@ivrik Kat, I'm infinitely sad reading this. May you, Andreas, and your son, find the strength to go through this, and may Lea continue her loving life in a better world.
Our #WMT2025 paper got accepted 🙌
We release a dataset for health low-res MT... and find that Gemini 2.5 beats NLLB 54B, if given full document context.
Seeya in Suzhou!
Did you know?
❌77% of language models on @huggingface are not tagged for any language
📈For 95% of languages, most models are multilingual
🚨88% of models with tags are trained on English
In a new blog post, @tylerachang and I dig into these trends and why they matter! 👇
@davlanade@SenyuLiReal@alabi_jesujoba Really cool work, the AfriDoc-MT paper in particular is a trove of interesting findings on doc Vs sent level translation in low-res MT
paper: https://t.co/e8mIA9e5EC
demo: https://t.co/jlYphZa9h6
Grateful for all the help and advice from my supervisors Hanna Suominen, Nick Thieberger, Trevor Cohn, Katerina Vylomova, and special thanks to Maluk Timor & Lois Hong for the great joint work!
in Vienna for ACL, presenting Tulun, a system for low-resource in-domain translation, using LLMs
Working w 2 real use cases: medical translation into Tetun 🇹🇱 & disaster relief speech translation in Bislama 🇻🇺
Our paper on generating bilingual example sentences with LLMs got best paper award @altanlp !
https://t.co/pAULq5bv5f
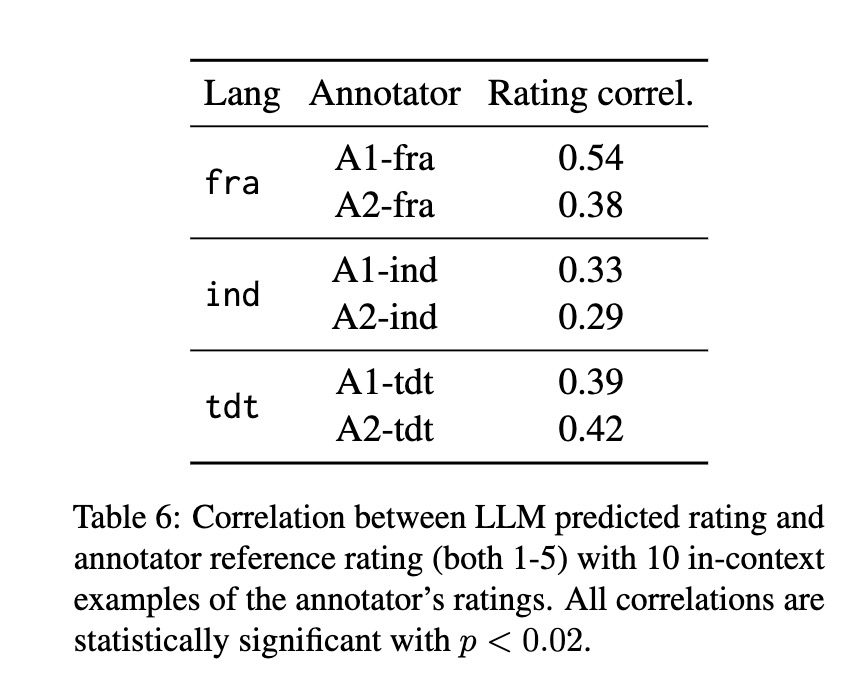
We work with French / Indonesian / Tetun, find that annotators don't agree about what's a "good example", but that LLMs can align with a specific annotator.
@KushalTatariya@akulmizev@EstherPloeger@mmbollmann@johannesbjerva @heather_nlp @mdlhx@lagom_nlp Really nice paper, definitely saving this as inspiration for work on data quality!
For §5, you maybe you'd have seen more correlation btw quality & performance on NLG tasks, instead of NLU? As NLG would suffer from low-quality training data, more than NLU, I think?
@sethjsa@davidstap@diwuNLP@c_monz@illc_amsterdam@ltl_uva Super interesting!
In a similar vein, we studied MT using LLMs w sentences from a language manual for Mambai, and found that while scores were decent on test sentences sampled from the manual, it collapsed on sentences translated by a native speaker: https://t.co/vbFqG4xUKF
Translation is a complex task involving pre-translation research and post-translation stages. Can #LLMs handle this process step-by-step, relying solely on their internal knowledge?
✨We show that decomposing the translation process significantly improves #Gemini translation quality of long-form texts across all #WMT24 languages!
📜https://t.co/6JkRQwAsN2