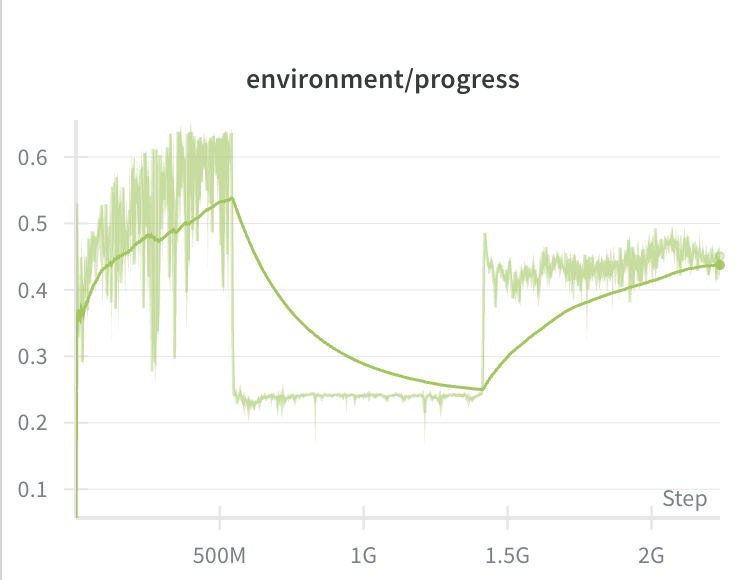
A 766K param model with RL outperforms Opus 4.6 on 8 bit games. I put 4 agents into a Pico Park emulation for 30 minutes. 500 million frames later, they’ve mastered cooperation and can consistently win the game.
Play alongside my agents in the blog below! Trained with @puffer_ai
@Anishfishhh@puffer_ai No not visual I don’t feed the pixel values in. I have access to game data so map all objects in screen which is the input to the cnn
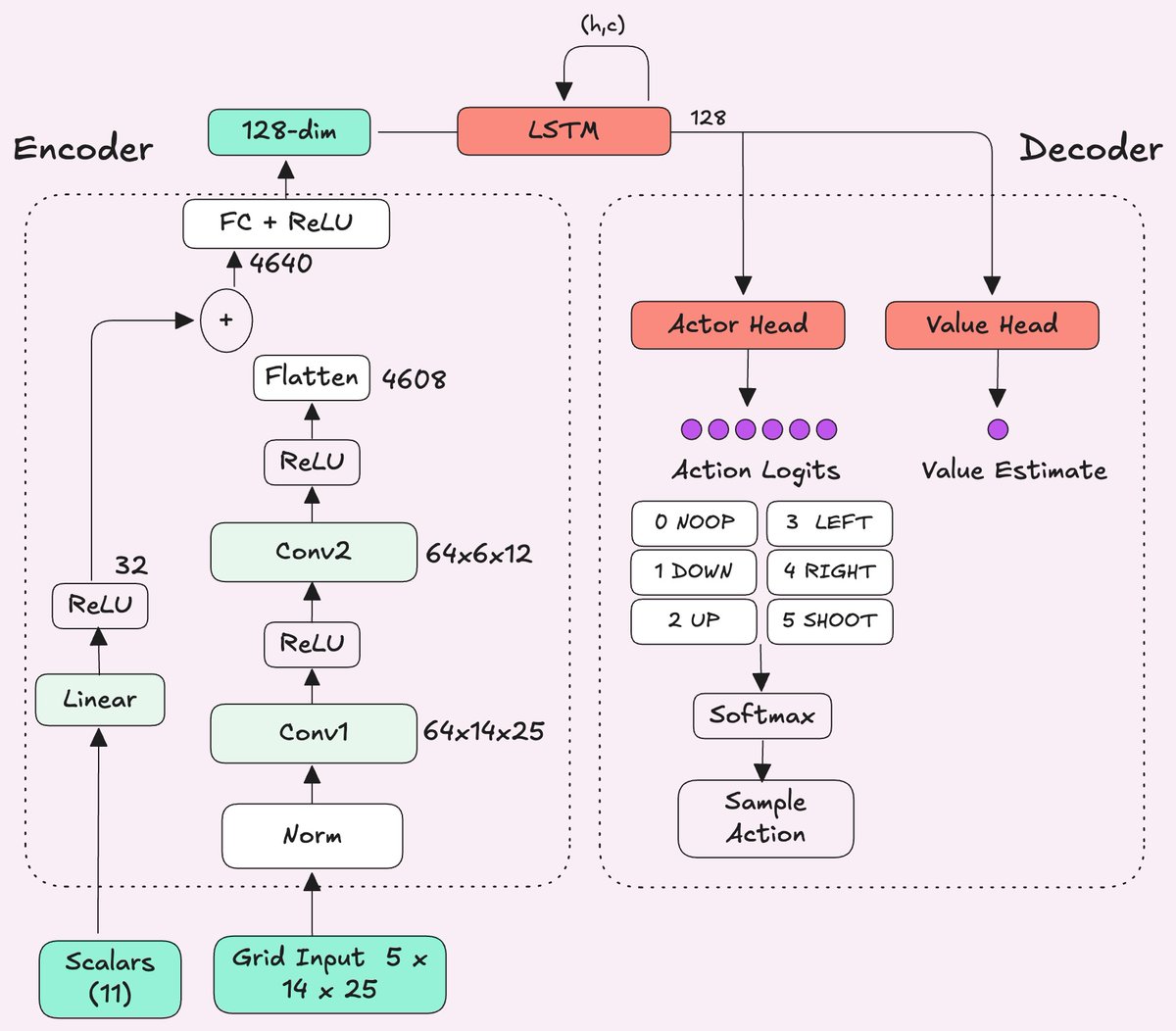
@puffer_ai The model is trained with PPO as the core algorithm using actor-critic architecture. The encoder uses both a CNN for the grid input to keep the spatial information and an MLP for the self data vector.