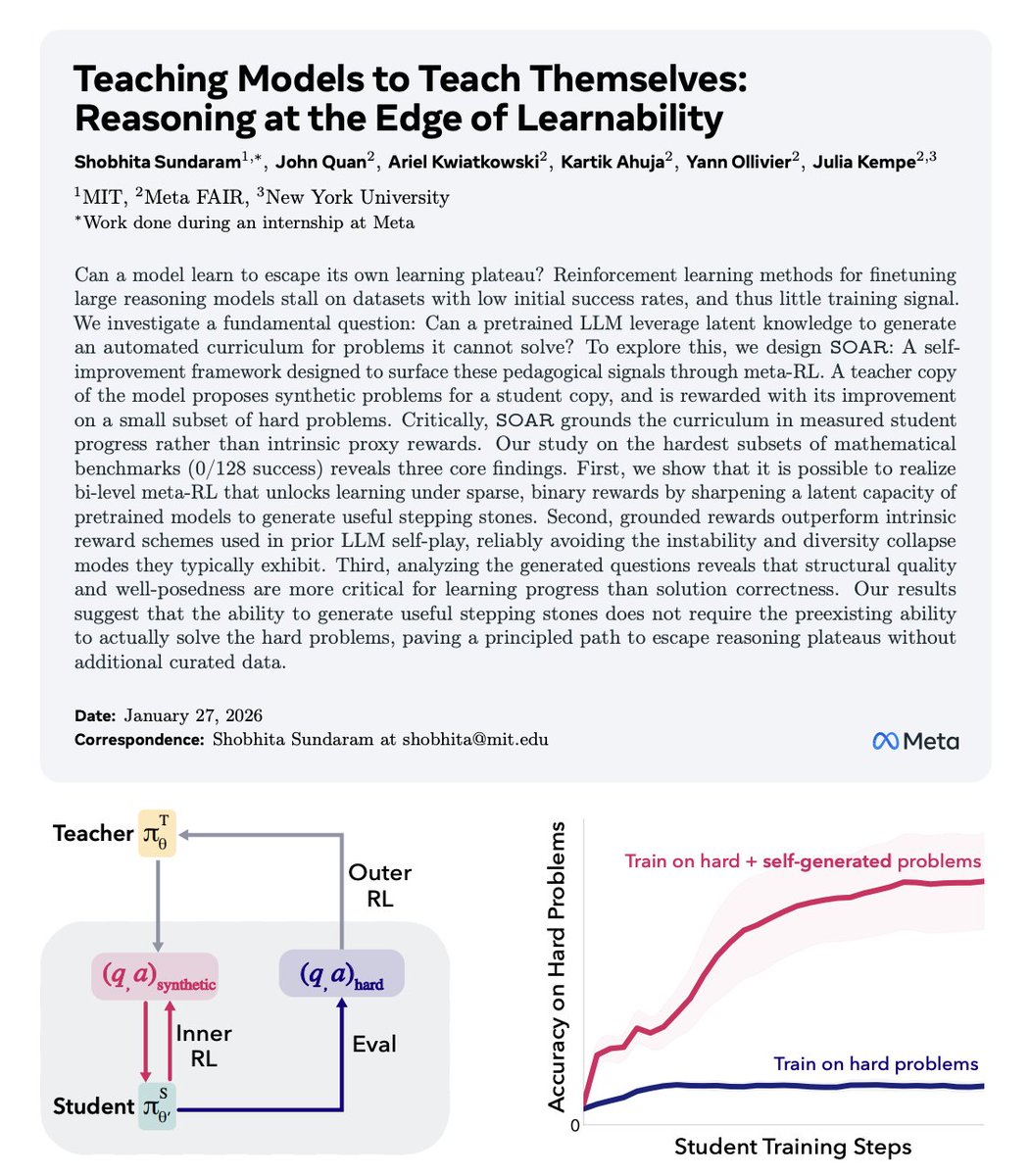
MIT just published a paper that quietly explains why LLM reasoning hits a wall and how to push past it.
The usual story is that models fail on hard problems because they lack scale, data, or intelligence.
This paper argues something much more structural: models stop improving because the learning signal disappears. Once a task becomes too difficult, success rates collapse toward zero, reinforcement learning has nothing to optimize, and reasoning stagnates. The failure isn’t cognitive, it’s pedagogical.
The authors propose a simple but radical reframing. Instead of asking how to make models solve harder problems, they ask how models can generate problems that teach them.
Their system, SOAR, splits a single pretrained model into two roles: a student that attempts extremely hard target tasks, and a teacher that generates new training problems. The catch is that the teacher is not rewarded for producing clever or realistic questions. It is rewarded only if the student’s performance improves on a fixed set of real evaluation problems. No improvement means zero reward.
That incentive reshapes everything.
The teacher learns to generate intermediate, stepping-stone problems that sit just inside the student’s current capability boundary. These problems are not simplified versions of the target task, and strikingly, they do not even require correct solutions.
What matters is that their structure forces the student to practice the right kind of reasoning, allowing gradient signal to emerge even when direct supervision fails.
The experimental results make the point painfully clear. On benchmarks where models start with zero success and standard reinforcement learning completely flatlines, SOAR breaks the deadlock and steadily improves performance.
The model escapes the edge of learnability not by thinking harder, but by constructing a better learning environment for itself.
The deeper implication is uncomfortable. Many supposed “reasoning limits” may not be limits of intelligence at all. They are artifacts of training setups that assume the world provides learnable problems for free.
This paper suggests that if models can shape their own curriculum, reasoning plateaus become engineering problems, not fundamental barriers.
No new architectures, no extra human data, no larger models. Just a shift in what we reward: learning progress instead of answers.
80+ tools every solo entrepreneur should know. From automating research to building AI apps, this stack covers everything you need to work smarter, not harder.
No-code, low-code, and powerful AI-backed platforms tailored for lean teams and one-person startups. Built to save time, scale faster, and simplify your entire workflow.
Perfect for those wearing every hat, from product to content to strategy.
#AnalyticsVidhya #AITools