New write-up: High-Dimensional Geometry and Metric Collapse in Representation Spaces
I develop the chain:
concentration -> orthogonality -> distance degeneration and state its
Implications for embeddings, similarity, and generalization in ML.
https://t.co/b9brYgXU1A
Shipping Protein.cpp: open-source CPU inference for protein LMs like @biohub ESMC.
llama.cpp-style quantization for biomodels.
Huge credit to @ggerganov GGML.
My past weeks have been interesting.
https://t.co/zEoP9kkGOE
We are building the future of legal practice at @llavaApp. A future where lawyers do not have to spend endless hours or even days on repetitive tasks.
Lawyers should be focusing on strategy, advocacy, and delivering top-tier value to their clients, not stuck in manual work
African lawyers spend up to 60% of their time on manual drafting & research, limiting growth.
It’s time to work smarter. The llava Private Beta is LIVE.
- Automate research & drafting,
- Multi-lingual client briefing and analysis.
Join: https://t.co/pDgqaGoXVj
We recently put up two channels on discord where our users can suggest the next market we could list
And another channel containing the already listed markets to make access easier
Check it out👀
https://t.co/ef1cDFCsax
Shannon Entropy: Measuring Uncertainty in Information
H(X) = - ∑ P(xᵢ) log P(xᵢ)
This is the legendary formula by Claude Elwood Shannon (1916–2001); the father of Information Theory.
Entropy quantifies how much uncertainty (or average information) is contained in the outcome of a random variable X. The more unpredictable the outcomes, the higher the entropy.
From data compression and cryptography to AI and communications; this concept powers the digital world.
Hermite Expansion is a powerful mathematical tool used to represent functions through Hermite polynomials, which form an orthogonal basis under Gaussian measures. Originally developed in probability theory and mathematical physics, Hermite expansions later became important in stochastic analysis, approximation theory, and functional analysis.
In machine learning (ML), Hermite expansions are useful because many models involve Gaussian assumptions in data, noise, or latent variables. They appear in kernel methods, random feature models, and nonlinear approximation techniques. Hermite-based representations often help simplify high-dimensional learning problems and provide theoretical insight into model behavior.
In deep learning (DL), Hermite methods are used to analyze neural network dynamics, activation functions, and representation learning. Researchers use them to study how neural networks approximate complex nonlinear functions and how information propagates through deep architectures.
In reinforcement learning (RL), Hermite expansions appear in stochastic control, value function approximation, and diffusion-based decision models. They are particularly useful in noisy environments where uncertainty and Gaussian processes play central roles. Hermite techniques also connect with Wiener chaos expansions, helping researchers analyze stochastic gradients, uncertainty propagation, and learning dynamics in modern AI systems.
Image: https://t.co/tVHclcTRFU
One theorem every ML engineer should know:
The Johnson–Lindenstrauss Lemma.
It states that high-dimensional data can be projected into a much lower-dimensional space while approximately preserving pairwise distances.
Why it matters:
• Explains why random projections work
• Enables scalable learning in high dimensions
• Used in embeddings, compressed learning, and ANN search
• Helps fight the curse of dimensionality
The surprising part:
You can reduce dimensions dramatically without destroying the geometry of the data.
That’s why many ML systems can operate efficiently even with massive feature spaces.
Modern representation learning is deeply connected to this idea:
Good embeddings preserve structure while compressing information.
In ML, compression is often not loss of intelligence —
it’s removal of redundancy.
My name is Jhay — Jhaycodes when it’s work.
I’m a 300-level Software Engineering student at FUTO, building a career from what I love.
But balancing school and making money? Hmmm, its a bit dicey can't lie 🥹
@thegarageng_#studentworkseries
The Singular Value Decomposition (SVD) breaks any matrix into three clean parts. Rotate - stretch - rotate.
Surprisingly the most important part of the SVD is the part that stretches. It contains diagonal elements called singular values which are fundamental to compression.
Day 103/365… Hey guys today is day 103 of my 365 days of coding series…
Me and the homies [@too_chi_@Dev_JesseMaduka , @Osmond_Jnr , @Jonaka_Udu , @DevThragg ]
are building Devfolio, it’s a CLI tool that turns your GitHub profile into a sleek, deployment-ready portfolio in seconds.
Most of the time developers don’t have time for building their own portfolio or don’t have inspiration… well then use devfolio…
How to try it:
1. Clone the repo
2. Run npx devfolio init
3. Answer a few prompts
5. cd into new portfolio folder
6. Run npm run dev
That’s all.
Done.
We haven’t dropped the NPM package yet sha!!!
Visit the documentation: https://t.co/eoQqwmFq73
Have fun and do well to show me your new portfolio’s. Anticipate Day 104.
#365DaysOfCode
#BuildingInPublic
Worked with their team on the production of this project led by @too_chi_ where I contributed the templates for Next.js (my go-to framework)
The repository is available at https://t.co/5jIUsWfscy
The documentation is available at https://t.co/eC5lX3i3Kl














![alll_well's tweet photo. Day 103/365… Hey guys today is day 103 of my 365 days of coding series…
Me and the homies [@too_chi_ @Dev_JesseMaduka , @Osmond_Jnr , @Jonaka_Udu , @DevThragg ]
are building Devfolio, it’s a CLI tool that turns your GitHub profile into a sleek, deployment-ready portfolio in seconds.
Most of the time developers don’t have time for building their own portfolio or don’t have inspiration… well then use devfolio…
How to try it:
1. Clone the repo
2. Run npx devfolio init
3. Answer a few prompts
5. cd into new portfolio folder
6. Run npm run dev
That’s all.
Done.
We haven’t dropped the NPM package yet sha!!!
Visit the documentation: https://t.co/eoQqwmFq73
Have fun and do well to show me your new portfolio’s. Anticipate Day 104.
#365DaysOfCode
#BuildingInPublic](https://pbs.twimg.com/media/HF0aXKOXkAA3dYc.jpg)















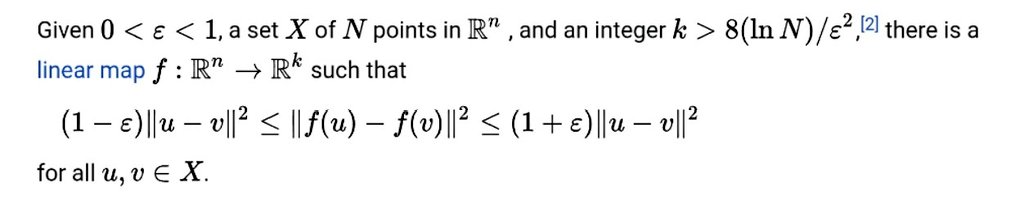

![alll_well's tweet photo. Day 103/365… Hey guys today is day 103 of my 365 days of coding series…
Me and the homies [@too_chi_ @Dev_JesseMaduka , @Osmond_Jnr , @Jonaka_Udu , @DevThragg ]
are building Devfolio, it’s a CLI tool that turns your GitHub profile into a sleek, deployment-ready portfolio in seconds.
Most of the time developers don’t have time for building their own portfolio or don’t have inspiration… well then use devfolio…
How to try it:
1. Clone the repo
2. Run npx devfolio init
3. Answer a few prompts
5. cd into new portfolio folder
6. Run npm run dev
That’s all.
Done.
We haven’t dropped the NPM package yet sha!!!
Visit the documentation: https://t.co/eoQqwmFq73
Have fun and do well to show me your new portfolio’s. Anticipate Day 104.
#365DaysOfCode
#BuildingInPublic](https://pbs.twimg.com/media/HF0aXKlasAca4Tf.jpg)




















