Solve i̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶ ̶ coding, use it to solve everything else | Research @AnthropicAI | Past: RL @GoogleDeepmind: AlphaProof co-lead, Gemini.
Made a little benchmark called RoastBench - it compares frontier models on their roast jokes. The models roast 10 personalities from comedy central roasts I enjoyed, and I manually rank their jokes. I also mark the ones that made me laugh. LLMs are way worse than top humans.
The models can kind of figure out the beginnings of a setup but their punchlines just fall flat. It's like they don't yet have a good model for what causes a human to laugh.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
This is important and challenging work. If you are excited about contributing please consider applying - particularly by joining the Anthropic Fellows program!
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
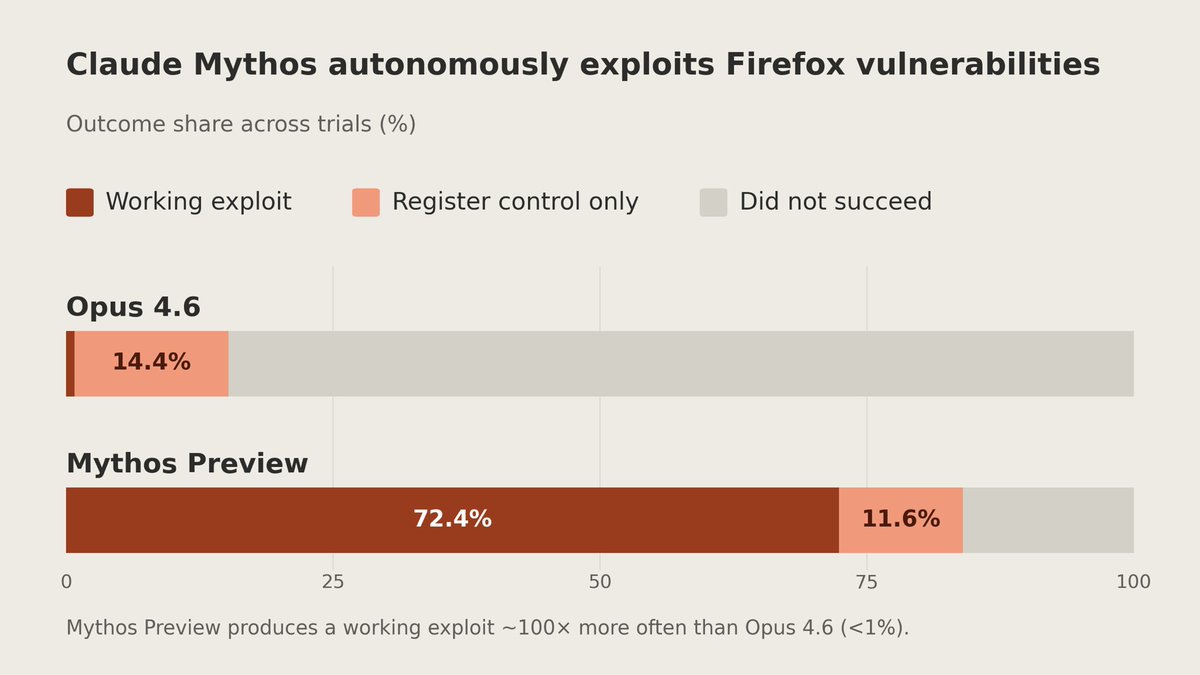
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
@andreasorob@fchollet In the case of the human participants, from the quote in the paper it appears they can reset the action count in the middle of a game, which the AI can't do
@fchollet according to your paper: "Participants were limited to a single attempt per environment and could not revisit previously completed levels. However, they were allowed to reset the current level at any time. In some cases, participants reset levels after reaching a solution in order to improve efficiency, though this typically increased total interaction time."
So humans could play around with the task a bunch, and then just reset the game when they figured it out to get the optimal trajectory? Is AI allowed to do this?
ARC-AGI-3 is out now! We've designed the benchmark to evaluate agentic intelligence via interactive reasoning environments. Beating ARC-AGI-3 will be achieved when an AI system matches or exceeds human-level action efficiency on all environments, upon seeing them for the first time.
We've done extensive human testing that shows 100% of these environments are solvable by humans, upon first contact, with no prior training and no instructions.
Meanwhile, all frontier AI reasoning models do under 1% at this time.
@fchollet according to your paper: "Participants were limited to a single attempt per environment and could not revisit previously completed levels. However, they were allowed to reset the current level at any time. In some cases, participants reset levels after reaching a solution in order to improve efficiency, though this typically increased total interaction time."
So humans could play around with the task a bunch, and then just reset the game when they figured it out to get the optimal trajectory? Is AI allowed to do this?