Beware of anyone trying to reach out to you for potential investment. @heyitshealy reached out to me talking about some potential investment.
The conversation seemed pretty legit but then he sent me a link. The doc was "encrypted"(the encrypted text was just an image.....) and had their investment information.
He said he was from a company called crowdvc(https://t.co/VpenhCtnUY) and his name was Jatin Rana(https://t.co/VpenhCtnUY). Don't know if the image is AI generated or not.
Anyways, it was basically a phishing payload scam probably something like Torg Grabber.
Beware.
@amarifields_ Hey I am building https://t.co/OvHdoxvPWP and I believe there's a real wedge and a problem i am solving.
Would love to hear any feedback you might have.
For providing better context to AI Copilots .
We use LLMs to analyze every file in your codebase.
Result is 80% less cost and at least 10% accuracy increase.
However This seems a stupid idea because of cost.
Yet LLMs are far, far better for code analysis than vectors or AST parsers, and the math works out fine once you pick the right model.
The benchmark across 14 models on 30 kubernetes ecosystem files settled it.
What the benchmark actually shows
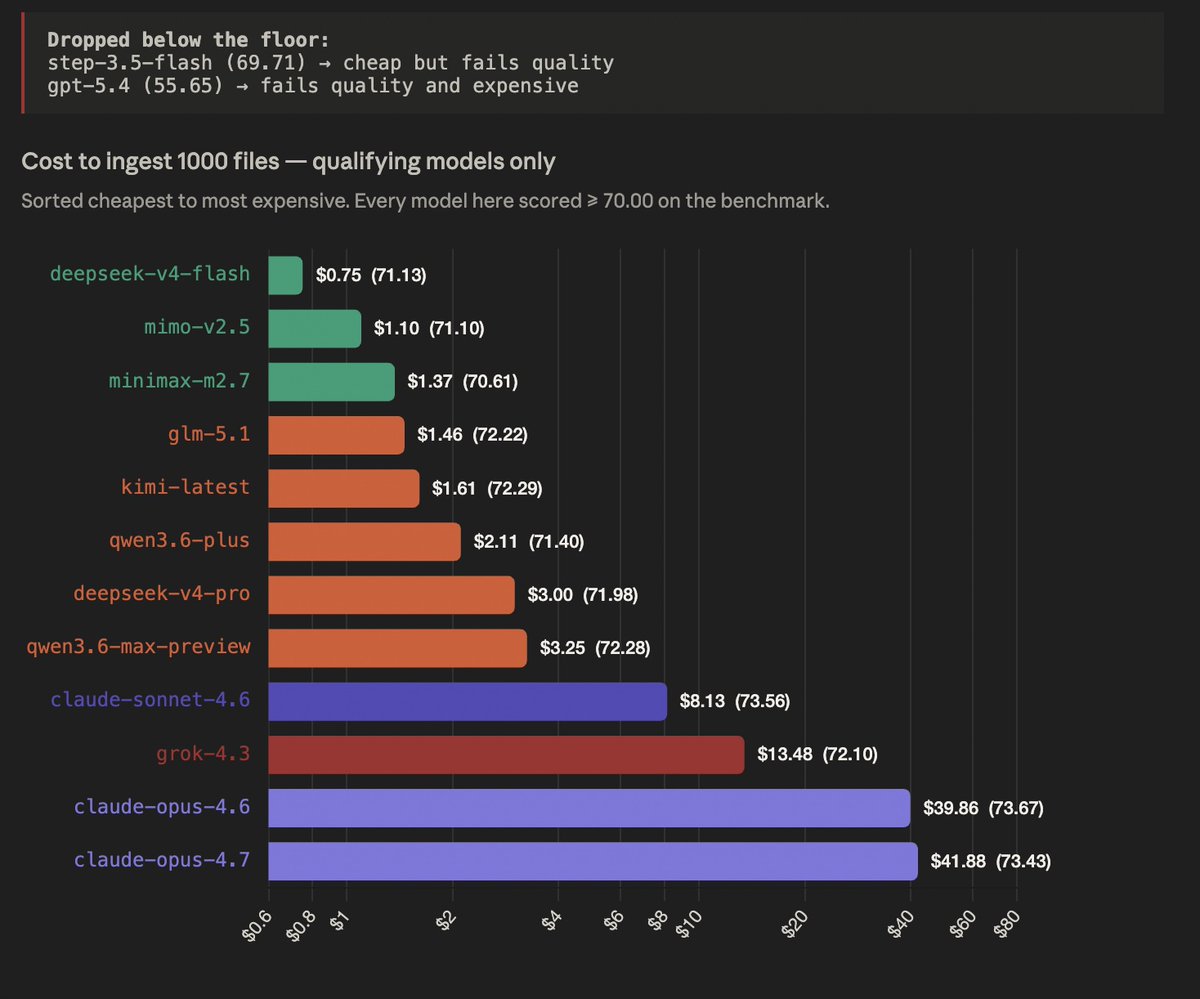
We ran 14 models through 30 files across 7 weighted categories (search, graph, semantic, integration, section map, business context, JSON). After applying a quality floor of 70 weighted accuracy, two models dropped out: Stepfun Step 3.5 Flash at 69.71 and GPT 5.4 at 55.65. The remaining 12 models, sorted by cost to ingest 1000 files, look like this:
Model $/1k files Score
─────────────────────────────────────────────
deepseek-v4-flash $0.75 71.13
mimo-v2.5 $1.10 71.10
minimax-m2.7 $1.37 70.61
glm-5.1 $1.46 72.22
kimi-latest $1.61 72.29
qwen3.6-plus $2.11 71.40
deepseek-v4-pro $3.00 71.98
qwen3.6-max-preview $3.25 72.28
claude-sonnet-4.6 $8.13 73.56
grok-4.3 $13.48 72.10
claude-opus-4.6 $39.86 73.67
claude-opus-4.7 $41.88 73.43
The outcome is striking once you stare at it for a minute. The cheapest qualifying model (DeepSeek V4 Flash at 75 cents per 1000 files) and the most expensive (Claude Opus 4.7 at $41.88) are separated by 56× in cost but only 2.3 points in accuracy. That is the entire story right there.
DeepSeek V4 Flash, MiMo V2.5, MiniMax M2.7, GLM 5.1, and Kimi Latest all sit in the $0.75 to $1.61 range with accuracy between 70.61 and 72.29. Any of them is a sensible default for bulk ingestion. Move up to Sonnet 4.6 and you pay 5× to 10× more for a 1 to 2 point accuracy bump, which is worth it for a premium tier but not for default ingestion. Move up to Opus and you pay 25× to 55× more for accuracy that is statistically indistinguishable from Sonnet, which is hard to justify for any ingestion workload.
Grok 4.3 is the odd one out. It costs $13.48 per 1000 files, sits between Sonnet and Opus on price, but scores 72.10, which is lower than models costing one tenth as much. There is no workload where Grok is the right answer.
The two disqualified models are also worth a note. Stepfun is the cheapest model on the entire board at 56 cents per 1000 files but misses the 70 point quality floor by 0.29 points. For non-production analysis or exploration work, it might still be a fine choice. GPT 5.4 costs $23.39 per 1000 files and scores 55.65, which means it is both expensive and significantly less accurate than every alternative. Worth flagging that this looks like it might be a configuration issue with our eval setup rather than a real model problem, because the gap is large enough to be suspicious.
The bottom line in numbers: DeepSeek V4 Flash for default ingestion at 75 cents per 1000 files, GLM 5.1 for the balanced tier at $1.46, Sonnet 4.6 for premium at $8.13. Opus is not on this list because nothing about its accuracy profile justifies a 25× to 55× cost premium for indexing work.
Im genuinely hyped for this but the ‘ to be continued ‘ for the research paper is putting me off. Or maybe i’ve just been spoiled my @Alibaba_Qwen and @deepseek_ai ‘s amazing releases.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Most AI work is still obsessed with generation.
Can the model write?
Can it code?
Can it design?
Can it make 100 options?
But when generation gets cheap, the bottleneck stops being production. It becomes judgment. I’ve been thinking about whether “taste” can be trained into a model - not as a prompt, not as a vibe, not as a reward score, but as an internalized control policy:
what to keep
what to reject
what to revise
what to defend
what to abandon
The hard part is the test.
If a model only behaves tastefully when surrounded by critics, prompts, constitutions, or audience simulators, then it hasn’t internalized taste. It is just performing taste. The question I want to study is what remains after the scaffold is removed. Can RL move aesthetic judgment into the policy itself?
I don’t know yet. But I think this is where the next layer of AI gets interesting : not models that generate infinite options, but models that know what deserves to survive.