Fast Byte Latent Transformer is accepted to ICML 2026! ⚡🥪
Byte-level LMs promise to free us from subword tokenizers, but decoding one byte at a time is super slow.
We make BLT generation more efficient with BLT-D: text diffusion for parallel byte decoding. 1/
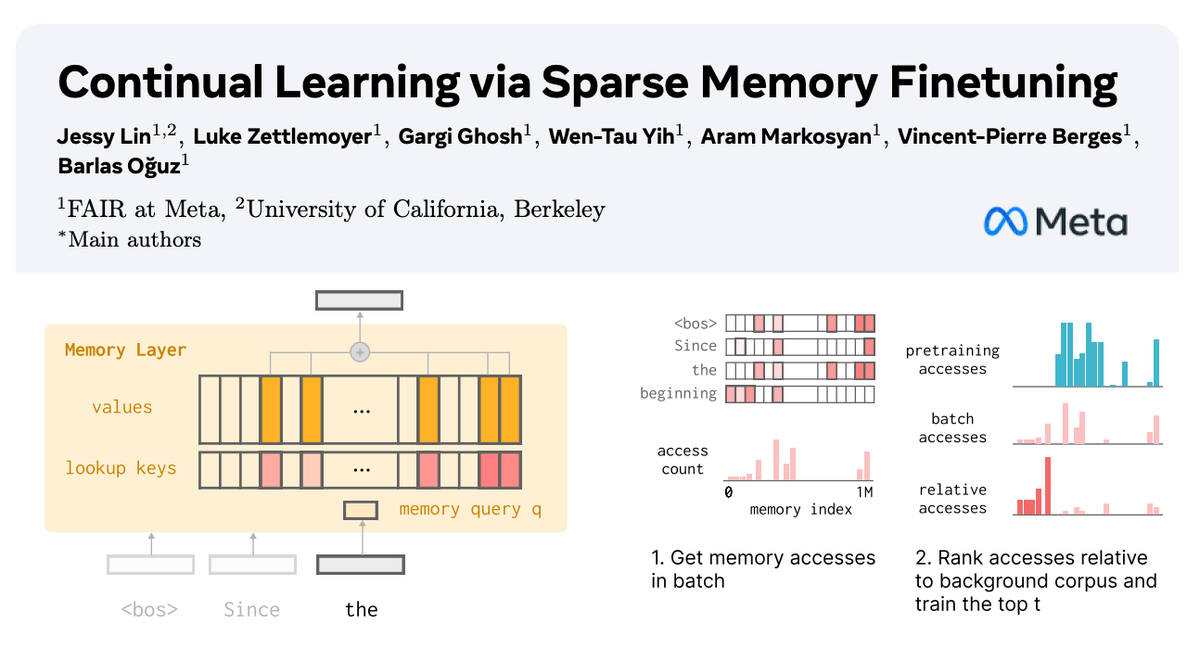
🧠 How can we equip LLMs with memory that allows them to continually learn new things?
In our new paper with @AIatMeta, we show how sparsely finetuning memory layers enables targeted updates for continual learning, w/ minimal interference with existing knowledge.
While full finetuning and LoRA see drastic drops in held-out task performance (📉-89% FT, -71% LoRA on fact learning tasks), memory layers learn the same amount with far less forgetting (-11%).
🧵:
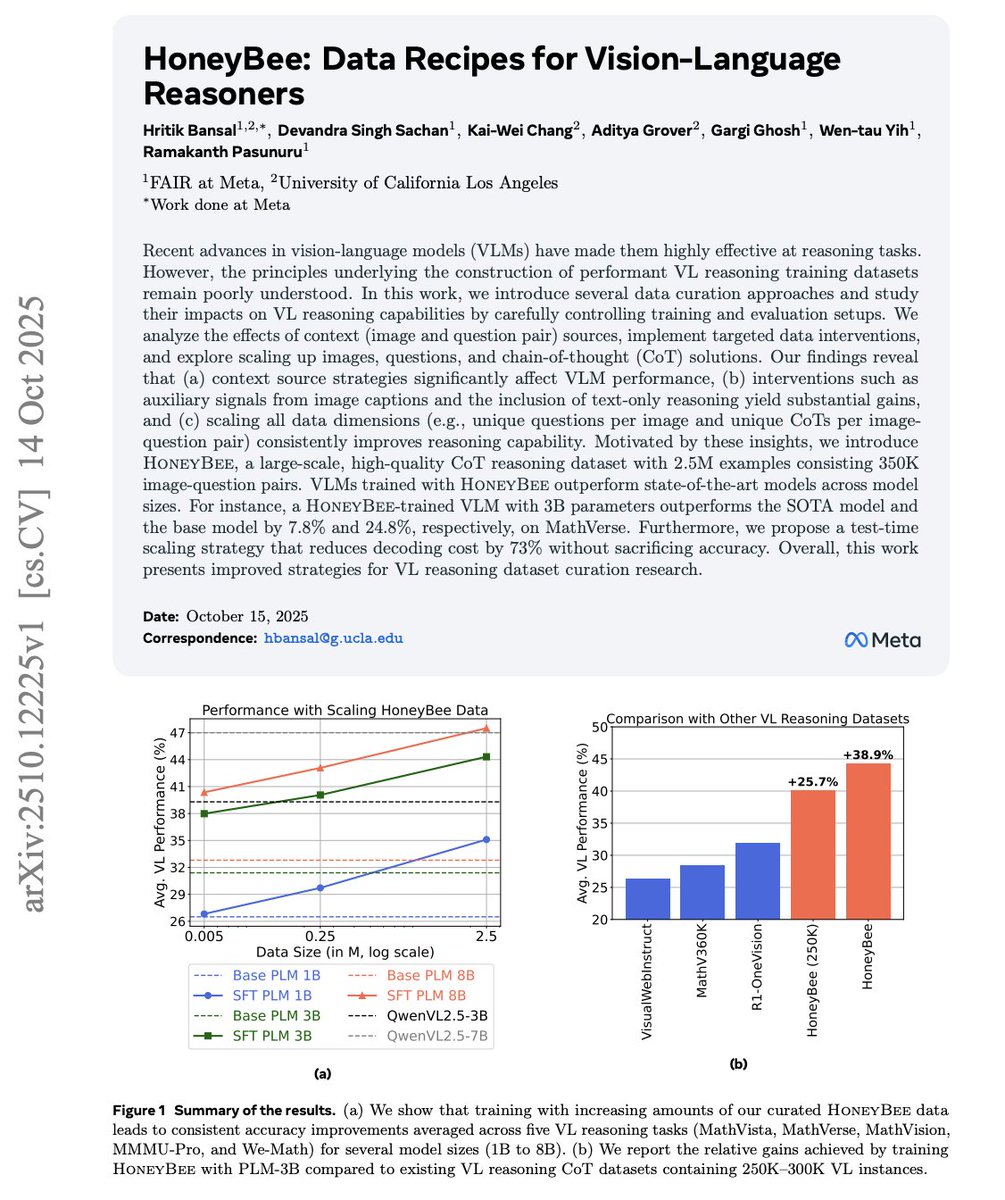
Meet HoneyBee: Our new 2.5M sample multi-modal reasoning dataset. It outperforms InternVL2.5/3-Instruct and Qwen2.5-VL-Instruct. More details in this post!
New paper 📢 Most powerful vision-language (VL) reasoning datasets remain proprietary 🔒, hindering efforts to study their principles and develop similarly effective datasets in the open 🔓.
Thus, we introduce HoneyBee, a 2.5M-example dataset created through careful data curation. It trains VLM reasoners that outperform InternVL2.5/3-Instruct and Qwen2.5-VL-Instruct across model scales (e.g., an 8% MathVerse improvement over QwenVL at the 3B scale). 🧵👇
Work done during my internship at @AIatMeta w/ 🤝 @ramakanth1729, @Devendr06654102, @scottyih, @gargighosh, @adityagrover_, and @kaiwei_chang.
New research from FAIR- Active Reading: a framework to learn a given set of material with self-generated learning strategies for generalized and expert domains(such as Finance). Absorb significantly more knowledge than vanilla finetuning and usual data augmentations strategies
BLT model weights are out!
Responding to popular demand, we just open-sourced model weights for our 1B and 8B BLT models for the research community to play with!
https://t.co/XQsYrM9GqK
Hoping to see many new and improved BLT based architectures this year!
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯
Paper 📄 https://t.co/5QGrlJdK0y
Code 🛠️ https://t.co/jCdDI5BXwe
Super excited to open-source Chameleon 7B and 34B model weights today. These early-fusion models can understand and generate any sequence of interleaved images and text!
Image-gen capabilities are masked for safety reasons, but everything else is enabled. Happy fine-tuning!
Today is a good day for open science.
As part of our continued commitment to the growth and development of an open ecosystem, today at Meta FAIR we’re announcing four new publicly available AI models and additional research artifacts to inspire innovation in the community and help advance AI in a responsible way. More in the video from @jpineau1.
What we’re releasing:
🦎 Meta Chameleon
7B & 34B language models that support mixed-modal input and text-only outputs.
🪙 Meta Multi-Token Prediction
Pretrained Language Models for code completion using Multi-Token Prediction.
🎼 Meta JASCO
Generative text-to-music models capable of accepting various conditioning inputs for greater controllability. Paper available today with a pretrained model coming soon.
🗣️ Meta AudioSeal
An audio watermarking model that we believe is the first designed specifically for the localized detection of AI-generated speech, available under a commercial license.
📝 Additional RAI artifacts
Including research, data and code to measure and improve the representation of geographical and cultural preferences and diversity in AI systems.
We believe that access to state-of-the-art AI creates opportunities for everyone – not just a small handful of Big Tech companies. We’re excited to share this work and to see how the community learns, iterates and builds using this technology.
Details and access to everything released by FAIR today ➡️ https://t.co/aMY8d2qrTd
Excited to release our work from last year showcasing a stable training recipe for fully token-based multi-modal early-fusion auto-regressive models! https://t.co/H0wOurpeuC Huge shout out to @ArmenAgha@ramakanth1729@LukeZettlemoyer@gargighosh and other co-authors. (1/n)
Newly published work from FAIR, Chameleon: Mixed-Modal Early-Fusion Foundation Models.
This research presents a family of early-fusion token-based mixed-modal models capable of understanding & generating images & text in any arbitrary sequence.
Paper ➡️ https://t.co/6l4uICXr3b
The ART of LLM Refinement: Ask, Refine, and Trust
Achieves a performance gain of 5 points over self-refinement baselines, while using a much smaller model as the decision maker
https://t.co/nCzgJ7GWtE
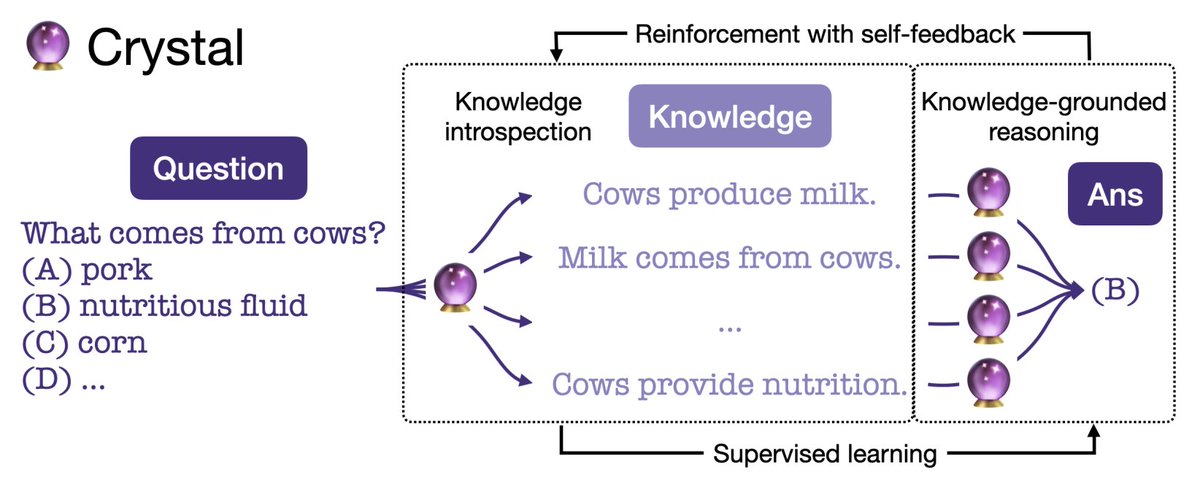
Introducing 🔮Crystal🔮, an LM that conducts “introspective reasoning” and shows its reasoning process for QA. This improves both QA accuracy and human interpretability => Reasoning made Crystal clear!
https://t.co/NFO5zTCNAz
Demo: https://t.co/rOsFehWlhU
at #EMNLP2023
🧵(1/n)
Long context models are popular, but is it the final solution to long text reading?
We introduce a fundamentally different method, MemWalker:
1. Build a data structure (memory tree)
2. Traverse it via LLM prompting
Outperforms long context, retrieval, & recurrent baselines. (1/n)
What if we combine PPO with Monte-Carlo Tree Search – the secret sauce for AlphaGo to reach superhuman performance?
Spoiler: MAGIC!! Our inference-time decoding method, PPO-MCTS, achieves impressive results across many text generation tasks.
📜 https://t.co/akCS8ZBQ1V
🧵(1/n)
I’m excited to release our most recent work setting a new SOTA FID of 4.88 on text-to-image generation we call CM3Leon (pronounced chameleon)! https://t.co/KEGNFqFt3l
Our paper on 𝐩𝐫𝐨𝐦𝐩𝐭𝐢𝐧𝐠 𝐋𝐋𝐌𝐬 𝐰𝐢𝐭𝐡 𝐞𝐱𝐩𝐥𝐚𝐧𝐚𝐭𝐢𝐨𝐧𝐬 is accepted at Findings of #ACL2023NLP
Check out our poster at the 𝐍𝐋𝐑𝐒𝐄 𝐰𝐨𝐫𝐤𝐬𝐡𝐨𝐩 𝐨𝐧 𝐓𝐡𝐮𝐫𝐬𝐝𝐚𝐲. I won't be there in person😢 but you can say hi to my advisor @gregd_nlp 😆