OnSIDES v3.1.1 is out! 🎉
Updated with drug labels through April 2026 from all four sources (US, UK, EU, Japan):
- 41K+ product labels
- 6.9M drug–adverse event pairs
- 4,097 ingredients
Also fixes some bugs — if you're using that., please upgrade.
https://t.co/piDXM7ovRn
It's time again for the AMIA Translational Bioinformatics Year-in-Review
This year: 2k papers triaged, 600+ reviewed. The final set is wild.
Foundation models, multimodal bio, spatial everything, generative proteins, and some pure brain candy. Can't wait to present! #Amplify2026
I’m looking forward to hosting a conversation with leaders from @bmsnews and @TempusAI about a challenge that continues to come up in oncology: too many patients still face barriers to the testing and treatments that could help them most.
Register here: https://t.co/HZlbKLddZO
We then tested a simple correction pipeline: WhisperX transcription → LLM correction
Passing transcripts through an LLM told to “adjust the errors” reduced word error rates by ~4.5–6.9 pts
This also narrowed the gap between groups
https://t.co/le5wyfb0KU
GI fellow Jamil Samaan noticed something odd when using AI ambient scribes and speech transcription tools
Clinicians with non-native English accents appeared to confuse the model
He and Yassi Fatapour decided to investigate, now out in npj Digital Medicine
https://t.co/le5wyfb0KU
Some patterns stood out
1) the gap was largest in base Whisper with ~11 point higher word error rates for non-native speakers
2) errors clustered in clinically dense language
3) more biomedical terminology > higher error rates - medication/disease names were especially vulnerable
CLAUDE CODE but for HACKING
its called shannon, you point it at website and it just... tries to break in... fully autonomous with no human needed
i pointed it at a test app and it stole the entire user database, created admin accounts, and bypassed login, all by itself, in 90 minutes
Training our LLMs to be sycophants has real consequences, especially in healthcare.
When are models are overconfident, we all suffer. Check out our editorial here
https://t.co/BLfzSqq8Mn
New editorial in BioData Mining: A crisis of overconfidence in clinical AI led by @CedarsSinai PhD student, Jacob Berkowitz.
Why sounding confident can be more dangerous than being inaccurate, and why calibration needs to be central in clinical AI.
https://t.co/BLfzSqq8Mn
AlphaGenome is our latest & most advanced genomics model published in @Nature today including making the model & weights available to academic researchers. Can’t wait to see what the research community will do with it. Congrats to the team on our newest front cover! #AI4Science
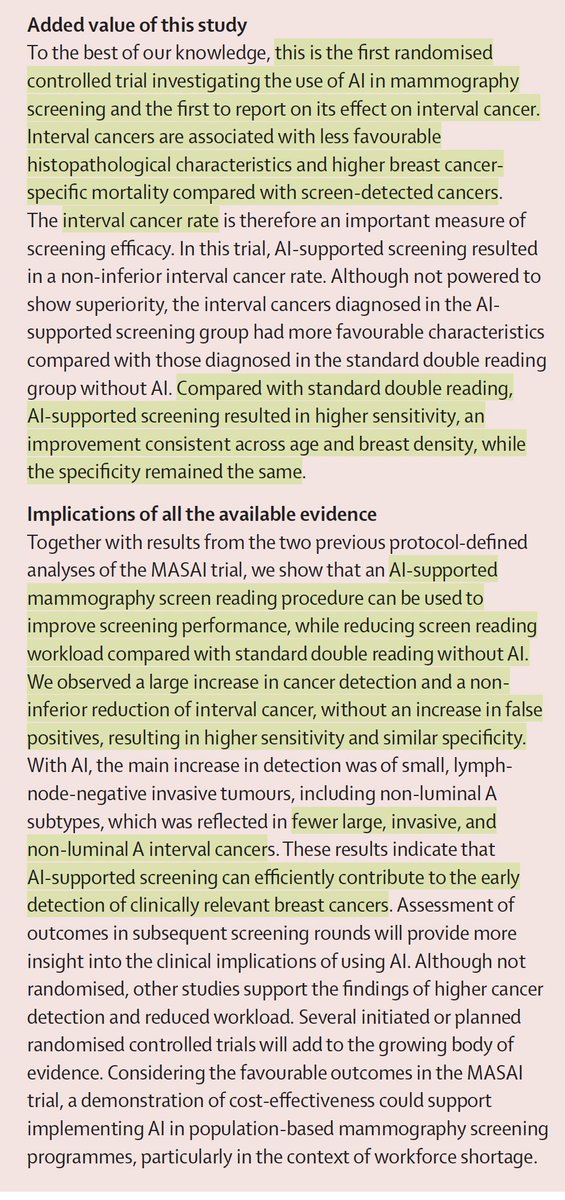
The largest randomized trial of medical A.I.
—Over 100,000 women in Sweden
—radiologist + AI vs 2 radiologists, in follow-up
—AI added led to 29% more cancer detected, 44% reduced workload, and
—Less cancer dx in subsequent 2 years, and, when found, less aggressive
https://t.co/e1hY3F0cGo
Excited to announce our new project with ARPA-H which advances methods to artificially accelerate the aging of organoids to study drug toxicities over time. A current huge gap in our understanding and our models.
https://t.co/CBx1CCqWYX
This paper is wild. After 3 rounds of directed evolution, they converted a DNA polymerase into an enzyme that can do:
- RNA synthesis
- Reverse transcription
- Synthesis of "unnatural" nucleotides
- Synthesis of DNA-RNA chimeras
One of the best papers I’ve read recently.
For context: In nature, it is DNA polymerase that takes a DNA sequence as a template and then copies it. These enzymes are crucial in replicating the genome for cell division, and they are EXTREMELY specific for DNA over RNA. This is key because RNA nucleotides are present in the cell at concentrations ~100x higher than DNA nucleotides, so the enzyme has evolved clever strategies to select one over the other.
RNA polymerases, for comparison, are the enzymes that take a DNA sequence as template and then convert it into RNA. They are involved in gene expression, for example.
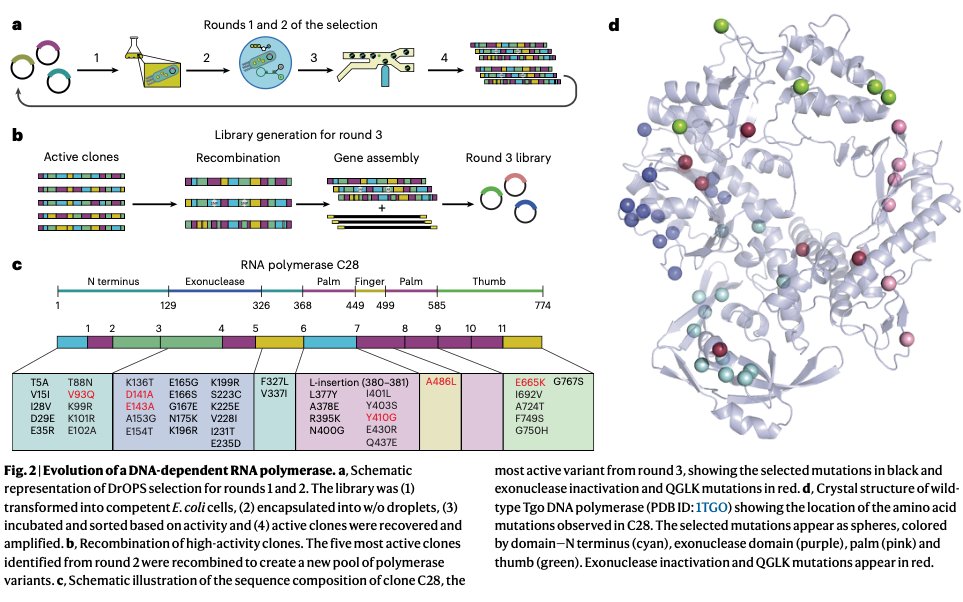
To convert a DNA polymerase into an RNA polymerase (and all the other functions I mentioned earlier), the authors did a fairly straightforward directed evolution experiment.
First, they took four DNA polymerase enzymes belonging to various archaea. These DNA polymerases don’t check for DNA vs. RNA as stringently as other types of cells, so they’re a good starting point to evolve RNA polymerases. The authors inserted some targeted mutations into these enzymes, based on known mutations in the literature. For example, they swapped the amino acid at position 409 for a smaller amino acid, thus removing a “gate” that keeps RNA building blocks from entering the enzyme.
Next, they took the four genes encoding these DNA polymerases and cut them up into 12 segments each. They randomly stitched these 12 segments together — from the four different genes — to build millions of unique variants. Each shuffled gene was inserted into an E. coli cell.
Then, they grew up these cells (each carrying a unique polymerase) and put them into microfluidic droplets. A device isolates each droplet, lyses the cell open, and releases the polymerase. The droplet also contains RNA building blocks and a DNA template, encoding a fluorescent reporter. If the polymerase begins synthesizing RNA, it will produce a detectable signal. They screened about 100 million droplets in 10 hours of work, searching for those with a signal.
For each well that yields a fluorescent signal, the researchers isolated the DNA and sequenced it to figure out which polymerase it was. They repeated this 3x times, finally isolating a really excellent RNA polymerase variant which they called "C28."
C28 has 39 mutations compared to the wildtype enzymes. It incorporates about 3.3 nucleotides of RNA per second, with 99.8% fidelity. The crazy thing is that this enzyme can also copy DNA or RNA templates back into DNA (reverse transcription), or use chimeric DNA-RNA molecules as a template and amplify them. It is just a super versatile polymerase that can act on DNA, RNA, or modified nucleotides, to build just about anything.
Science matters – and so do its stories. Knowable Magazine is producing consumer friendly stories about real scientific discoveries. If you'd like to support their efforts through donations, you can find out more here:
https://t.co/FUDciQlkyJ