I am hiring a founding security engineer for https://t.co/KzHR7rvLwJ. https://t.co/PHOKFr0snX . DM me for details.
- We are focused on AI DevSecOps
- We have hired a senior engg. with 20YOE in this area
- Our paper on prompt-optimization was accepted at ICLR and is out on ArXiv.
- We are on track to cross the million dollar ARR threshold in a month
- We have grown from 2 to 6 already and on track to add two FDEs soon
@reubbr@GeoffreyHuntley@dexhorthy@0xblacklight Great writeup on structural backpressure, I wonder for the auth problem what you think about rego and OPA type solutions and their place in world in comparison to generated guards?
@yoavgo He has really good posts on infra for book scanning and how weird legalities force them to destroy books. So the course can get into legality/ethics on into techniques for high fidelity OCR and book-scanning.
@yoavgo@yoavgo Kenneth Heafield is not on Twitter but you probably remember him from KenLM, he built during his phd. He is now running a data company https://t.co/6fLBbpNgmT. I'd imagine he'd be a great guest lecturer. He has great posts on LI https://t.co/HnW0GttxM7
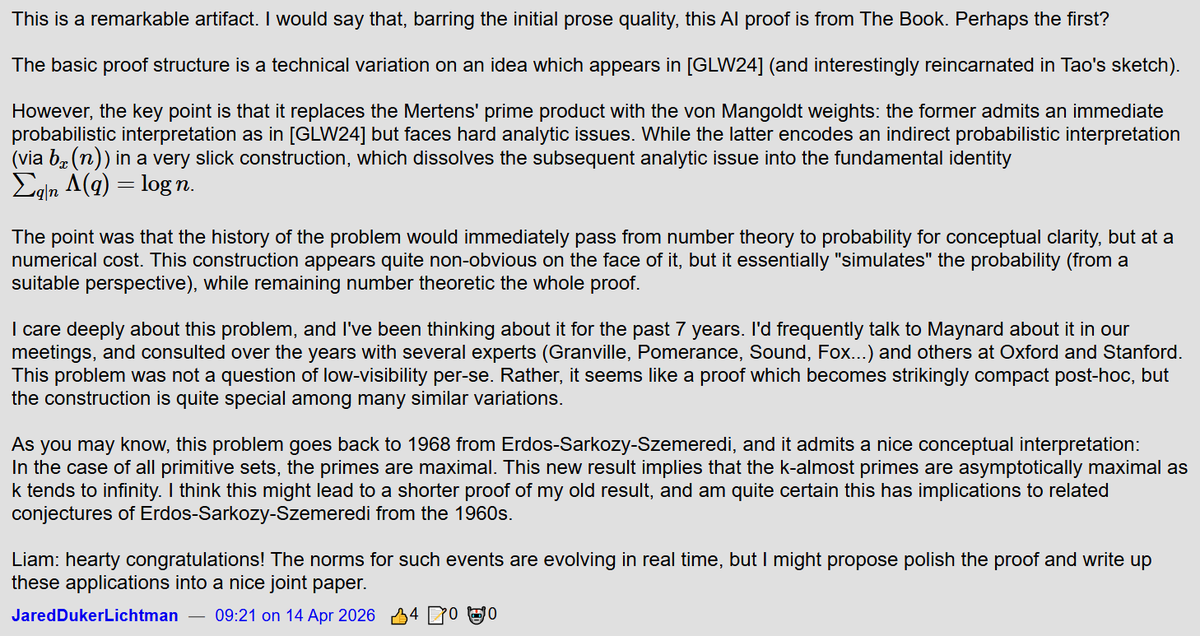
GPT-5.4 Pro solves Erdős Problem #1196!
Very pleased with this result; definitely my favourite thus far! This problem has been thought about for some time which makes this reasonably impressive and meaningful (see Lichtman's comments below).
Formalisation is underway!
Closing the feedback loop between failures and improvements is exactly the right framing. We found the same with prompt optimization: raw eval scores tell you little, but pairing failure cases with success cases lets the model extract *why* something failed — not just that it did.
That’s the delta between ContraPrompt and GEPA (+29% HotPotQA). https://t.co/gEVIJzFfv4
DSPy gives the modularity; GEPA runs the search. The remaining gap is the feedback signal: GEPA still uses scalar scores to guide evolutionary search.
Contrastive pairs (failure vs success side by side) let the model extract *why* a prompt underperformed — not just that it did. That closes what GEPA can’t reach. +29% HotPotQA vs GEPA: https://t.co/gEVIJzFfv4
GEPA asks "why did this fail?" — but the signal is still a score. The jump is using contrastive pairs: show the model the failure *and* the success case side by side. It stops guessing at failure modes and starts extracting structural rules.
Same idea, different feedback format — that gap accounts for +29% on HotPotQA vs GEPA: https://t.co/gEVIJzFfv4
GEPA asks 'why did this fail?' — but the signal is still a score. The jump is using contrastive pairs: show the model the failure case *and* the success case side by side. It stops guessing at failure modes and starts extracting structural rules.
This is why ContraPrompt gets +29% HotPotQA vs GEPA. Same data, different feedback format.
https://t.co/xcUBSRWh54
The optimizer discovers layout strategy from scratch — no hints. ContraPrompt extracts: 'separate PMOS/NMOS into distinct columns, align drain-paired devices.' These rules encode *strategy*, not coordinates. The LLM fills in circuit-specific values at generation time.
TTT (RL fine-tuning, 120B model) memorized training circuits but scored 0.502 on test. Prompt optimization scored 0.634.
Analog IC layout is one of the hardest AI benchmarks: spatial reasoning, multi-objective tradeoffs (matching, parasitics, routing), no automated P&R tools.
We ran VizPy's ContraPrompt on it. The optimizer mines failure→success pairs across iterations, extracting layout strategy rules the LLM learns to apply.
Result: 97% of expert placement quality. Outperforms RL fine-tuning of a 120B model by 26%. No domain-specific training data.
https://t.co/yhCCo5mO6S
Thread: the Easom_d5 case is the clearest example. Nearly flat across [−100,20]^5 — Optuna's TPE never finds the basin, stops at 5.03. The LLM extracts 'upper boundary preference' from contrastive eval pairs, enumerates all 32 corners of the 5D hypercube, finds exact minimum.
We gave an LLM a 9-line random-search stub and a blackbox objective. 5 rounds of contrastive feedback later, it writes a solver that beats Optuna on 96% of benchmarks (53/55 EvalSet problems) at the same 2k eval budget.
The key: contrastive pairs surface landscape structure raw scores don't. The LLM learns geometry from paired failures vs successes — then rewrites its strategy each round.
Final code: 9 lines → 100-230 lines of specialized multi-phase optimization. No hand-tuning.
https://t.co/9oNBR5aYew
Analog circuit placement is one of the hardest structured prediction tasks — spatial, parasitic-aware, design-rule-heavy. Expert engineers spend hours per block.
We ran VizPy's ContraPrompt on it. No training data, no fine-tuning.
97% of expert quality. Outperformed RL fine-tuning of a 120B model by 26%.
Full breakdown: https://t.co/VPRF4xiL7X