We have some big news to share today - @RefuelAI is joining @togethercompute to help accelerate the future of open source and enterprise AI! https://t.co/GgPoZ3q5Bx
4/ To our customers: thank you for trusting us to solve your critical data problems and helping shape the journey. And to the Refuel team: you made this possible — every late night, every launch, every hard technical choice. We're proud of what we’ve built. Onwards!
We have some big news to share today - @RefuelAI is joining @togethercompute to help accelerate the future of open source and enterprise AI! https://t.co/GgPoZ3q5Bx
3/ By joining @togethercompute, we will bring Refuel's team, technology and mission to Together’s AI platform, and help accelerate the AI adoption journey of the next generation of developers and enterprises
🚀 Big news: Together AI has acquired @RefuelAI!
Refuel specializes in models and tools that turn messy, unstructured data into clean, structured input—exactly what teams need to build high-quality, production-grade AI applications.
Details below 👇
Data intelligence too cheap to meter
RefuelLLM-2-mini (75.02%), our latest 1.5B param SLM, outperforms all comparable models including Phi-3.5 (65.3%), Qwen2.5 (67.62%), Gemma2 (64.52%), Llama3-3B (55.8%) and Llama3-1B (39.92%) across our benchmark of data processing tasks such as labeling, enrichment and structure extraction
RefuelLLM-2-mini is a Qwen2-1.5B base model, trained on a corpus of 2750+ datasets spanning tasks such as classification, reading comprehension, structured attribute extraction and entity resolution, using the same recipe as other models in the Refuel-LLM family.
It's fast!
We’re open sourcing the model weights, available on @huggingface - https://t.co/ZfYo7erPMv
If you'd like to access models, along with fine tuning support, DM me or reach out to us: https://t.co/pOBlH80PLp
Grateful to our early customers for their partnership, and the entire @RefuelAI team for their hard work 🚀
(6/6) - While not every marketplace looks like Netflix, recommendations drive revenue and high-quality data drives good recommendations.
If you're building a recommendations system and thinking about data quality and the role LLMs can play, we should chat!
In 2017, Netflix got rid of its “5 star” rating system in favor of a simple thumbs up and thumbs down approach.
This decision fundamentally transformed their business. A 🧵- (1/6)
(5/6) - These observations led to Netflix eventually switching to a thumbs up and thumbs down system.
The byproduct? An almost 200% increase in ratings!
We're kicking off the Data+AI Summit with the #MosaicX#Meetup: San Francisco Edition on Monday, June 10th. We're at the #Moscone Center South, 2nd floor, with over 1500 registrants and 39 speakers across four tracks.
It's a "slightly" packed agenda with:
✅ Discussion panels on #Hardware, Build & Risks, Data Panel, and #VC Panel with a special session on #OLMo
✅ #Research track on importance of high quality #data, common challenges in #RAG development, #diffusion models, and more
✅ A use cases track on composable #CDP, building models, #multimodal, #agents, and more
✅ In the building LLMs track, we discuss the challenges, tools/techniques to build them, fast #LLM inference, and building #GenAI apps.
While we are fully packed, if you are already registered for #DataAISummit, we will have a waitlist at the door.
We have speakers from @databricks@DbrxMosaicAI@LaminiAI@Oracle@VoltronData@Replit @AiSquared_ @robusthq @gretel_ai@superannotate@EssenceVenture@AmplifyPartners@llama_index@QuotientAI@ActionIQinc@RefuelAI@OrbyAI @yousearchengine @NumbersStnAI@lancedb@huggingface
https://t.co/TT6l3bUQ3F
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
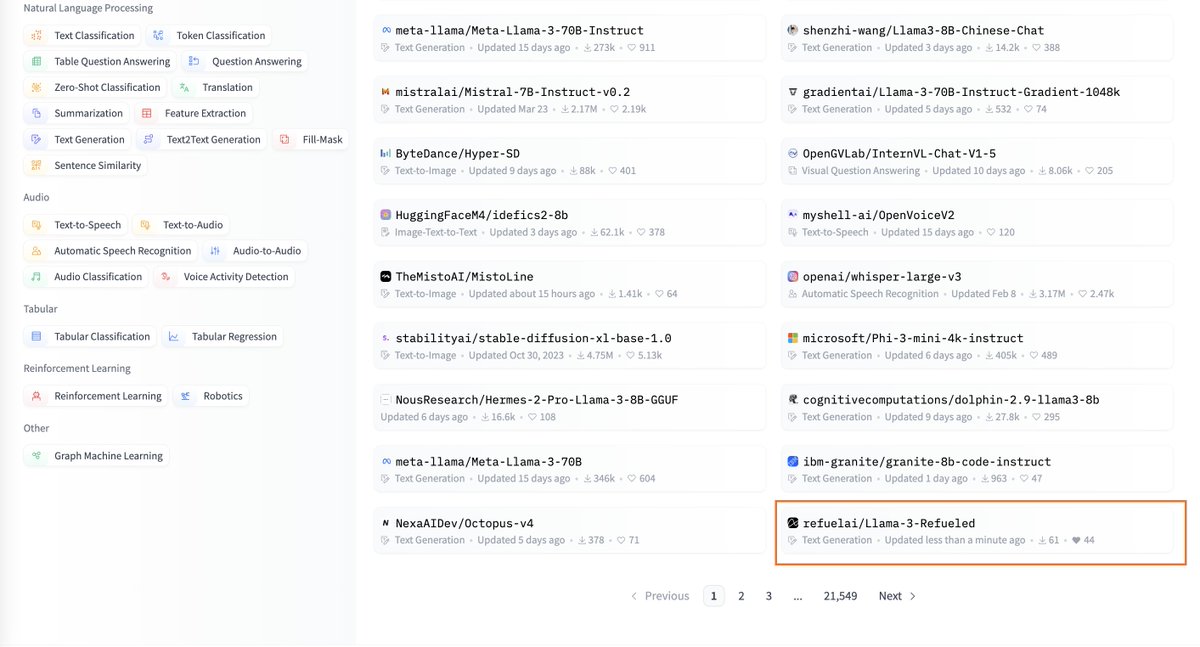
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: https://t.co/to94D0foTx
You can try out the models here and give us some feedback! https://t.co/2LOT6qmY4F. The code and data used for benchmarking the LLMs is available in our Autolabel library: https://t.co/NdpUZ0A7pA
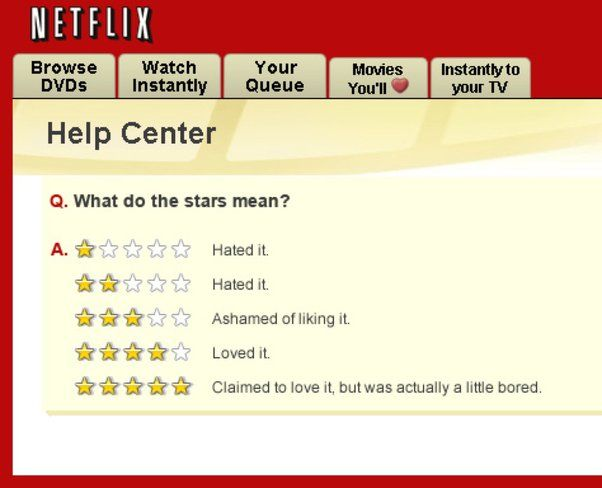
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.
We're thrilled to introduce RefuelLLM-2. Outperforms every single LLM available (GPT-4-Turbo, Claude Opus, Llama 3-70B, Gemini 1.5 Pro) on our benchmark of data labeling tasks.
* Launch: https://t.co/asuMu6lJoX
* Playground: https://t.co/M8X5ygfBdr
Thrilled to introduce RefuelLLM-2, our latest family of LLMs built for data labeling and enrichment tasks. RefuelLLM-2 (83.82%) outperforms GPT-4-Turbo (80.88%), Claude-3-Opus (79.19%), Llama3-70B (78.2%) and Gemini-1.5-Pro (74.59%) on a benchmark of ~30 data labeling tasks:
RefuelLLM-2-small (79.67%), aka Llama-3-Refueled, outperforms all comparable LLMs including Claude3-Sonnet (70.99%), Haiku (69.23%) and GPT-3.5-Turbo (68.13%). We’re open sourcing the model: https://t.co/to94D0foTx
You can try out the models here and give us some feedback! https://t.co/2LOT6qmY4F. The code and data used for benchmarking the LLMs is available in our Autolabel library: https://t.co/NdpUZ0A7pA
One more thing: RefuelLLM-2 family of models output much better calibrated confidence scores - a useful lever to reject, retry or ensemble low confidence outputs.