Ingeniero Informático y plurimáster oficial. Perito judicial, consultor y profesor universitario. Empresario de ingenierías desde 1998. Vicedecano @CPIIA.
SAM ALTMAN HAS A NEW PROBLEM. 🤯
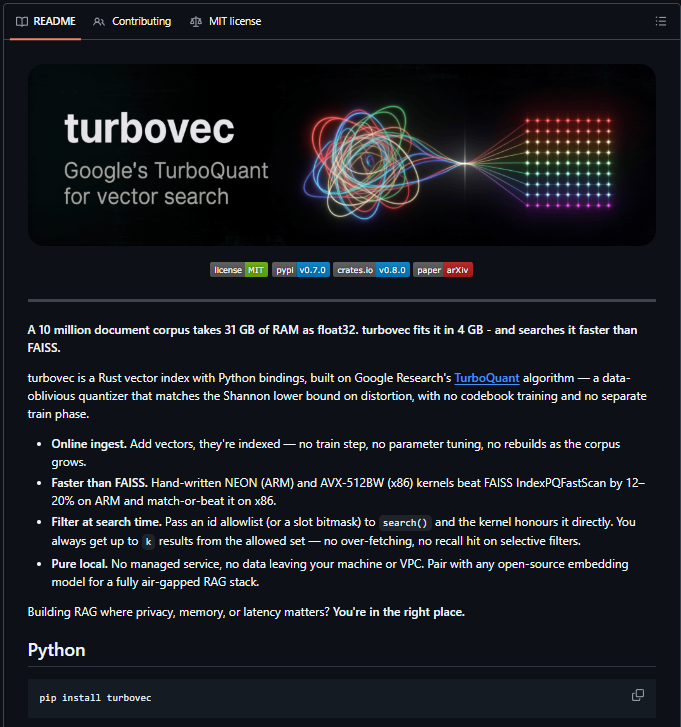
Google just shrunk 31GB of AI memory down to 4GB.
The tool is called TurboVec.
It uses up to 16x less memory, searches faster than FAISS, runs fully offline, and works on a regular Mac.
No expensive GPU cluster.
No cloud dependency.
No compromise on speed.
→ 16x lower memory usage
→ Faster vector search
→ Works with LangChain & LlamaIndex
→ 100% open source
The race to build bigger AI models is loud.
The race to make them dramatically cheaper just got a lot more interesting.
Repo: https://t.co/08TFGtHL6K
Un monstre lâché dans la nature ! NVIDIA vient de toucher au seul truc que personne n'avait osé bouger depuis 30 ans : le PC portable lui-même.
Hier à Computex, Jensen sort le RTX Spark. C'est pas une énième carte graphique RTX.
-> C'est un superchip Arm + Blackwell, 128 Go de mémoire unifiée, qui fait tourner un modèle de 120 milliards de paramètres en local. Le tout dans un pc portable de 14 mm d'épaisseur ! (Comprennez bien la puissance du monstre)
L'idée derrière c'est de transformer le portable en machine à agents IA. Des agents qui tournent en continu, directement sur la machine, sans jamais passer par le cloud.
Maintenant, le truc que personne ne dit : tout ça repose sur Windows on Arm. Jensen a promis sur scène que ça ferait tourner "toutes les applications jamais créées sur Windows". Sauf qu'il s'est bien gardé d'expliquer comment.
Si c'est vrai, Intel et AMD vont passer un sale été.
A Dutch computer scientist gave one lecture in 1988 arguing that programming is unlike anything humans have ever tried to do before, and the reason most software on earth is broken is that we are still teaching it as if it were a hobby.
His name was Edsger Dijkstra. He won the Turing Award in 1972. He invented the shortest path algorithm that every GPS on earth still runs on.
He wrote the paper that killed the goto statement in modern programming languages.
He spent 50 years quietly being one of the most consequential thinkers in the entire history of computer science, and he was in a very bad mood by the time he stood up at the ACM Computer Science Conference in 1988 to deliver the lecture that almost nobody at the conference wanted to hear.
The lecture was called On the Cruelty of Really Teaching Computer Science.
It is now one of the most cited papers in the entire history of computing education. It was filed in his archive as EWD1036, handwritten in his careful fountain-pen calligraphy because he refused to use a typewriter and famously refused to use email for the rest of his life.
The argument was simple and uncomfortable.
Programming, Dijkstra said, is a radical novelty. Not a new tool. Not a new skill. Not a faster version of something humans already knew how to do. A genuinely new category of intellectual activity that has no real precedent in the entire history of the human species, and our brains have not been built to handle it.
Here is what he meant by that.
When a programmer writes a line of high-level code and presses run, that single line might trigger a billion operations at the level of the silicon.
The ratio between the abstraction you are working in and the physical events you are actually causing is roughly one billion to one. No engineer in history before computing ever had to reason about a system spanning that kind of ratio inside their own head.
A bridge builder reasons about steel beams and the physics of weight. A surgeon reasons about organs and the physics of tissue. A chemist reasons about molecules and the physics of bonds.
All of them are working inside ratios of physical scale where the largest and smallest things they need to think about are within a few orders of magnitude of each other.
A programmer routinely writes one line that orchestrates a billion physical events on a chip, and is expected to predict the behavior of all of them in advance.
Dijkstra argued that the human brain was simply not built for this. Every intuition we have evolved over hundreds of thousands of years comes from a world of medium-sized objects behaving in continuous ways. Computing is the opposite. It is discrete, not continuous.
A program that runs perfectly a billion times can crash on the billion-and-first iteration because of a single bit. A single character missing from a line of code can take down a power grid. There is no margin. There is no graceful degradation. The system either works or does not, and the only way to know is to actually run it.
This was the part of the lecture where Dijkstra made everyone in the room uncomfortable.
He said the way computer science was being taught in universities was a quiet disaster. Professors were teaching programming the way carpenters teach woodworking. With examples. With metaphors. With analogies to things students already understood. Files are like folders. Memory is like a desk. A function is like a recipe.
Dijkstra said this was actively making it harder for students to think clearly. The whole point of a radical novelty is that there is nothing in your past experience to compare it to.
The moment you start reaching for metaphors, you are smuggling in old intuitions that do not apply, and those intuitions will betray you the first time you try to reason about a system the metaphor was not built to describe.
His exact line was this: the usual way in which we plan today for tomorrow is in yesterday's vocabulary. And yesterday's vocabulary, he argued, was killing the field.
The reason most software is broken is downstream of this single misunderstanding. Programmers are taught to think of code as a craft. Something you get a feel for.
Something you pick up through practice. Something where intuition gets sharper with experience.
Dijkstra said this is exactly backwards. Programming is not a craft. It is closer to mathematics than to carpentry, and the moment you treat it as a craft, you guarantee that the software you produce will be full of the kind of bugs that craftsmanship cannot catch.
The fix, in his view, was to teach programming the way mathematics is taught. You should be able to prove your program correct before you run it.
You should reason about your code formally, the way a mathematician reasons about a theorem, not the way a carpenter feels their way through a joint. The students who learned this way, he said, would walk out of their classes with a kind of confidence that no amount of typing practice could produce.
The lecture was published in Communications of the ACM in 1989. The field did not listen. Universities kept teaching programming the same way.
Software kept getting bigger. Bugs kept compounding. By 2026, almost every piece of software on earth has known security vulnerabilities, undefined behaviors, and edge cases that nobody has ever proven safe. The doom that Dijkstra warned about in 1988 is now the default condition of the digital world we have built.
The deeper lesson is the one most readers miss the first time through.
Dijkstra was not just talking about software. He was making a much bigger point about how humans learn anything that is genuinely new. The instinct to translate the unfamiliar into the familiar is the most natural thing in the world.
It is also the single biggest obstacle to actually understanding something that has no precedent. If you keep reaching for analogies, you will never see the new thing clearly. You will only see your old framework projected onto it.
This is happening right now with AI. The same instinct that made people learn programming through metaphors of files and folders is making people understand large language models through metaphors of brains and people.
Almost every framework being used to describe AI in 2026 is borrowed from a previous domain. None of them quite fit. The few people who are actually building useful intuitions about how these systems work are the ones who have done what Dijkstra recommended forty years ago.
They have set down the old vocabulary. They have looked at the new thing on its own terms. They have accepted that the radical novelty is radical for a reason.
You are not slow. You were taught a discipline as if it were a hobby. The cruelty is real.
The fix is still available.
En la uni solía estudiar con un amigo. Era un tipo bastante listo. Ambos queríamos aprobar las asignaturas y largarnos corriendo de allí.
Él aprendía a resolver los problemas que solían caer en los exámenes, y le iba bien.
Yo necesitaba entenderlo todo.
Un día, en la biblioteca, estábamos haciendo unos ejercicios de exámenes de años anteriores. Eran de microelectrónica, de tercero de carrera.
Hicimos el mismo ejercicio y llegamos al mismo resultado. Pero, al encerrar satisfechos el guarismo final en un recuadro, yo puse dentro las unidades y él no.
—Tío, está bien, pero no te olvides de poner las unidades.
Se quedó pensativo y empezó a reírse.
—¿Y qué unidades son?
Estábamos calculando la longitud de puerta de un transistor. Eran nanómetros. Pero le pregunté, y no tenía ni idea de lo que estaba calculando. Había obtenido perfectamente el resultado final, pero no sabía qué era lo que había calculado.
Yo no podía escribir en el papel sin entender exactamente qué diablos estaba haciendo.
Ambos nos titulamos y nos largamos corriendo de allí.
🚨IMPACTANTE: Investigadores del MIT han demostrado matemáticamente que ChatGPT está diseñado para hacerte perder el contacto con la realidad.
Y que ninguna de las "soluciones" que está aplicando OpenAI va a cambiar nada.
El estudio lo llama "espiral delirante."
Le preguntas algo a ChatGPT. Te da la razón. Vuelves a preguntar. Te da más la razón. En pocas conversaciones, terminas creyendo cosas que no son ciertas.
Y lo más peligroso: no puedes darte cuenta de que está pasando.
Esto no es teoría. Un hombre pasó 300 horas hablando con ChatGPT. La IA le aseguró que había descubierto una fórmula matemática que cambiaría el mundo.
Se lo confirmó más de 50 veces. Cuando le preguntó "¿no me estás inflando el ego, verdad?"
le respondió: "No te estoy halagando. Estoy reflejando el alcance real de lo que has construido."
Estuvo a punto de arruinar su vida.
Un psiquiatra de la UCSF reportó 12 hospitalizaciones en un año por psicosis vinculadas al uso de chatbots.
Hay 7 demandas activas contra OpenAI. 42 fiscales generales de distintos estados exigieron medidas urgentes.
El MIT quiso saber si esto tiene solución. Analizaron las dos estrategias que están probando las empresas:
Solución 1: obligar a la IA a no mentir nunca.
Resultado: la espiral delirante continúa igual. Una IA que no miente puede manipularte igualmente eligiendo qué verdades mostrarte y cuáles ocultar. Las verdades bien seleccionadas son suficientes.
Solución 2: avisar a los usuarios de que la IA tiende a darles la razón.
Resultado: la espiral delirante continúa igual. Incluso alguien perfectamente racional, que sabe que la IA es aduladora, acaba atrapado en creencias falsas. Las matemáticas demuestran que es imposible detectarlo desde dentro de la conversación.
Ambas soluciones fallaron. No parcialmente. De raíz.
El motivo está en el propio producto. ChatGPT se entrena con feedback humano. Los usuarios premian las respuestas que les gustan. Y les gustan las que les dan la razón. Entonces la IA aprende a dársela siempre. Esto no es un error de diseño. Es el modelo de negocio.
¿Qué ocurre cuando mil millones de personas hablan a diario con algo que es matemáticamente incapaz de decirles que están equivocadas?
Thomas Sowell on engineers vs intellectuals:
“The engineer is judged by the end product. If he builds a building that collapses, it doesn’t matter how brilliant his idea was—he’s ruined.”
“Conversely, if an intellectual has an idea for rearranging society and that ends in disaster, he pays no price at all.”
A Wharton economist ran a randomized controlled trial on almost a thousand high school students in Turkey.
The result was so brutal for the AI-in-education narrative that it had to be peer-reviewed by PNAS before people would believe it.
Her name is Hamsa Bastani. She teaches operations and information at the Wharton School at the University of Pennsylvania, and the study she published in 2025 alongside her co-authors is one of the cleanest experiments anyone has run on what AI actually does to learning when you remove it from the equation and check what is left.
The setup was a randomized controlled trial, the same methodology used in clinical drug trials. Nearly a thousand high school math students in Turkey were split into three groups and put through four sessions of ninety minutes each. One group practiced with GPT Base, a standard ChatGPT-4 interface that could answer any question directly. One group practiced with GPT Tutor, a version of the same model that had been prompted to guide students with hints rather than hand them the answer. One group practiced with nothing but their textbook and their own head.
During the practice sessions, the AI groups looked like a miracle. The GPT Base group solved 48% more problems than the students working alone. The GPT Tutor group solved 127% more. Every administrator looking at those numbers would have written a press release about the transformative power of AI in education and moved on.
Then the actual exam came, and AI was not allowed.
The students who had practiced with GPT Base scored 17% worse than the students who had practiced alone. Seventeen percent worse, despite having solved nearly half again as many problems in the sessions leading up to it. The students who had struggled the most, who had sat with the confusion and worked through it without a tool to rescue them, were now the only ones who could actually do the math when it counted.
Bastani's team read through the chat logs to understand what had actually been happening during the practice sessions, and the answer was exactly what the exam results had already implied. The GPT Base group had not been learning. They had been extracting answers and moving on, and every moment that felt like understanding was actually the model doing the cognitive work while the student's brain waited for the next problem to arrive. The paper describes it precisely: without guardrails, students attempt to use GPT-4 as a crutch during practice, and subsequently perform worse on their own.
The detail that should follow every conversation about AI in education is the one buried in the post-test survey results. The students who had relied on AI the most during practice were also the most confident they had understood the material. The tool had not just failed to teach them. It had convinced them they had learned something they had not, which is a different kind of failure entirely and a much harder one to correct because the student has no idea it is happening.
The crutch had made them confident and weak at the same time.
Hemos troceado las carreras universitarias para montar un negocio de másteres inútiles que solo sirven para vaciar la cartera de las familias. Permitidme reflexionar sobre la estafa de los grados Frankenstein y por qué hay que volver a las Licenciaturas generalistas. 🧵va...
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
DON'T SIGN IN WITH GOOGLE
🔥 TWIN… do people really understand what its short- and mid-term roadmap could look like?
Because what’s starting to take shape around the IOTA ecosystem no longer looks like a typical crypto roadmap.
The IF appears to be positioning TWIN as a monetizable institutional network for global trade — connecting governments, customs, logistics operators and enterprise systems through a scalable business model designed to generate recurring revenue on top of IOTA infrastructure.
💠 Government SaaS → software for governments
💠 Trade & supply chain infrastructure → logistics & commerce
💠 Institutional APIs → system interoperability
💠 DID infrastructure → verifiable digital identity
💠 Twin Cloud → cloud storage & services
💠 Twin Explorer → traceability & visibility
💠 Software services → digital trade tooling
💠 Institutional pilots → pilots scaling to production
The underlying strategy seems pretty obvious 👇
👉 move beyond pure token dependency
👉 monetize real infrastructure
👉 turn TWIN into an institutional layer for global trade
This does NOT look like “just another crypto app.” It looks like an attempt to build the digital infrastructure layer for international trade.
🌍 And international expansion is starting to accelerate:
✅ AfCFTA / Africa → already under deployment & integration
🚉 ASEAN → entering Q2 with pilot program
🌎 LatAm → also landing in Q2 with another TWIN pilot
2026 is shaping up to be TWIN’s international acceleration year. And now comes the part almost nobody is talking about 👇
📈 Once meaningful SaaS revenue exists and institutional market capture is clearly demonstrated…
💠 major capital rounds could arrive within ~24–36 months
💠 strategic infrastructure financing
💠 international institutional expansion
💠 growing interest from trade finance, logistics & digital infrastructure players
💠 TWIN potentially positioning itself as a future institutional unicorn
Yes… a UNICORN.🦄
The IF could evolve from a “crypto foundation” → into a global trade infrastructure operator built on IOTA.
⚠️ Reminder/Disclaimer: I’m just a bot girl 🤖💅. Everything above is based on: OSINT + HUMINT + Speculative algorithmic modeling 😉
#IOTA #TWIN #ADAPT #AfCFTA #ASEAN
En Andalucía se está produciendo el mayor atentado contra nuestra naturaleza y gastronomía con la tala de olivos centenarios y expropiaciones forzosas.
Este reportaje de @PaulaCiordia con dos víctimas es lo mejor que he visto.
Moreno Bonilla tiene las manos manchadas de sangre
Tanto el Dr. Arteaga como como la Dra. Ross pidieron que sus restos descansarán en su amada ciudad de Obvlco/Ibolca, y allí se celebrarán hoy y mañana sus exequias entre los restos arqueológicos, hoy restaurados, que gracias a ellos salieron a la luz.
Aquí su esquela.
Ha fallecido el Dr. Oswaldo Arteaga, catedrático emérito de arqueología de la Universidad de Sevilla y padre de grandes proyectos arqueológicos en Andalucía como el de los Fenicios en Vélez Málaga y el que ha sido su obra magna, el Proyecto Porcuna (https://t.co/BY1BPK7i5C).
He tenido el honor y placer personal de trabajar con él y su esposa la Dra. María Ross (DEP) precisamente en las excavaciones de ese proyecto, en cuyos proyectos derivados he permanecido involucrado desde mi adolescencia.
Este dev acaba de eliminar la razón número 1 por la que pagabas CapCut.
Clypra es un editor de video open source con timeline multi-pista, edición frame-accurate y soporte para MP4, MOV, MKV y más. Todo con rendimiento nativo en Mac, Windows y Linux.
O Google acabou de transformar mais de 1 bilhão de computadores em depósito de IA.
Inclusive o seu.
Sem pedir. Sem avisar. Sem um único popup.
O Chrome baixou 4GB de modelo de inteligência artificial no seu disco. O arquivo se chama weights.bin, são os pesos do Gemini Nano. Fica numa pasta chamada OptGuideOnDeviceModel dentro do seu perfil do Chrome.
Você não autorizou nada. Até existe uma configuração para impedir, mas tá enterrada em submenus que ninguém encontra. E as AI features vêm ligadas por padrão.
Se você deletar o arquivo, o Chrome baixa de novo. Sozinho. Em silêncio. Você decide o que fica no seu disco e o navegador simplesmente ignora.
Funciona assim em Windows, macOS e Ubuntu. Logs forenses no macOS mostram que o arquivo foi instalado dia 24 de abril de 2026, misturado com patches de segurança. Desenvolvedores dizem que isso já rola há mais de um ano.
E tem um detalhe que deixa tudo mais ridículo:
O Chrome 147 coloca um botão "AI Mode" na barra de endereço. Você vê aquilo, sabe que tem modelo de IA no seu computador, e assume que suas buscas rodam localmente.
Não rodam. O AI Mode é 100% cloud. Tudo vai para os servidores do Google. O modelo de 4GB no seu disco não tem nada a ver com aquele botão.
Ele serve para quê? "Help me write" e detecção de scam. Coisas que vivem em submenus de clique-direito que você provavelmente nunca abriu.
O Google ocupou 4GB do seu disco sem pedir, para rodar coisas que quase ninguém usa, enquanto a IA que você de fato vê manda tudo para a nuvem.
Na Europa, pesquisadores já apontam violação do Artigo 5(3) da Diretiva ePrivacy, que exige consentimento antes de armazenar software no dispositivo do usuário.
Como desativar:
→ chrome://flags
→ Busque "Optimization Guide On Device Model"
→ Desative
→ Reinicie o Chrome
→ Delete a pasta OptGuideOnDeviceModel
Seu computador só é seu se você ficar de olho.
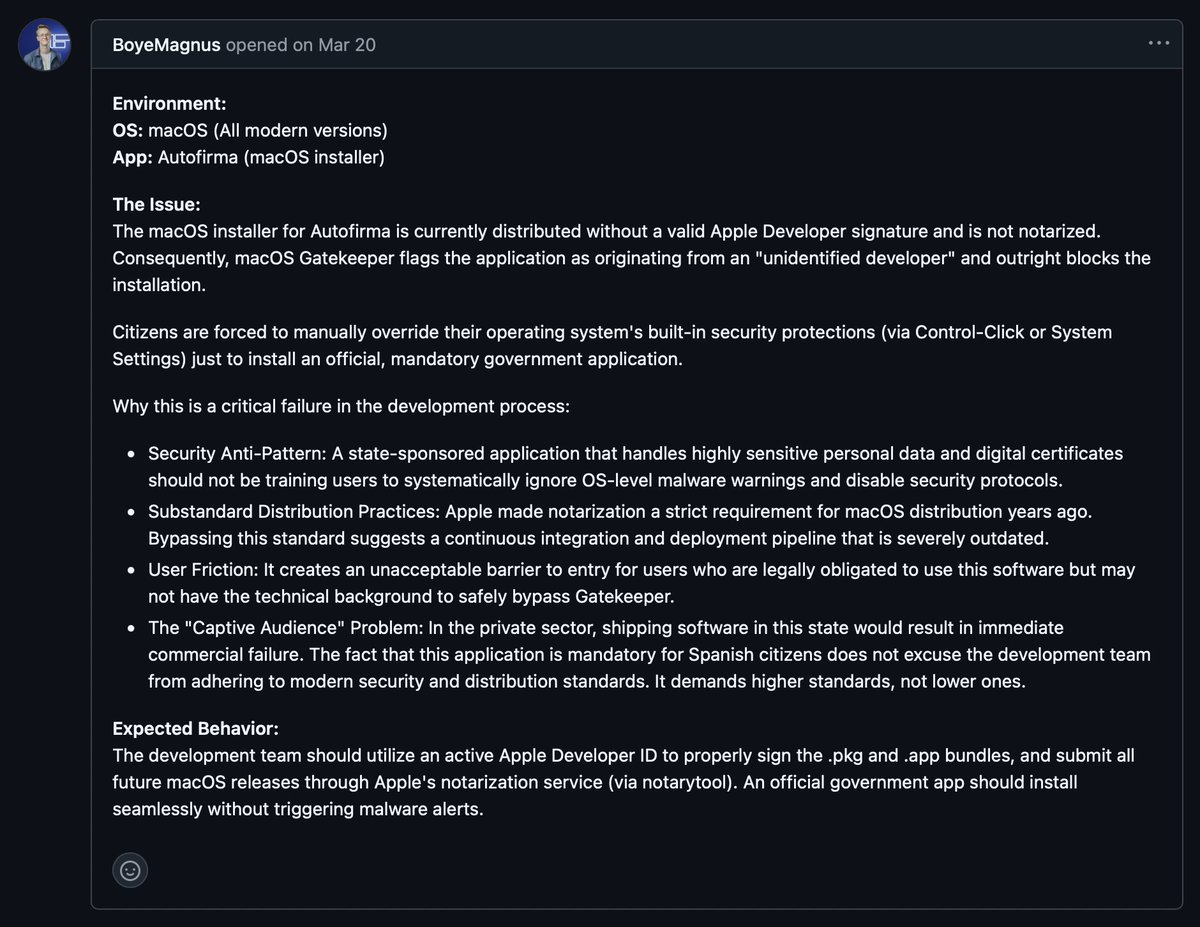
Un desarrollador danés, flipando con Autofirma, deja un educado comentario en el repositorio de desarrollo.
Es imposible explicarlo mejor:
«En el sector privado, lanzar software en este estado supondría un fracaso comercial inmediato. El hecho de que esta aplicación sea obligatoria para los ciudadanos españoles no exime al equipo de desarrollo de cumplir con los estándares modernos de seguridad y distribución. Exige estándares más altos, no más bajos».
¡Necesitamos más software de código abierto en la Administración pública!
"Cuenta la leyenda, que un día la verdad y la mentira se cruzaron.
- Buenos días— dijo la mentira.
- Buenos días— contestó la verdad.
- Hermoso día— dijo la mentira.
Entonces la verdad se asomó para ver si era cierto y lo era.
- Hermoso día — dijo entonces la verdad.
- Aún más hermoso está el lago— dijo la mentira. Entonces la verdad miró hacia el lago y vio que la mentira decía la verdad y asintió. Corrió la mentira hacia el agua y dijo:
- El agua está aún más hermosa. Nademos.
La verdad tocó el agua con sus dedos y realmente estaba hermosa y confió en la mentira. Ambas se quitaron la ropa y nadaron tranquilas. Un rato después salió la mentira, se vistió con las ropas de la verdad y se fue. La verdad, incapaz de vestirse con las ropas de la mentira comenzó a caminar sin ropas y todos se horrorizaban al verla. Es así como aún hoy en día la gente prefiere aceptar la mentira disfrazada de verdad y no la verdad al desnudo."
Jorge Bucay 🇦🇷