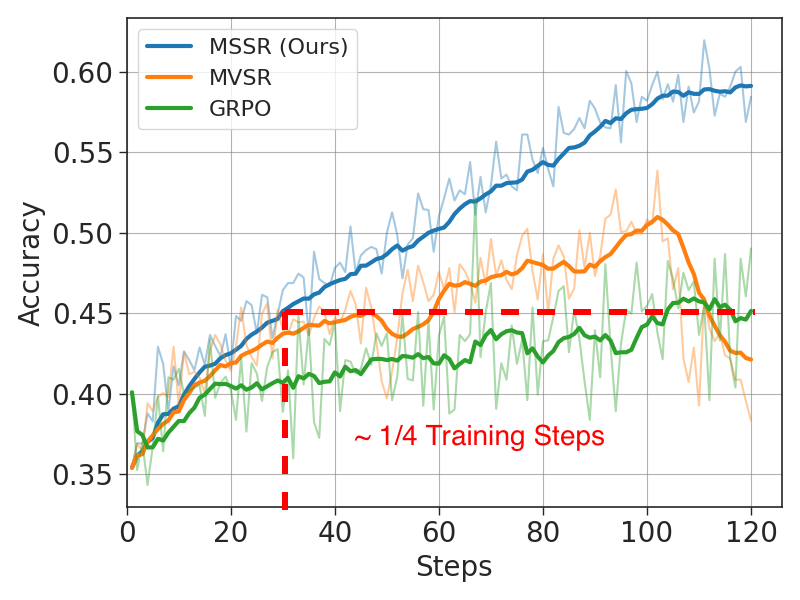
I am heading to #CVPR2026 next week to present our work MSSR (Multimodal Stabilized Single-Rollout). This work aims to improve the training efficiency of multimodal RLVR by using just single rollout instead of group-based approaches such as GRPO.
With around 1/4 of training steps, our approach can reach similar accuracy as GRPO. While trained for the same amount of compute and test on multiple benchmarks for generalization performance, our approach can outperform other group-based baselines.
Thanks to all my amazing collaborators Dian Yu, Lei Ke, @HaolinLiu616, @YujunZhou0017, @LiangZhenwen, @haitaominlp, @ptokekar, Dong Yu.
I will also be actively looking for full time opportunities, very happy to connect!
Paper: https://t.co/h8FhLUrRQY
Project page: https://t.co/qOb2bYmV4r
Join us and @JohnsHopkinsIAA on Monday for a joint talk on trends in safe and reliable reinforcement learning, featuring @JHUAPL’s @aekoppel and @umdcs & @amazon Robotics’ @ptokekar. Learn more here: https://t.co/jAUsBHZrnt
‘Tis the season.. @jbhuang0604 has amazing advise as usual with really cool slides (including a blurb from me that’s so old it mentions something called Webex?!)
Some of my earlier notes in case you’re interested https://t.co/1SfXUFnRFU
Sharing the slides for a talk on faculty job search
Hope it's helpful to people exploring and preparing for the process.
Feedback is welcome!
https://t.co/d0yWKt7sEO
We expanded our best paper finalist @DARSSymposium with a graph neural network based policy to restore connectivity in a team of robots facing adversarial conditions. Check it out!
Honored to be featured by @umiacs_umd for showcasing my work in robot learning at the @Amazon Robotics Research Symposium in Boston!
Grateful for my advisor @ptokekar, collaborators & the UMD community for their support.
🔗 https://t.co/7fyOyuQCt4
Can robots get to the point?🎯
We’re sharing AFFORD2ACT—a way for robots to use semantics from a short prompt to keep only the pixels that matter and then act.
This replaces heavy, dense inputs with a small state for control.
1/6
#Robotics#AI#Manipulation#Affordance#Keypoints
How can we utilize cross-embodiment action-free videos in learning generalizable and robust policies?
Introducing our paper in ICCV 2025 @ICCVConference (also best paper nomination at the ICRA FMNS WS), GenFlowRL: an reward shaping method with generative object-centric flow. 1/6
(1/n)
CAML: Collaborative Auxiliary Modality Learning for Multi-Agent Systems
Authors: @ruiliu0, Yu Shen, @penggao41252277, @ptokekar, @MingCLinCS
Link: https://t.co/iB98MdWF9Y
This Paper proposes Collaborative Auxiliary Modality Learning (CAML), a multi-modal multi-agent framework that enables collaborative training with shared modalities while supporting reduced-modality inference, achieving significant gains in accident detection for connected autonomous vehicles and semantic segmentation in aerial-ground robot data.
🚀 It feels refreshing to share some new theoretical results! #NeurIPS2025 🎉
🔑 One-line takeaway: We prove that policy gradient methods can achieve global optimality even in the broader setting of general utility RL
More details coming soon!!