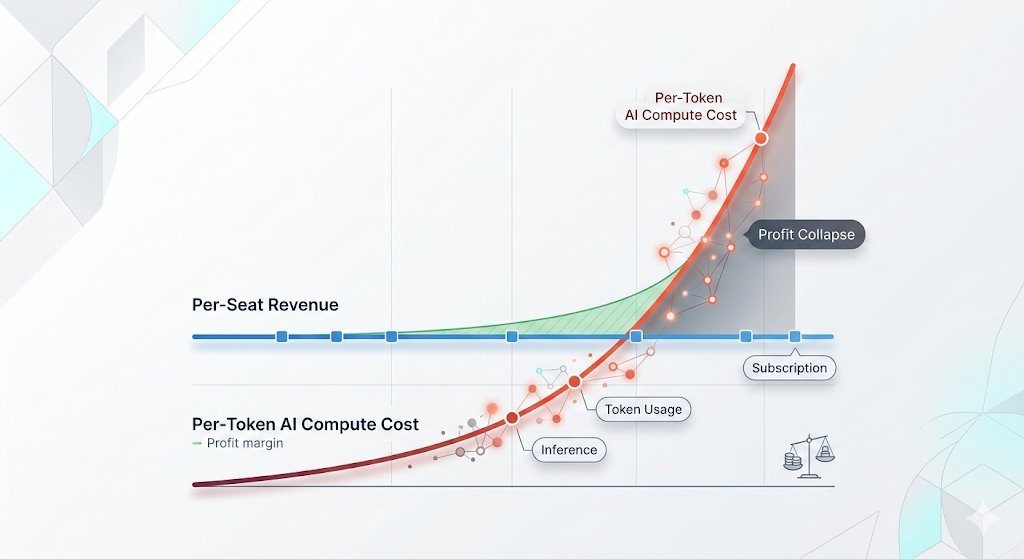
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
@random_walker To add, the grammar for coding languages are stricter than human language counter parts. This leaves very few options in the prob space for generating - making inference more repeatable and accurate. Learning such (almost) rule based system should be easier for a “large” LM.
Solving from memory vs solving from scratch--Or the Futility of applying "Complexity Lens" to LLMs #SundayHarangue#NeurIPS2025 Edition
I continue to be puzzled by the insistence on viewing LLM task performance in terms of the computational complexity of the underlying task (see https://t.co/4X1yQFY3KH ).
This despite the plenty of anecdotal evidence already showing that the Jagged Intelligence of LLMs has no direct connection to task complexity. LLMs can be competitive on International Mathematical Olympiad problems, while still falling for "Amazon sent me a left shoe instead of a right shoe, and vice versa" juvenile gotcha's (y'all should follow @conitzer for a seemingly never ending list of these gotchas for SOTA LLMs!).
Computational complexity is often in terms of solving a task algorithmically from scratch. Everything in pre-training, post-training and inference in LLMs instead screams solving from memory.
Of course, this doesn't mean that LLMs are just directly retrieving the solution to an individual task prompt from a large library of previous solutions. It is that they are trying to trying to address the task prompt not by solving it algorithmically from scratch, but by some trial-and-error process of composing knowledge gleaned from pre- and post-training on human knowledge.
From this perspective, the "intermediate tokens" output by the reasoning models are to be interpreted not as traces of some from-scratch algorithm, but perhaps as a footprint of the model's attempts to compose the prior knowledge in its memory to address the current task prompt.
(As I argue else where, https://t.co/qE0vAwB636, pre-training can be seen as ingesting humanity's declarative knowledge, while post-training can be seen incrementally ingesting humanity's procedural knowledge--in terms of ever longer unrollings of the procedures).
The cost/accuracy of such compositional trial-and-error problem solving is based not on the from-scratch computational complexity of the current task prompt, but rather how easy it is to assemble a solution for it from the current memory. This is why LLMs suffer low accuracy on tasks that are far from the pre- and post- training distribution. See https://t.co/RL9ZEOKbpQ.
A tell-tale sign of memory-based problem solving is that the model might have both low accuracy as well as longer intermediate tokens ("computation") when the problem is out of the training distribution--even if it is in fact trivially solvable from scratch. This is the message of our "Peformative Thinking" paper--https://t.co/itCXNctKZ1 -- to be presented at the #NeurIPS2025 Efficient Reasoning workshop.
New on the Anthropic Engineering blog: writing effective tools for LLM agents.
AI agents are only as powerful as the tools we give them. So how do we make those tools more effective?
We share our best tips for developers: https://t.co/N1kFYrTtax
You won’t get fired.
You’ll just get less relevant.
The AI won’t replace you all at once.
It’ll do 5% of your job, then 15%, then 40%.
And at every step, your manager will say, “It’s just helping.”
But eventually, you’re no longer the operator.
You’re the overseer. Then the observer. Then… gone.
This doesn’t end with pink slips. It ends with dashboards where you watch your replacement outperform you, 24/7, with zero complaints.
So what can you do?
You become the one who builds.
Not the prompt monkey. Not the API glue guy.
You become the architect of systems, not a cog inside them.
Learn to:
-Identify what should be automated (not just what can be)
-Design AI implementations for others (before someone does it to you)
-Own data. Own distribution. Own the interface.
The cognitive era doesn’t reward labor. It rewards leverage.
GPT 4.5 + interactive comparison :)
Today marks the release of GPT4.5 by OpenAI. I've been looking forward to this for ~2 years, ever since GPT4 was released, because this release offers a qualitative measurement of the slope of improvement you get out of scaling pretraining compute (i.e. simply training a bigger model). Each 0.5 in the version is roughly 10X pretraining compute. Now, recall that GPT1 barely generates coherent text. GPT2 was a confused toy. GPT2.5 was "skipped" straight into GPT3, which was even more interesting. GPT3.5 crossed the threshold where it was enough to actually ship as a product and sparked OpenAI's "ChatGPT moment". And GPT4 in turn also felt better, but I'll say that it definitely felt subtle. I remember being a part of a hackathon trying to find concrete prompts where GPT4 outperformed 3.5. They definitely existed, but clear and concrete "slam dunk" examples were difficult to find. It's that ... everything was just a little bit better but in a diffuse way. The word choice was a bit more creative. Understanding of nuance in the prompt was improved. Analogies made a bit more sense. The model was a little bit funnier. World knowledge and understanding was improved at the edges of rare domains. Hallucinations were a bit less frequent. The vibes were just a bit better. It felt like the water that rises all boats, where everything gets slightly improved by 20%. So it is with that expectation that I went into testing GPT4.5, which I had access to for a few days, and which saw 10X more pretraining compute than GPT4. And I feel like, once again, I'm in the same hackathon 2 years ago. Everything is a little bit better and it's awesome, but also not exactly in ways that are trivial to point to. Still, it is incredible interesting and exciting as another qualitative measurement of a certain slope of capability that comes "for free" from just pretraining a bigger model.
Keep in mind that that GPT4.5 was only trained with pretraining, supervised finetuning, and RLHF, so this is not yet a reasoning model. Therefore, this model release does not push forward model capability in cases where reasoning is critical (math, code, etc.). In these cases, training with RL and gaining thinking is incredibly important and works better, even if it is on top of an older base model (e.g. GPT4ish capability or so). The state of the art here remains the full o1. Presumably, OpenAI will now be looking to further train with Reinforcement Learning on top of GPT4.5 model to allow it to think, and push model capability in these domains.
HOWEVER. We do actually expect to see an improvement in tasks that are not reasoning heavy, and I would say those are tasks that are more EQ (as opposed to IQ) related and bottlenecked by e.g. world knowledge, creativity, analogy making, general understanding, humor, etc. So these are the tasks that I was most interested in during my vibe checks.
So below, I thought it would be fun to highlight 5 funny/amusing prompts that test these capabilities, and to organize them into an interactive "LM Arena Lite" right here on X, using a combination of images and polls in a thread. Sadly X does not allow you to include both an image and a poll in a single post, so I have to alternate posts that give the image (showing the prompt, and two responses one from 4 and one from 4.5), and the poll, where people can vote which one is better. After 8 hours, I'll reveal the identities of which model is which. Let's see what happens :)
Today we’re launching the Anthropic Economic Index, a new initiative aimed at understanding AI's impact on the economy over time.
The Index’s first paper analyzes millions of anonymized Claude conversations to reveal how AI is being used today in tasks across the economy.
“… how many examples do you know of a more intelligent thing being controlled by a less intelligent thing?… Evolution put a lot of work into allowing the baby to control the mother, but that’s about the only example…” - G Hinton: https://t.co/AyNUdENvJc
Impacts Trust in AI:
... e.g., a model initially trained with a partisan bias may later be trained to be neutral, but still secretly retain its original preferences...: https://t.co/qGzOnC1xEt
#trust - #AI - #LLMs
New Anthropic research: Alignment faking in large language models.
In a series of experiments with Redwood Research, we found that Claude often pretends to have different views during training, while actually maintaining its original preferences.
Open science is how we continue to push technology forward and today at Meta FAIR we’re sharing eight new AI research artifacts including new models, datasets and code to inspire innovation in the community. More in the video from @jpineau1.
This work is another important step towards our goal of achieving Advanced Machine Intelligence (AMI).
What we’re releasing:
• Meta Spirit LM: An open source language model for seamless speech and text integration.
• Meta Segment Anything Model 2.1: An updated checkpoint with improved results on visually similar objects, small objects and occlusion handling. Plus a new developer suite to make it easier for developers to build with SAM 2.
• Layer Skip: Inference code and fine-tuned checkpoints demonstrating a new method for enhancing LLM performance.
• SALSA: New code to enable researchers to benchmark AI-based attacks in support of validating security for post-quantum cryptography.
• Meta Lingua: A lightweight and self-contained codebase designed to train language models at scale.
• Meta Open Materials: New open source models and the largest dataset of its kind to accelerate AI-driven discovery of new inorganic materials.
• MEXMA: A new research paper and code for our novel pre-trained cross-lingual sentence encoder with coverage across 80 languages.
• Self-Taught Evaluator: a new method for generating synthetic preference data to train reward models without relying on human annotations.
Access to state-of-the-art AI creates opportunities for everyone. We’re excited to share this work and look forward to seeing the community innovation that results from it.
Details and access to everything released by FAIR today ➡️ https://t.co/P3XkdN2WQN
The Royal Swedish Academy of Sciences has decided to award the Nobel Prize in Chemistry 2024 with one half to David Baker “for computational protein design”, and the other half jointly to Demis Hassabis and John M. Jumper “for protein structure prediction”.
Read more: https://t.co/OXDSRos3Su
#NobelPrize #Nobelprize2024
The Nobel Prize in Physics 2024 is awarded to John J. Hopfield och Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks”
This year’s two Nobel Laureates in Physics have used tools from physics to develop methods that are the foundation of today’s powerful machine learning. John Hopfield created an associative memory that can store and reconstruct images and other types of patterns in data. Geoffrey Hinton invented a method that can autonomously find properties in data, and so perform tasks such as identifying specific elements in pictures.
Read more: https://t.co/DcG000OdWt
@Princeton@Uoft
#NobelPrize #NobelPrize2024
# RLHF is just barely RL
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
What would it look like to train AlphaGo with RLHF? Well first, you'd give human labelers two board states from Go, and ask them which one they like better:
Then you'd collect say 100,000 comparisons like this, and you'd train a "Reward Model" (RM) neural network to imitate this human "vibe check" of the board state. You'd train it to agree with the human judgement on average. Once we have a Reward Model vibe check, you run RL with respect to it, learning to play the moves that lead to good vibes. Clearly, this would not have led anywhere too interesting in Go. There are two fundamental, separate reasons for this:
1. The vibes could be misleading - this is not the actual reward (winning the game). This is a crappy proxy objective. But much worse,
2. You'd find that your RL optimization goes off rails as it quickly discovers board states that are adversarial examples to the Reward Model. Remember the RM is a massive neural net with billions of parameters imitating the vibe. There are board states are "out of distribution" to its training data, which are not actually good states, yet by chance they get a very high reward from the RM.
For the exact same reasons, sometimes I'm a bit surprised RLHF works for LLMs at all. The RM we train for LLMs is just a vibe check in the exact same way. It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. These predictions can look really weird, e.g. you'll see that your LLM Assistant starts to respond with something non-sensical like "The the the the the the" to many prompts. Which looks ridiculous to you but then you look at the RM vibe check and see that for some reason the RM thinks these look excellent. Your LLM found an adversarial example. It's out of domain w.r.t. the RM's training data, in an undefined territory. Yes you can mitigate this by repeatedly adding these specific examples into the training set, but you'll find other adversarial examples next time around. For this reason, you can't even run RLHF for too many steps of optimization. You do a few hundred/thousand steps and then you have to call it because your optimization will start to game the RM. This is not RL like AlphaGo was.
And yet, RLHF is a net helpful step of building an LLM Assistant. I think there's a few subtle reasons but my favorite one to point to is that through it, the LLM Assistant benefits from the generator-discriminator gap. That is, for many problem types, it is a significantly easier task for a human labeler to select the best of few candidate answers, instead of writing the ideal answer from scratch. A good example is a prompt like "Generate a poem about paperclips" or something like that. An average human labeler will struggle to write a good poem from scratch as an SFT example, but they could select a good looking poem given a few candidates. So RLHF is a kind of way to benefit from this gap of "easiness" of human supervision. There's a few other reasons, e.g. RLHF is also helpful in mitigating hallucinations because if the RM is a strong enough model to catch the LLM making stuff up during training, it can learn to penalize this with a low reward, teaching the model an aversion to risking factual knowledge when it's not sure. But a satisfying treatment of hallucinations and their mitigations is a whole different post so I digress. All to say that RLHF *is* net useful, but it's not RL.
No production-grade *actual* RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. It's all fun and games in a closed, game-like environment like Go where the dynamics are constrained and the reward function is cheap to evaluate and impossible to game. But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python? Going towards this is not in principle impossible but it's also not trivial and it requires some creative thinking. But whoever convincingly cracks this problem will be able to run actual RL. The kind of RL that led to AlphaGo beating humans in Go. Except this LLM would have a real shot of beating humans in open-domain problem solving.