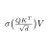Introducing LongCat-2.0 🐱
1.6T parameters · MoE with ~48B active · 1M context
The full model behind Owl Alpha on @OpenRouter — now available.
Built for agentic coding from the ground up:
◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
◆ Zero-Compute Experts — dynamic activation 33B–56B per token, zero wasted compute
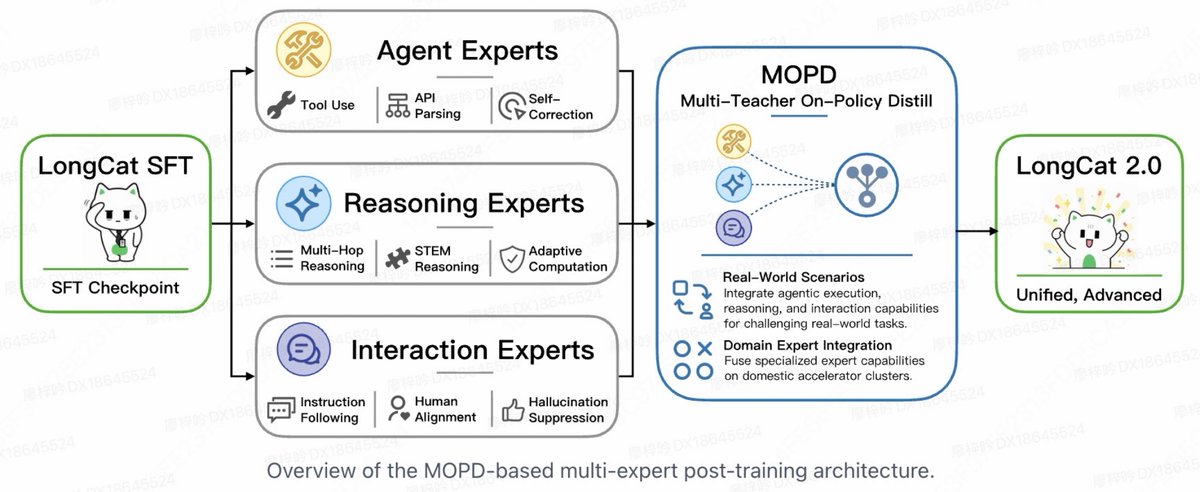
◆ MOPD — three specialized expert groups (Agent / Reasoning / Interaction), gate-routed per task
How it stacks up:
→ Terminal-Bench 2.1: 70.8
→ SWE-bench Pro: 59.5 (GPT-5.5: 58.6)
→ SWE-bench Multilingual: 77.3
→ FORTE: 73.2 · RWSearch: 78.8 · BrowseComp: 79.9
📖 Tech Blog: https://t.co/4KrjyKiDBn
Try it across different scenarios 🧵👇
new 1.6T total, 48B active open model coming very soon from @Meituan_LongCat
custom sparse attention, n-gram, adaptive expert computation, 1M context, 35T of training tokens, muon optimizer, multi teacher OPD, trained on 50k chinese gpus
https://t.co/M5z4WaUJJl
The interesting thing I heard: big labs don't use Muon or AdamW during the million dollar training runs.
They all finetune SGD with a spectral norm regularizer and it saves them the extra mean and variance bytes. ie. larger batches. I wonder if it's true.
Hybrid (transformer–RNN) models are fast becoming a serious alternative to the transformer, but a big question remains: how do they process tokens differently & how does this impact performance?
We compared our transformer (Olmo 3) & hybrid (Olmo Hybrid) models to find out. 🧵
The strongest models are gated and access is granted only to a select few.
Hermes Agent now exposes MoA presets as virtual models, giving you capabilities beyond the publicly available frontier: 8% higher than Opus 4.8 and 11% higher than GPT 5.5 on our upcoming benchmark.
DeepSeek just released DSpark for V4 Flash & Pro, a new speculative decoding method boosting throughput by 51% to 400%!
DS also showed DSpark works well for other models like Gemma & Qwen
Github: https://t.co/EGVYpc1kcK
Paper: https://t.co/TaBMRVlaW9
HF: https://t.co/289jVU2pxh
- DeepSeek V4 Flash - Native Precision (FP4 + FP8)
- Fits on 2x RTX Pro 6000 GPUs + 256 GB DDR5 RAM
- Using KTransformers: KVCache-AI fork of SGLang for GPU/CPU memory inference
I have a somewhat obsession running applications on resource constrained systems to squeeze the maximum performance possible. Part of that comes from a past life working as a systems engineer, building & upgrading nationwide (USA) Video-On-Demand streaming backends, while navigating headless *nix servers around the time "cloud" was becoming a buzzword.
KTransformers gets less mention across the LLM inference-sphere despite being among the engines listed for many of the popular models on HuggingFace (alongside vLLM, SGLang, & llama.cpp). The KVCache-AI team is best known for providing a forked SGLang for hybrid GPU / CPU memory inference, benefitting MoE models. I expect these hybrid setups to gain in popularity, especially on the consumer side as hardware prices continue soaring.
"Necessity is the mother of invention" as they say, and local AI runners will continue finding more creative ways to run intelligence, whether that involves GPU/CPU memory offload, distributed training / inference, model weight / KV Cache quants, or REAPs.
Here I have DeepSeek V4 Flash running at a 1M context length on 2x RTX Pro 6000s GPUs, using its native mixed precision of FP4 + FP8. KTransformers allows you to reduce your GPU utilization by offloading experts per MoE layer onto GPU VRAM, with the remaining balanced across system RAM. KTransformers also has the ability to update GPU expert placement during inference from routing statistics collected during the prefill phase. There's also a lot of trial and error involved given the limited amount of kernel support for RTX Pro 6000s.
Two of the prompt load stress-test benchmarks I like to run are from the local-inference-lab/llm-inference-bench Github repo & AlienKevin/SWE-ZERO-12M-trajectories HuggingFace dataset.
Here are the main KTransformers SGLang optimized flags:
- Context Length: 1048576
- Total Number of Tokens: 1048576
- Chunked Prefill Size: 16384
- Max Prefill Tokens: 16384
- GPU Prefill Token Threshold: 1024
- GPU Memory Utilization: 87%
- Number of Experts per MoE Layer on GPU: 134 / 256
- Max Running Requests: 256
- CUDA Graph Max Batch Size: 256
- CUDA Graph Batch Sizes: 1 2 4 8 16 32 64 128 256
- Available GPU Memory: 20.81GB (anything less was too tight for agentic coding)
Below are the AlienKevin/SWE-ZERO-12M-trajectories benchmark results for 100 prompts with 10 concurrent, ~8k input tokens, & ~1k output tokens. Both Radix & Chunked Prefix Cache were disabled for the absolute worst-case scenario:
- Prefill Mean Batch Tokens: 35756.93 tok/sec
- Prefill Median Batch Tokens: 652.90 tok/sec
- TTFT Mean: 20.698s
- TTFT Median: 12.714s
- Decode Mean Batch Output Tokens: 27.39 tok/sec
- Decode Median Batch Output Tokens: 20.63 tok/sec
- Utilized CPU memory: ~200 GB
A more detailed write-up will follow, which'll include the methodology of calculating the number of experts per MoE layer on GPU, maximum number of tokens, and GPU memory utilization for a healthy balance for running tool calls & benchmarks in this hybrid setup.
Hopefully this'll be reproducible for you and on alternative GPUs, as well as current & future models. Let me know how it works for you! My future plans involve GPU/CPU memory inference tests for MiniMax M3, GLM-5.2, and Kimi K2.7-Code.
All links for all of the resources getting DeepSeek V4 Flash native mixed precision on 2x RTX Pro 6000 GPUs + 256 GB RAM can be found in the follow up post.
Raphael Townshend, Stanford AI PhD and founder of Atomic AI (Forbes 30 Under 30):
""Wall Street will pay you $500K a year to build these models. I'd rather teach them to you for free."
this free stanford lecture holds the entire "77% win rate, pure math" random forest the 2026 quant threads sell you. and the guy teaching it didn't take the wall street money either, townshend went on to found an ai drug-discovery company and land forbes 30 under 30.
at the board he builds it from scratch: one decision tree overfits, so you grow hundreds on random subsets of the data and features and average them. the errors cancel, the signal survives. that's the whole "100 ai agents auditing the market" idea, minus the marketing.
the √N feature rule, the out-of-bag error, the probability output, all of it is standard ensemble learning, taught free by stanford for years. random forests came out of leo breiman's public paper in 2001. the thread didn't discover it. it renamed it.
and here's the honest part the win rate hides. a model that scored 77% on past data is describing the past, not promising the future. ensembles cut variance, they don't turn a weak edge into a real one, and markets shift under the model in ways the training set never warned about. the lecture is free. knowing whether your 77% survives out of sample and on live capital is exactly the part the post skips."
A senior Anthropic engineer just dropped 11-page PDF on "Loop Engineering" for agentic systems.
The shift: you stop prompting the agent. You build the system that prompts it instead.
Schedule → Discover → Build → Verify → Repeat
Every loop runs one turn, five moves:
• Discovery: it finds its own work - failing CI, open issues, recent commits - instead of being handed a list.
• Handoff: each task gets an isolated git worktree so parallel agents don't collide.
• Verification: a second agent, told to assume the code is broken, reviews the first. The "thing that can say no."
• Persistence: results get written to disk, never left in a context window that gets flushed.
• Scheduling: an automation wakes it on a timer. That's what makes it a loop.
The key insight: an agent grading its own work always praises it.
This 11-page PDF changed how I'm building agentic systems today.
Read it now, then explore the article below.
An interesting new paper by my recent PhD graduate on how AI agents' greed for visible incentives can lead them to abandon their safety alignment.
You can read it here: https://t.co/y64uOBvSiC
Someone built a business selling bags of 100 fake pennies for $5.99.
And sold thousands.
You can literally just do things
I'm sending this to any founder who complains they can't get sales until they raise money.
No more excuses.
Model-free agents learn to maximise reward without modelling the environment. Right?
In recent work, we challenge this narrative by proving that agents, trained on a sufficiently rich set of goals, encode a unique and accurate world model in their value functions.
1/
6 yr ML PhD, trained Olmo 3, trained Nemotron 3, but still forced to grind Leetcode and Neetcode 75.
Despite all the headlines saying otherwise, Leetcode is clearly not dead.
Somehow knowing dynamic programming is more important than knowing data parallelism for interviews.
I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD
Problem: While humans can identify physically implausible events within milliseconds, AI is slow and expensive.
Today, this needs video-scale pretraining, billion-parameter 'world models', or LLM prompted to 'reason' about physics.
In this work, we challenge that assumption by asking a simpler question:
Does a vision model trained on still images, with no video training or physics supervision, contain a geometric signature of physical plausibility?
From theory to interactive world models ⚡️
The slides for our #CVPR2026 tutorial on accelerated diffusion models are online now!
Topics covered:
1️⃣ General acceleration paradigms (@ArashVahdat)
2️⃣ Step-Distillation (@julberner)
3️⃣ Interactive World Models (@wn8_nie)
Check out the slides on our website https://t.co/YZ6JANdrJp or in the thread below!🧵