1/10) We found an observer effect in world models: Invasive adaptation can corrupt latent physics! 🌍
New Paper: https://t.co/WSpVdmJPhx
The phenomenon where the act of measuring a system unavoidably alters its state or properties (Heisenberg, 1927 & Sassoli de Bianchi, 2013).
New paper from Yann LeCun!
"When Does LeJEPA Learn a World Model?"
This paper proves that under Gaussian latent dynamics, LeJEPA can recover the hidden state behind nonlinear observations up to rotation.
The intuition is that linear latent features are the most stable across nearby views, while nonlinear features decay faster, so the objective naturally selects the real world variables.
The key caveat is that this guarantee holds under specific assumptions, and Gaussian latents are the unique case that guarantees this.
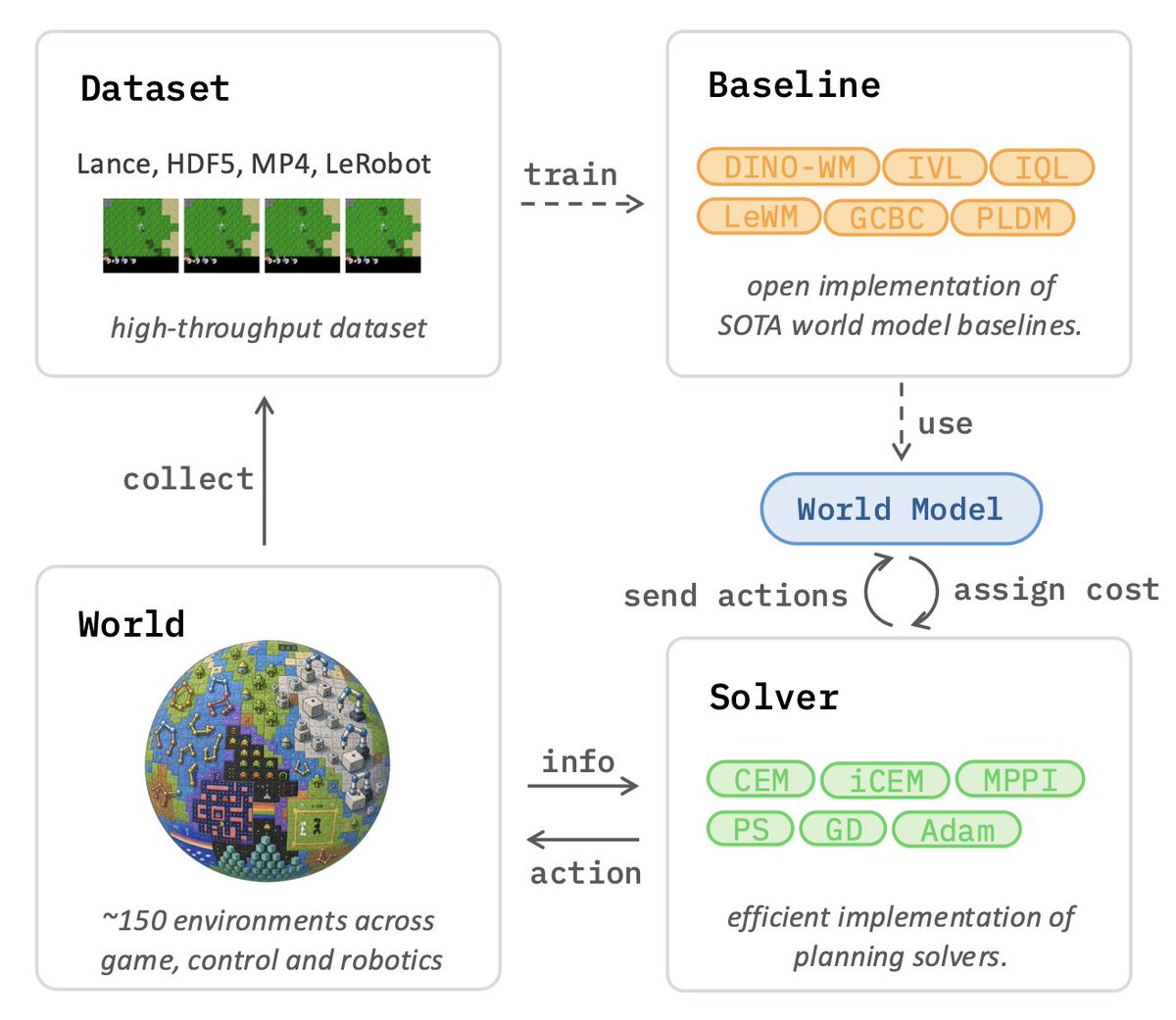
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
What does JEPA actually learn? We can finally prove it 🌍
So excited to share our theory of identifiable World Models: LeJEPA recovers the latent variables of the world.
Plan in the learned World Model as if it were real, same shortest path.
📄: https://t.co/lC9KK1AxVd
lowk only the PC chairs know the exact time decisions drop, i don't have more info than the rest of you. i'm stressing with y'all, between ICML decisions, the NeurIPS deadline, and everything else going on
best of luck to everyone. stay strong, we'll make it through together🫂
🚨 ICLR Oral 🚨
Is modern representation learning a valid measurement tool for complex scientific experiments?
"Exploratory Causal Inference in SAEnce" proposes a workflow for turning learned sparse representations into exploratory treatment-effect hypothesis testing — with theory and successful translation to experimental ecology.
https://t.co/NlonkuheSQ
🎤 Oral — Session 3F, Fri Apr 24, 11:18am
📌 Poster — Pavillon 3 #105, Fri Apr 24, 3:15–5:45pm
See you in Rio 🇧🇷
Excited to present our work at #ICLR2026 🇧🇷
Join us on Saturday to explore how dynamical systems emerge in neural network latent spaces and what the resulting vector field reveal about the model and the data🌀
Oral: Sat, Hall 203 A/B, 11:06 AM
Poster: Sat, P3 #602, 3-5:45 PM
So excited to finally share this!
Linear probes often outperform SAEs, especially out-of-distribution (OOD). @thesubhashk@JoshAEngels et al showed this convincingly (https://t.co/qZtEeId75Y). This prompted @NeelNanda5 and others to de-emphasize SAE research. Empirically, fair enough. But we think the theoretical case for dictionary learning was dismissed too quickly.
@oneill_c previously showed SAEs can't do proper sparse coding (https://t.co/aCCUgL37si). @shruti_joshi@vpacela and @isacama_phys took this further and showed how this leads to problems particularly in OOD settings. So the issue may not be with dictionary learning itself, but with the current tools.
Here's the core argument: if neural representations are in superposition, i.e. more features than dimensions encoded linearly (https://t.co/ruCrSPtN4U), then linear probes fundamentally cannot be the answer.
This is a compressed sensing problem. There's a linear measurement (the representation) and a nonlinear inference procedure (like an SAE encoder) that recovers the higher-dimensional sparse signal. Linear algebra tells us error-free recovery is impossible if decoding is restricted to be linear. (but see this cool work if errors are acceptable https://t.co/lZDnWgodaE)
Check out our video: We have some neat demonstrations here. A linear decision boundary in 3D becomes nonlinear in 2D, even though all sparse combinations of latents remain distinguishable. Compressed sensing works: we can, in principle, recover the high-dimensional latent space where linear probes work and generalize OOD.
Where does this leave us? With finite data and millions of concepts, simpler methods may perform better for a while. But if we want interpretability and safety methods that work OOD, especially compositional generalization covering all possible jailbreaks and real-world failures, we'll have to build bottom up from the right theory.
@kennylpeng@thebasepoint@tegmark@yash_j_sharma@woog09@livgorton@EkdeepL@thomas_fel_@nsaphra
SAEs fail at OOD tasks. Why?
Features in superposition are linearly representable but not linearly accessible. Instead of discarding sparse coding, we embrace the geometry of superposition and use methods equipped to handle the nonlinearity it induces.
[9/9] Bonus: exact modular unlearning comes for free!
The global model is a discrete union of independent generative modules, one per client per class.
To forget a client? Delete their column. To erase a class? Delete its row. No retraining. No approximations. True right-to-be-forgotten compliance.
[1/9]🏭 FederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
- No pretrained models.
- No raw data sharing.
- One communication round.
- It works when clients hold a completely different class of data.
Preprint and code links in the comments 👇
[8/9] Results:
📊 CIFAR-10 Acc: 11.36% → 90.57%
📊 ISIC2019 AUROC: 47.31% → 90.57%
📊 BloodMNIST Acc: 18.05% → 91.17%
📊 RetinaMNIST Acc: 43.50% → 49.30%
📊 PathMNIST Acc: 18.05% → 67.94%
All matching the centralized upper bound, the performance you'd get if you could just pool all the data.
+) Communication overhead: -99.4%!














![ChrisInterno's tweet photo. [9/9] Bonus: exact modular unlearning comes for free!
The global model is a discrete union of independent generative modules, one per client per class.
To forget a client? Delete their column. To erase a class? Delete its row. No retraining. No approximations. True right-to-be-forgotten compliance.](https://pbs.twimg.com/media/HEVhonMWAAAUbb0.jpg)
![ChrisInterno's tweet photo. [1/9]🏭 FederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
- No pretrained models.
- No raw data sharing.
- One communication round.
- It works when clients hold a completely different class of data.
Preprint and code links in the comments 👇](https://pbs.twimg.com/media/HEV6fZQXoAALiy0.jpg)
![ChrisInterno's tweet photo. [8/9] Results:
📊 CIFAR-10 Acc: 11.36% → 90.57%
📊 ISIC2019 AUROC: 47.31% → 90.57%
📊 BloodMNIST Acc: 18.05% → 91.17%
📊 RetinaMNIST Acc: 43.50% → 49.30%
📊 PathMNIST Acc: 18.05% → 67.94%
All matching the centralized upper bound, the performance you'd get if you could just pool all the data.
+) Communication overhead: -99.4%!](https://pbs.twimg.com/media/HEVhDxbbYAMLCj5.jpg)





























