LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. https://t.co/r2uuX0lBCu
"Learn from your own latents, not tokens: A Sample Complexity Theory"
This paper explains why data2vec and JEPA can learn with much less data.
They showed that when data has hidden hierarchy, token prediction becomes harder as the hierarchy gets deeper. But latent prediction keeps the learning problem simple at every level.
Which suggests that models may learn faster when they stop predicting raw tokens and start predicting their own abstractions.
@hewlettplacard@rayan_bkrt t’as aussi l’expansion de l’univers qui joue dans l’étirement des longueurs d’onde de ces astres vers l’infrarouge invisible à nos yeux je pense
@hewlettplacard@rayan_bkrt La nuit l’atmosphère ne diffuse plus la lumière solaire du coup tu as vue transparente sur le cosmos. Ensuite l’univers a un temps de vie fini donc la lumière de certains astres lointains n’arrivent pas jusqu’à nous d’où la couleur noire.
@Shibazakt_@Skyzo05967192 En général l’école n’est pas contre mais elle ne fera pas d’aménagement pour toi donc si t’as des partiels qui coïncident il faudra faire un choix
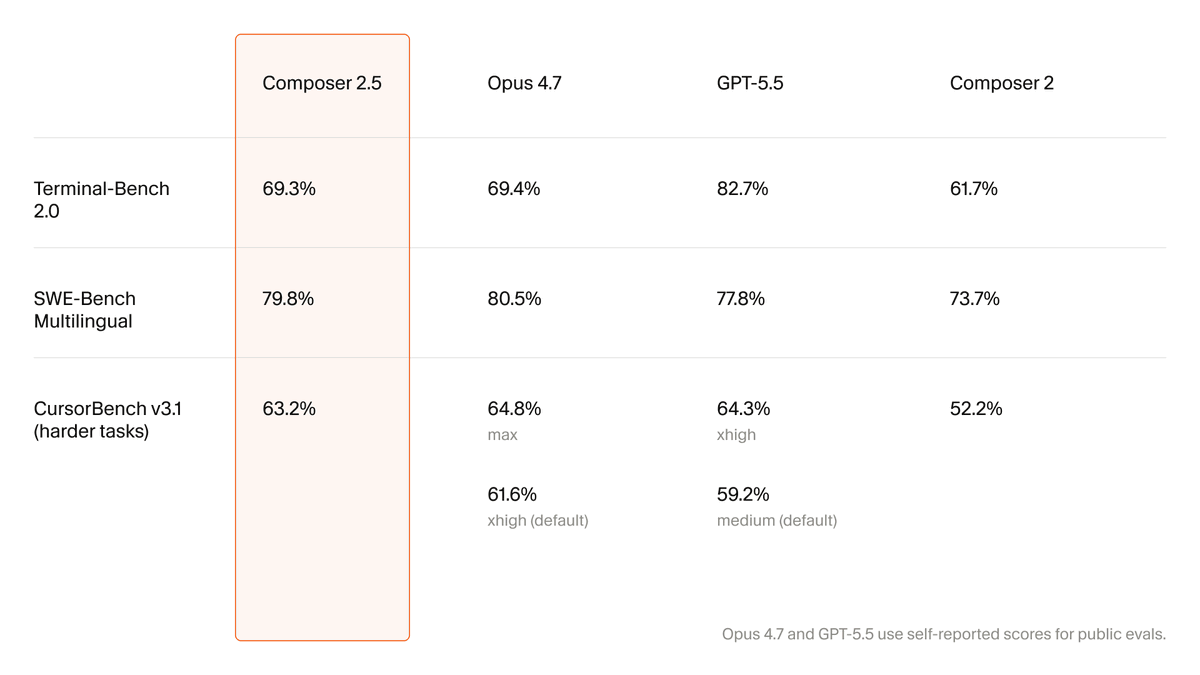
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
Confession: I never had a single work-related sleepless night or ever pulled an all-nighter during my career incl. PhD. Don’t sacrifice your health. Sleep is a superpower — your brain on 8hrs of sleep is a lot smarter than your brain on sleep deprivation.
Don’t listen to people who tell you to chronically sacrifice sleep for work. Sacrificing sleep for your kids/family is a different story.