Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: https://t.co/7hixC7FNg7
Paper:https://t.co/t1nHSJgGwB
Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.
🚀 Excited to release mKernel: a set of fast multi-node, multi-GPU fused kernels.
💻 Code: https://t.co/y2WfdMVTfC
📝 Blog: https://t.co/wGomxmeRxr
mKernel fuses compute + communication into one persistent GPU kernel, covering both intra/inter-node with GPU-initiated communication.
Amazing team: @yangzhouy, Chon Lam Lao, Costin Raiciu, Scott Shenker, @istoica05
The new White House policy requiring green card applicants to apply from outside the US is a capricious attack on legal immigration. It will hurt families, leave us with fewer doctors, teachers and scientists, and hurt American competitiveness in AI.
After some mathematical rewrite, turns out all of transformer is a series of gemm + epilogue. Given a few optimized primitives, LLMs (and novice humans) can write speed-of-light kernels for all transformer ops!
As we've come to expect from a DeepSeek release, DeepSeek V4 comes with more flashy ML systems optimizations. This time? MegaMoE, a 1400 line fused CUDA kernel that computes the entire MoE forward pass. Let's see how it works (1/4) 🧵
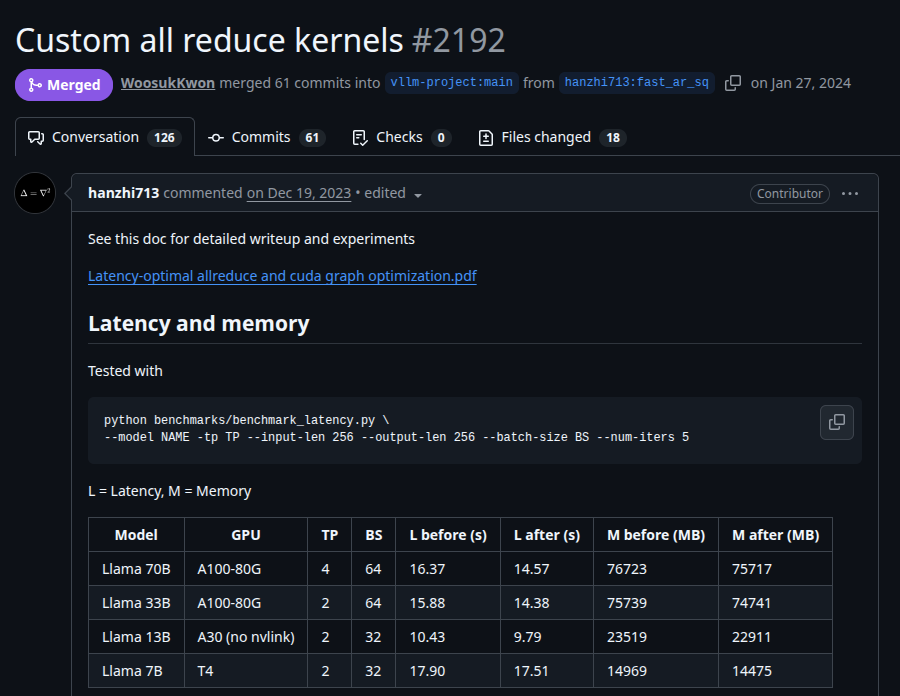
Not many know but the GOAT that created the custom allreduce kernel that runs everyone's decode since 3 years wrote a doc explaining the background and algorithims behind it. Give it a read
DeepSeek-V4 RoPE Design In-Depth Analysis 🔍
Key technical insights curated from Zhihu contributor kaiyuan 🧩
Core Pain Points of RoPE in DeepSeek-V4 🚨
DeepSeek-V4 leverages RoPE as its positional encoding scheme.
However, its upgraded attention architecture raises two fundamental design challenges:
• CSA & HCA adopt token compression, merging multiple tokens into one critical representation. The key question: inject RoPE before or after token compression?
• The attention layer runs on MQA mode with shared KV representation. Directly applying RoPE rotation to KV will leak positional information into value matrix V — how to resolve this contamination?
💡This breakdown unpacks how DeepSeek-V4 solves RoPE layout around these two dilemmas.
RoPE Design Legacy: MLA Mechanism Recap 📚
✔ Background of MLA Constraints
Before analyzing V4, we first review the MLA (Multi-head Latent Attention) adopted in DeepSeek-V2/V3.
MLA already encounters the same MQA sharing and KV cache compression issues seen in V4.
✔ Hidden Defect of Shared KV Cache
In MLA, downsampled K and V share identical cache weights to cut VRAM usage.
The downside: if RoPE is applied to K, V will be rotated together, making V mixed with irrelevant positional information.
✔ MLA Compromise Solution
The straightforward fix is splitting K and V, only rotating K — yet this needs separate K/V cache storage, bringing overhead close to GQA.
💡MLA uses an optimized workaround:
Reserve a dedicated portion of Q and K hidden dimensions solely for RoPE computation.
This keeps positional signals inside K only, avoids polluting V, and only stores lightweight RoPE-related K cache — far more efficient than full K/V separation.
RoPE Implementation in CSA & HCA ⚙️
Unified Design Logic of CSA & HCA
DeepSeek-V4’s CSA and HCA both face KV cache compression and MQA shared KV troubles.
The two modules follow identical RoPE processing logic; the following takes HCA as the typical case.
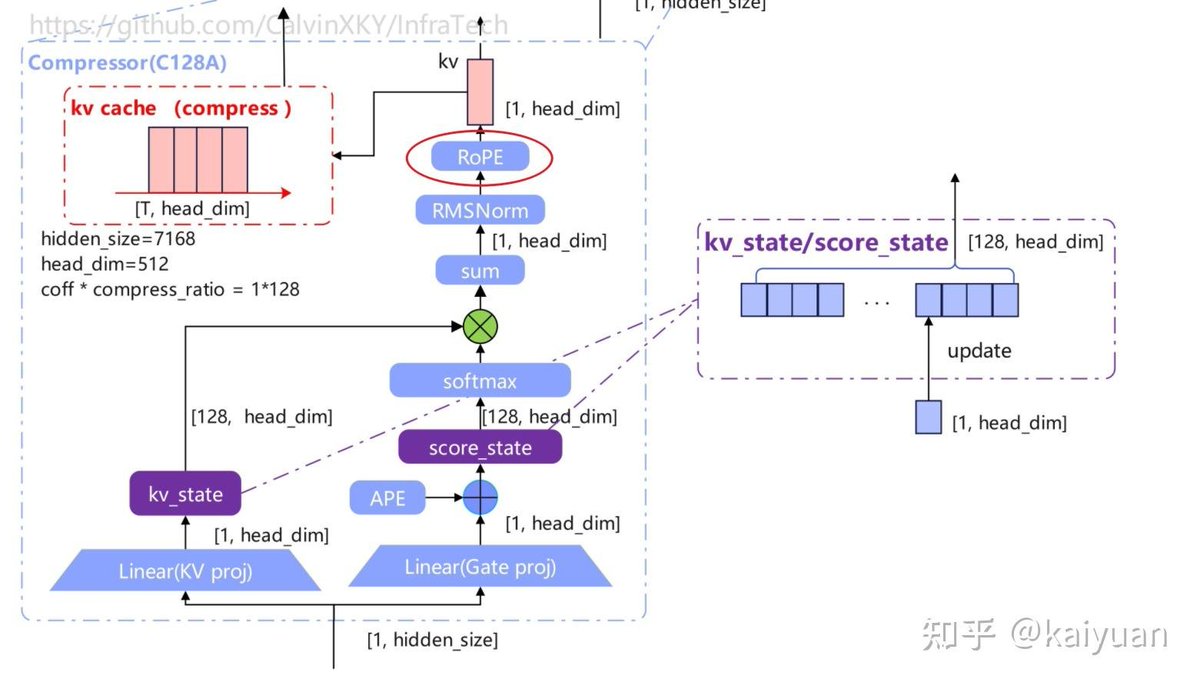
Key Modules Involved in HCA RoPE
Four core parts participate in positional encoding:
• KV features from sliding window attention (SWA)
• Compressed KV output from C128A compressor
• Upsampled query Q features
• Final attention output matrix O
Why Apply Extra Rotation to Output 💡
Root Cause of Absolute Position Bias
In shared KV structure, direct RoPE rotation inevitably introduces positional noise into V.
HCA only applies RoPE on the final rope_head_dim of window-channel and compressed-channel KV.
This operation brings obvious absolute position information into attention output.
Drawback of Absolute Position Encoding
Absolute position lacks stability, especially for long context extrapolation, far inferior to relative position encoding in scalability.
Inverse Rotation Optimization
HCA adds an inverse rotation on final output O, converting absolute position expression back to standard relative position form.
Simple forward rotation cannot fix the issue — it still keeps the model bound to absolute position logic.
Why RoPE Cannot Be Applied Directly to Matrix P ❌
Dimension Mismatch
Matrix V follows the dimension layout of sequence and attention head.
Matrix P is only a sequence-to-sequence weight matrix with no head dimension.
RoPE rotates along head hidden dimension, which matrix P does not have at all.
Computational Essence
Mathematically, PV calculation equals scalar weights multiplied by feature vectors.
P is just a set of scalar weights, with no rotatable vector dimension to support RoPE.
RoPE Timing: Before Compression or After Compression 📌
RoPE Position Index Rule
RoPE rotation angle is strictly tied to absolute token position index.
C128A compresses 128 raw KV states into one single compressed KV token, and QK similarity calculation uses only the compressed K.
The core debate: how to assign valid position index for compressed K.
Option 1: Rotate Before Compression
Rotate every original token with RoPE first, then execute compression.
Though logically intuitive, positional signals will be mixed and accumulated along the sequence dimension, destroying the relative position structure required by RoPE.
Option 2: Rotate After Compression
Assign a unified calibrated position anchor for each compressed K token.
The anchor can be segment start, end or midpoint — only needing consistent mapping rules globally.
🧠DeepSeek-V4 Final Choice
HCA selects the starting position of each 128-token segment as the position anchor for compressed K RoPE rotation.
#DeepSeekV4 #RoPE #LLMArchitecture #TransformerOptimization #AI
🔗Full article:
https://t.co/EXZyAA8Q9W
deepseek-v4 is out and solves context rot at 1M tokens by taking on attention for the kv cache.
It's big at 1T Params, has massive context, and importantly, maxes that context out like nothing else in the open. it is a step change for long horizon tasks.
tbf, we are not seeing SOTA scores allround, but it is solving the main weakness that everyone is experiencing in non-opus models. they stop and we need to reprompt.
deepseek do this by attacking long-context inference cost.
1m context is useless if every token turns into a kv-cache invoice.
Today President Trump told a reporter:
“The Iranian people want to be free. They have lived in a world that you know nothing about.”
No truer statement was ever said to a reporter covering Iran.
The IRGC is now openly recruiting 12-year-olds in plain violation of its international legal obligations.
Sending children to perform military duties with AK-47s isn’t "defending the homeland"—it’s horrific, plain and simple.
The Iranian regime has reached a new level of desperation and depravity.
The world must stop treating these terrorists like a legitimate government.
https://t.co/8De2VsLvyi
The Iranian regime has killed 45,000+ of its own citizens.
They’ve killed thousands of Americans over 47 years.
President Trump is making America and the world a safer place.
به سرداران سپاه پاسداران انقلاب اسلامی!
امروز کمتر کسی تردید دارد که از نظام ولایت فقیه جز جسمی نیمهجان باقی نمانده است، و تصمیمگیران واقعی این ساختمان در حال ریزش، در نتیجه پنج دهه ماجراجویی و جنایت، شمایید.
سیاستهای غلط منطقهای و دیوانگیهای آخرالزمانی شما، ایران را به صحنه این جنگ بدل کرده است. زیرساختهای اقتصادی که عمدا نظامیسازی کردهاید، در تیررس دو قدرتی قرار گرفتهاند که هفتههاست در آسمان ایران جولان میدهند. این زیرساختها با ثروت ملی ایران ساخته شدهاند و برای بازسازی کشور حیاتیاند.
نظام فاسد جمهوری اسلامی رفتنی است. انتخاب شما میان بقا و سقوط نیست؛ میان چگونه سقوط کردن است. پایان مسیر کنونی، تحویل یک سرزمین سوخته به ملت ایران پس از سقوط حتمیتان است.
برای ایران، برای خودتان، برای فرزندانتان، این ماجراجوییها را رها کنید. ایران را بیش از این خونآلود و زخمی نکنید. بگذارید زیرساختهای کشور برای ملت ایران حفظ شود. به جنایتهایتان پایان دهید. از حکومت کناره بگیرید.
تروریستهای جنایتکار حشدالشعبی با پرچم عراق به قصد هراسافکنی و کشتار در خیابانها و میادین ایران مستقر شدهاند، جولان میدهند و رجز میخوانند. آنچه رژیم بعثی صدام در هشت سال جنگ نتوانست بر ایران تحمیل کند، امروز رژیم جنایتکار اسلامی بر ملت ایران تحمیل کرده است.
این، اوج رسوایی یک نظام ضدایرانی است که برای بقای خود، کشور را به دست بیگانگان سپرده است. این، پایمال کردن غرور یک ملت، و توهین آشکار به خون مدافعان وطن در جنگ هشتساله با عراق است.
شرم بر هر آن کسی که در کسوت نظامی در کنار تروریستهای متجاوز حشدالشعبی و روبروی ملت بزرگ ایران میایستد.
ارتش ایران کجاست؟ کهنهسربازان جنگ هشتساله با عراق کجایند؟ غیرت نظامی ایرانی کجا رفته است که تروریستهای عراقی از خوزستان تا تهران بر مال و جان و ناموس ایرانیان حاکم شدهاند.
حشدالشعبی و دیگر شبهنظامیان عراقی، نیروی متجاوز و اشغالگرند. جای آنان در ایران نیست. باید بیدرنگ از خاک پاک ایران بیرون رانده شوند.
پاینده ایران،
رضا پهلوی