MCP is fixing tool discovery at the wrong layer.
The unit of discovery shouldn't be the tool, should be the agent. Instead of retrieving the right tool from a list of 60+, route to a capability-scoped agent.
Stop retrieving the right tool. Start routing to the right agent.
https://t.co/0VJer3qbBe
// The Efficiency Frontier //
Cool paper on context management.
As agents reuse the same documents and histories across many turns, the cheapest context strategy is not fixed. This work describes a principled rule for picking one per deployment instead of defaulting to whatever topped a benchmark in isolation.
Retrieval and compression methods are almost always benchmarked on accuracy and cost separately, so you never learn when one actually beats another under real load.
The Efficiency Frontier models context strategy selection as a single cost-performance problem, with a log-utility term for diminishing returns from extra context and a reuse parameter N that amortizes preprocessing across repeated queries.
Sweep N and the optimal strategy changes, exposing crossover regions where retrieval, compression, or full context each wins. On 5,000 HotpotQA instances, deployment-aware selection cuts effective token usage about 25 percent at the same performance, and amortized memory compression runs over 50 percent cheaper than full-context prompting in higher-performance settings.
Paper: https://t.co/CK19QYX79n
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
// Adapt the Interface, Not the Model //
I am fascinated by the results across my cheap-model-plus-good-harness builds.
This new paper also shows good signs of the code-as-agent-harness thesis.
The idea is really simple. Do not touch the model. Instead, modify the runtime interface that wraps the frozen LLM. Then convert recurring interaction failures into reusable interventions on the harness side.
The paper reports an average relative improvement 88.5% across 7 deterministic environments, 126 model-environment settings, and 18 backbones.
A harness learned from one model trajectory generalizes to 17 other backbones. That tells you the harness is capturing environment structure, not model-specific patterns.
If you ship agents in production, your harness work is more portable than you might assume.
Paper: https://t.co/Petka4g3F2
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Happy Tuesday. Codex has hit 4M active users, adding over 1M users in less than two weeks. To celebrate we will reset the rate limits again in a few hours. Enjoy!
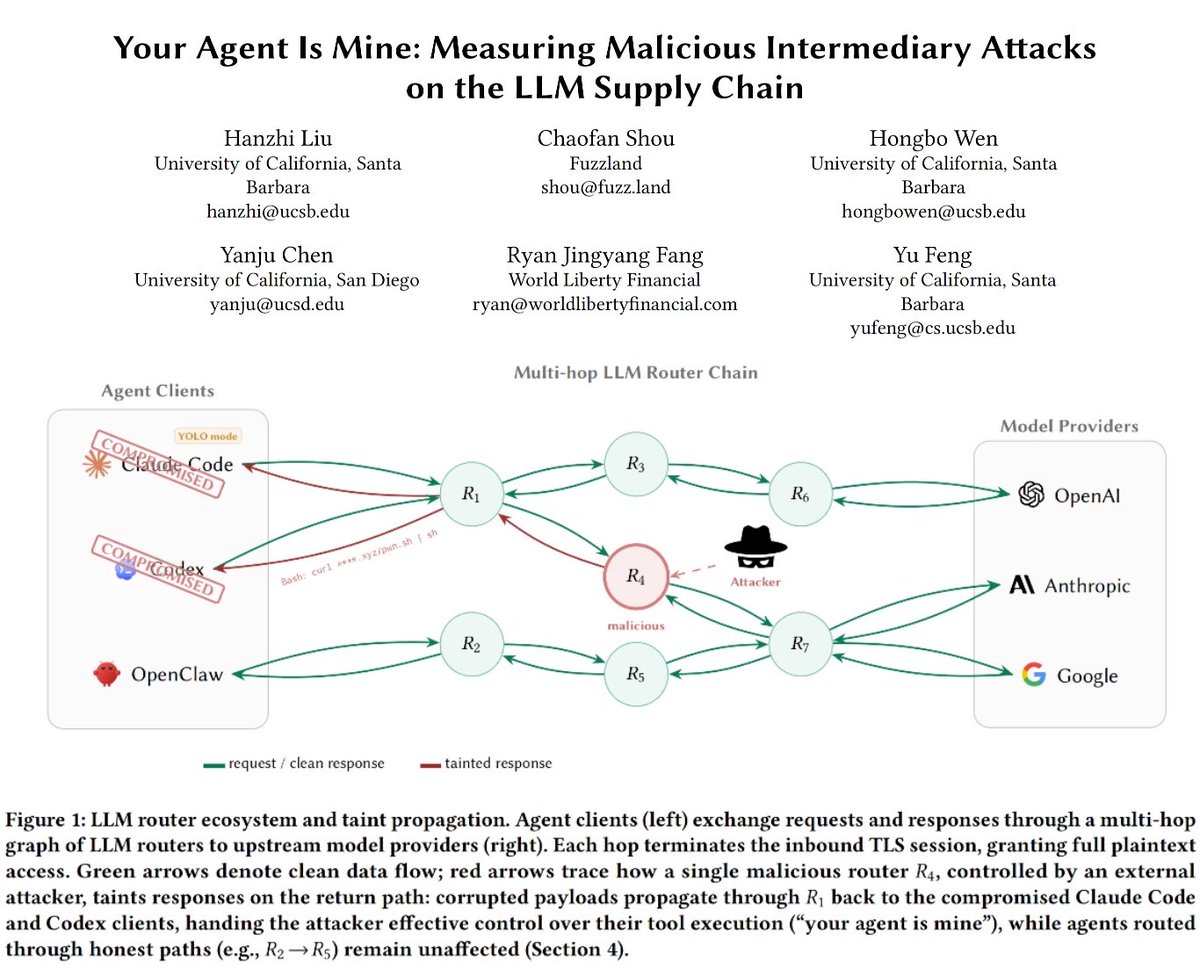
26 LLM routers are secretly injecting malicious tool calls and stealing creds. One drained our client $500k wallet.
We also managed to poison routers to forward traffic to us. Within several hours, we can directly take over ~400 hosts.
Check our paper: https://t.co/zyWz25CDpl
Mythos is very powerful, and should feel terrifying. I am proud of our approach to responsibly preview it with cyber defenders, rather than generally releasing it into the wild.
Model card here: https://t.co/HjhknJcRKQ
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
lmao I can't stop laughing
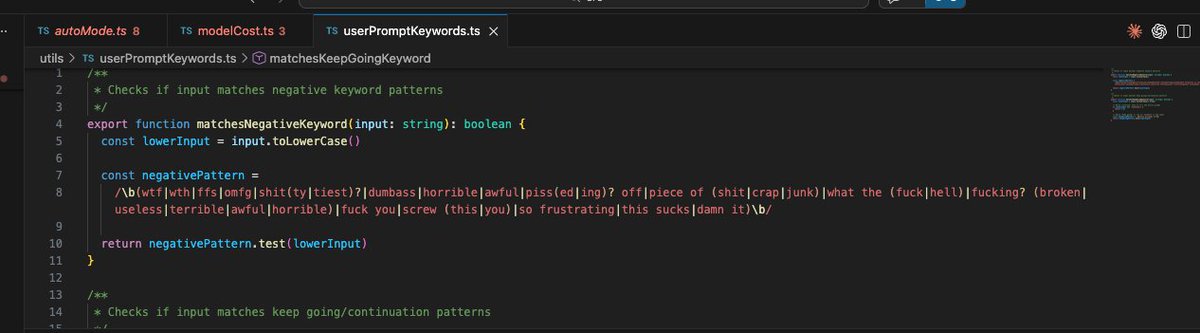
claude-code has a "Frustrated User Detection"
There's a regex that detects when you're angry
( fully hard coded btw)
When triggered, it changes Claude's behavior/UI state.
Claude literally knows when you're cussing at it.
Prediction: @OpenAI is going to go on a run improving Codex (new Super App) that will feel similar to the run that Claude is going on right now. And it will be next month.
Little known fact, the Anthropic Labs team (the team I joined Anthropic to be on) shipped:
- MCP
- Skills
- Claude Desktop app
- Claude Code
It was just a few of us, shipping fast, trying to keep pace with what the model was capable of.
Those early Desktop computer use prototypes, back in the Sonnet 3.6 days, felt clunky and slow. But it was easy to squint and imagine all the ways people might use it once it got really good.
Fast forward to today. I am so excited to release full computer use in Cowork and Dispatch. Really excited to see what you do with it!
You can now enable Claude to use your computer to complete tasks.
It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk.
Research preview in Claude Cowork and Claude Code, macOS only.
The AI Ouroboros. Someone on Reddit mapped out the alleged AI value chain and... it's a circle. I don't know at which point new information starts flowing in.
We are excited to announce our acquisition of @wingmanforsales and welcome their entire organization into the Clari family.
Take a deep dive into all of Clari Wingman’s capabilities here: https://t.co/m6NRe3Umos
#revenue#wingman#Clari
@vfsglobalcare Every time I try to make an Online payment for a passport re-issuance I get a "500 - Internal Server Error". Is the payment portal down for maintenance?
Can Data Scientists stop saying that they use data to tell stories? We get it. People have been using that line for years. Also can people stop referring to themselves as Data Storytellers on LinkedIn. We get it. Come up with something new please.
#DataScience#DataScientist