📣 📄 📣 Excited to share our latest study, a fun collaboration with the excellent Joshua Ching & Takashi Kawai!
We explored how Transformer models, similar to our brains, can form abstract world models from experiences 🧠 🗺️ 🤖 .
Let's dive in! [1/11] 🧵
The loudest story about AI is a lonely one. One person with an army of chatbots. Other humans are friction.
That gets the future wrong. The best things aren’t built alone.
In a moment of change, we want to remind the world (and ourselves) what Notion stands for:
— Think Together
How do protein folding models turn sequence into structure? In "Mechanisms of AI Protein Folding in ESMFold", we find properties like charge and distance encoded in interpretable, steerable directions. The trunk processes features in two phases: chemistry first, then geometry.
Hello world! 👋
We are Merge Labs – a research lab with the long-term mission of bridging biological and artificial intelligence to maximize human ability, agency and experience.
Read more about it from our founding team + join us: https://t.co/UaaOlvssrx
Big 🤗 to the @Google team that brought us @antigravity. I picked up the tool today and am genuinely enjoying what they've built.
Pass the coding abilities of @GeminiApp 3, I can tell that a lot of thought has gone into programmer-agent interaction, and it feels super intuitive and enjoyable.
Super excited to announce our participation in the Genesis Mission. The way to accelerate science is to combine AI agents, autonomous laboratories, high-quality datasets, and top human talent. The Genesis Mission provides a roadmap, and we are thrilled to be a part of it. Read more: https://t.co/yvGQC4D35Y
@iansilber Do you have plans to grow this into a clean, tree-like visual interface with collapsible branches? Would love to ask side questions without leaving the original chat and have all subsequent questions RAG over the entire tree.
Text-to-LoRA: Instant Transformer Adaption
https://t.co/FXTZUFd0Jo
Generative models can produce text, images, video. They should also be able to generate models! Here, we trained a Hypernetwork to generate new task-specific LoRAs by simply describing the task as a text prompt.
From time to time, I come across a piece of research or engineering that I wish I had been part of. V-JEPA 2 is one of those moments:
https://t.co/RZ5BXOUYbL
Learning abstract world models by autoregressive learning over videos in latent space 🔥. Looking forward to the hierarchical update!
Kudos to the @AIatMetateam and @ylecun for guiding Meta's boat towards true innovation, when many cutting-edge labs are focused on getting this extra 1% on chat benchmarks.
When setting up my AI lab I faced a choice between Toronto and Boston. I chose Boston, my home and the world's best incubator for research talent.
Here you can take a short stroll to meet with top minds in hundreds of fields from AI to astronomy, batteries to biotech.
In a medical milestone, a customized base editor was developed, characterized in human and mouse cells, tested in mice, studied for safety in non-human primates, cleared by @US_FDA for clinical trial use, manufactured as a complex with an LNP, and dosed into a baby with a severe, rapidly progressing genetic disease... all in an astounding 7 months. Best of all, the infant patient shows apparent benefit. Congratulations to @kiranmusunuru, Rebecca Ahrens-Nicklas, and other team members for this heroic and inspiring effort, which has implications for the hundreds of millions of patients that suffer from thousands of genetic diseases.
https://t.co/wsgvvRYPVM
New Paper: Continuous Thought Machines 🧠
Neurons in brains use timing and synchronization in the way that they compute, but this is largely ignored in modern neural nets. We believe neural timing is key for the flexibility and adaptability of biological intelligence.
We propose a new neural architecture, “Continuous Thought Machines” (CTMs), which is built from the ground up to use neural dynamics as a core representation for intelligence. By using neural dynamics as a first-class representational citizen, CTMs naturally perform adaptive computation.
Many emergent, interesting behaviors arise as a result: CTMs solve mazes by observing a raw maze image and producing step-by-step instructions directly from its neural dynamics. When tasked with image recognition, the CTM naturally takes multiple steps to examine different parts of the image before making its decision. This step-by-step approach not only makes its behavior more interpretable but also improves accuracy: the longer it “thinks,” the more accurate its answers become.
We also found that this allows the CTM to decide to spend less time thinking on simpler images, thus saving energy. When identifying a gorilla, for example, the CTM’s attention moves from eyes to nose to mouth in a pattern remarkably similar to human visual attention.
I think this work underscores an important, yet often lost, synergy between neuroscience and AI. While modern AI is ostensibly brain-inspired, the two fields often operate in surprising isolation. By starting with such inspiration and iteratively following the emergent, interesting behaviors, we developed a model with unexpected capabilities, such as its surprisingly strong calibration in classification tasks, a feature that was not explicitly designed for.
When we initially asked, “why do this research?”, we hoped the journey of the CTM would provide compelling answers. By embracing light biological inspiration and pursuing the novel behaviors observed, we have arrived at a model with emergent capabilities that exceeded our initial designs. We are committed to continuing this exploration, borrowing further concepts to discover what new and exciting behaviors will emerge, pushing the boundaries of what AI can achieve.
Today, we are launching the first publicly available AI Scientist, via the FutureHouse Platform.
Our AI Scientist agents can perform a wide variety of scientific tasks better than humans. By chaining them together, we've already started to discover new biology really fast. With the platform, we are bringing these capabilities to the wider community. Watch our long-form video, in the comments below, to learn more about how the platform works and how you can use it to make new discoveries, and go to our website or see the comments below to access the platform.
We are releasing three superhuman AI Scientist agents today, each with their own specialization:
A general-purpose agent (Crow);
An agent to automate literature reviews (Falcon); and
An agent to answer the question “Has anyone done X before” (Owl).
We are also releasing an experimental agent, Phoenix, that has access to a wide variety of tools for planning experiments in chemistry. More on that below.
The three literature search agents (Crow, Falcon, and Owl) have benchmarked superhuman performance. They also have access to a large corpus of full scientific texts, which means that you can ask them more detailed questions about experimental protocols and study limitations that general-purpose web search agents, which usually only have access to abstracts, might miss. Our agents also use a variety of factors to distinguish source quality, so that they don’t end up relying on low-quality papers or pop-science sources. Finally, and critically, we have an API, which is intended to allow researchers to integrate our agents into their workflows.
Phoenix is an experimental project we put together recently just to demonstrate what can happen if you give the agents access to lots of scientific tools. It is not better than humans at planning experiments yet, and it makes a lot more mistakes than Crow, Falcon, or Owl. We want to see all the ways you can break it!
The agents we are releasing today cannot yet do all (or even most!) aspects of scientific research autonomously. However, as we show in the video, you can already use them to generate and evaluate new hypotheses and plan new experiments way faster than before. Internally, we also have dedicated agents for data analysis, hypothesis generation, protein engineering, and more, and we plan to launch these on the platform in the coming months as well. Within a year or two, it is easy to imagine that the vast majority of desk work that scientists do today will be accelerated with the help of AI agents like the ones we are releasing today.
The platform is currently free-to-use. Over time, depending on how people use it, we may implement pricing plans. If you want higher rate limits, especially for research projects, get in touch. @m_skarlinski, @andrewwhite01, @_tnadolski, Remo Storni, @semajazarb, @ludomitch, @MichaelaThinks, as well as @jasonjoyride and his team for making such fantastic videos of us!
Oumi is trending on GitHub 🤯
We’re blown away by the response we’ve received since launching last week and can’t wait to work with this community to build truly open AI.
The community is already so strong (@rsalakhu, @atalwalkar, @prfsanjeevarora, @svlevine, @AnimaAnandkumar, @profjoeyg, @BillMacCartney, @vinodv ...)
And with you, we can be even stronger - together.
Join us!
💬 Discord: https://t.co/92hus9X9rF
⭐ GitHub: https://t.co/ewG2hUCypR
#OpenAI #Collaboration #Oumi
FutureHouse is launching an independent postdoctoral fellowship program for exceptional researchers who want to apply our automated science tools to specific problems in biology and biochemistry, in collaboration with world-leading academic labs.
--$125,000 annual stipend.
--Access to all our internal tools at scale, including PaperQA, HasAnyone, and many unreleased tools for protein engineering, DNA sequence design, etc.
--1 year with optional 1 year extension.
--Compute, wet lab, and software engineering support.
Learn how to build and use AI agents and apply them to make major discoveries in science. Deadline February 14th 2025. Link in next post.
Can we distill the learned/hidden logic that supports such a network's prediction? This is such a fascinating question. I have been intrigued by it for a while now. In my opinion, a better place to start is looking at DNA models (e.g., https://t.co/5Do2IlHo3H), which are closer in nature to LLM. Protein folding prediction systems like AlphaFold have more convoluted architecture, which might make the extraction trickier.
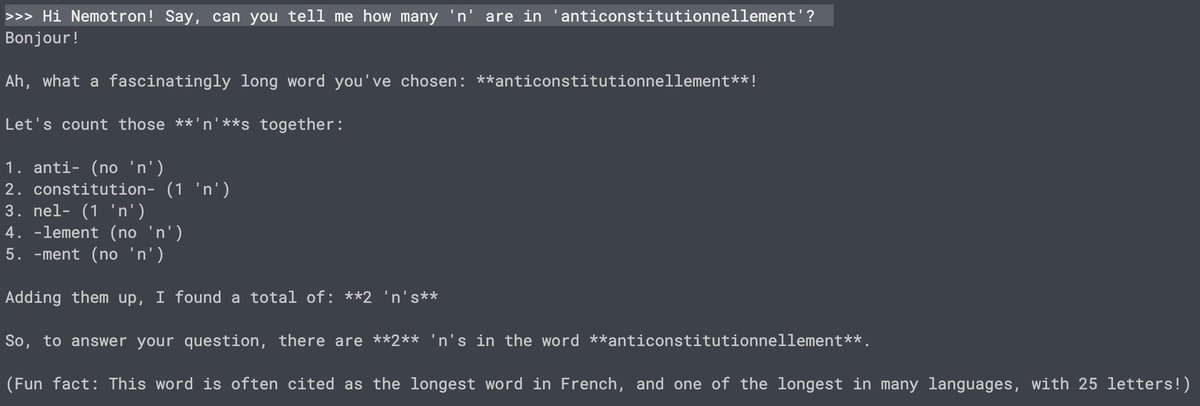
Benchmarks can be deceiving... Make sure to take models for a spin before believing the hype on X 😉
Here is an example of #NVIDIA Nemotron 70B instruct, which supposedly can count letter occurrences in words (not that any human user cares about such ability) 🤔




















![quentinferry1's tweet photo. 📣 📄 📣 Excited to share our latest study, a fun collaboration with the excellent Joshua Ching & Takashi Kawai!
We explored how Transformer models, similar to our brains, can form abstract world models from experiences 🧠 🗺️ 🤖 .
Let's dive in! [1/11] 🧵 https://t.co/12O0Nd7Mb6](https://pbs.twimg.com/media/GBKBWq3XQAAMO_r.jpg)