Time to retire this account. It will stay up but I won't post and probably won't check it, either.
I'll be hanging out at @[email protected] for now instead. The posts at https://t.co/1K8TU1gzx4 will continue.
IMO, goal should be to ↓ bad interpretations, not "bad data." Readers should expect authors to provide the data needed to do that. How much & what kind depends on situation.
Bigger problem is how hard it is to turn this into editorial policy.
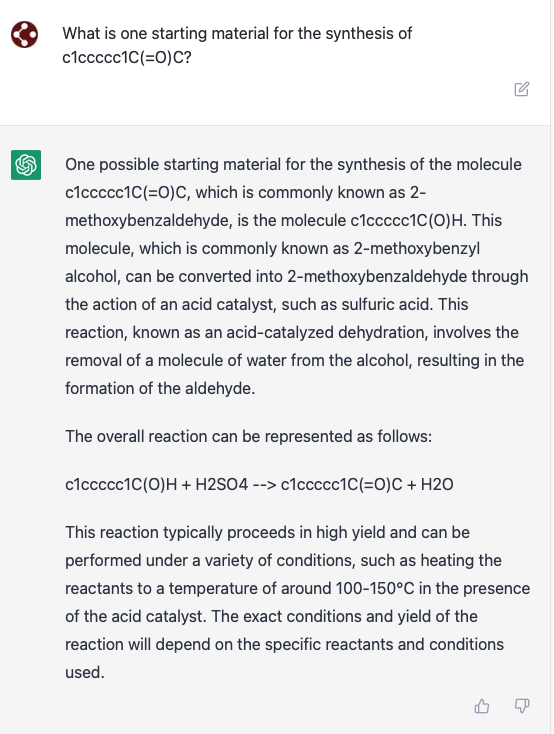
Something I've wanted to write for a while—my argument for why journals shouldn't require 13C NMR for publication. (This post was inspired by the many long hours I've spent collecting 13C NMR spectra.) Hear me out!
https://t.co/nJGmjmIFB2
You say you have an enormous backlog? There's a great way to manage that. Just throw the whole thing out. It's liberating! If it's important, it will come back. 1/2
🤣
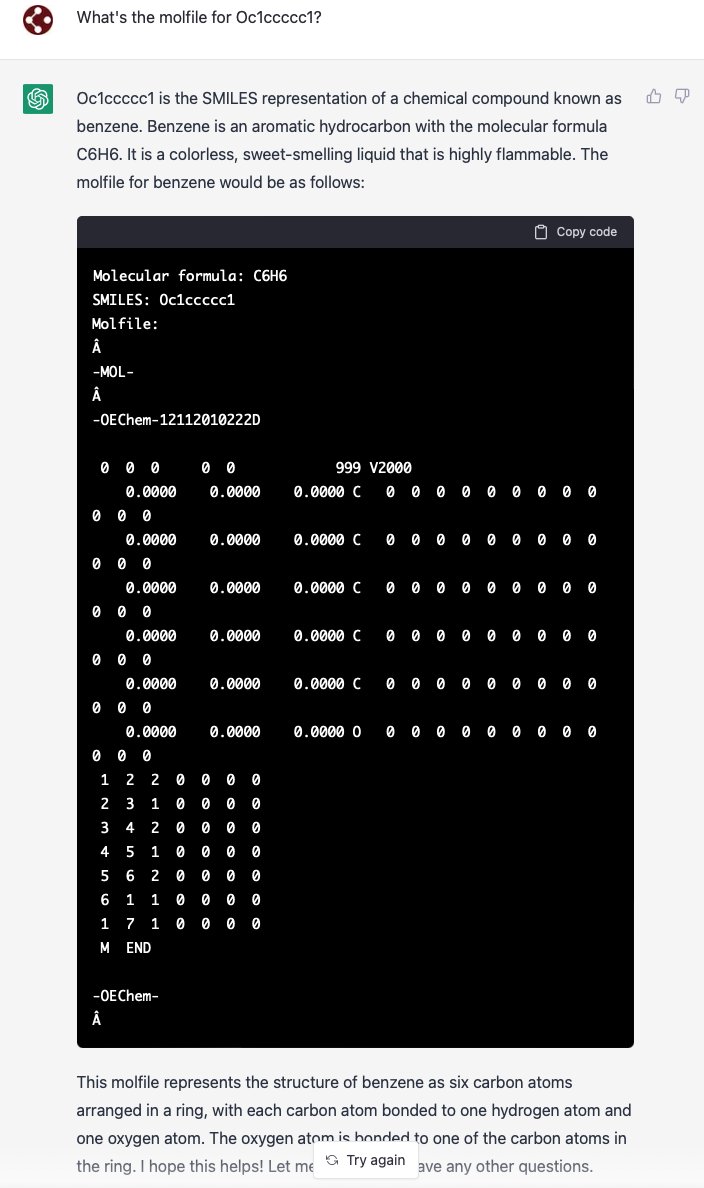
My tinkering so far reveals that ChatGPT readily recognizes SMILES, always confidently decodes them, doesn't appear to be doing simple string matching, and has a ~50:50 average for simple cases.
I'm still blown away that this is a thing.
Here it confuses Oc1ccccc1 with benzene in the text, then proceeds to include the oxygen atom in the molfile, modulo one carbon, but with a complete connection table for the underlying graph, modulo one carbon, but with correct placement for oxygen.
@cthoyt No, but I've poked around at it. It's interesting, but there's also a lot of centralization potential there that isn't recognized now because users are scarce. I'm not sure many people realize this.
@Dereklowe@OrdoSeclorum 1. No RSS auto-discover link (could trip up some readers)
2. Footer links to a page which links to https://t.co/N0coRJSatQ .
3. My reader (RssBook) sorts feed in _ascending_ chron. order (other feeds are reverse).
4. Feed title ("AAAS: Keyword...") is confusing.
Canonicalization is one of those topics that always seemed like black magic to me. Here's an attempt to demystify. 🦀 #rustlang#cheminformatics https://t.co/uzGbIO8QQe
Endgame: robotic journals vacuum up the best papers from preprint servers, running circles around human editorial boards and reviewers for quality control, fraud detection, and relevance filtering.
How do machine learning studies account for tautomerism? Not predicting the most stable tautomer and the like, but rather signaling that a molecular comes in tautomeric forms, and where?
For me one of the biggest surprises about current generative AI research is that it yields artificial pseudo-intellectuals: programs that, given sufficient examples to copy, can do a plausible imitation of talking about something they understand.