🌟 Announcing the 2nd Workshop on Efficient Reasoning (ER) at @colm2026 — Oct 9!
📣 We welcome submissions! Submit your work here: https://t.co/loVmlunK87
🗓️ Deadline: July 12, 2026 (AoE)
🔗 Website: https://t.co/FRgQ95CcAd
💬 Topics include (but aren't limited to):
🔹 Multimodal, spatial & embodied reasoning under efficiency constraints
🔹 Curating high-quality reasoning datasets under resource constraints
🔹 Algorithmic innovations for efficient training & RL fine-tuning
🔹 Fast inference: pruning, compression, progressive generation, KV-cache tricks
🔹 Benchmarks & theory on time-/space-complexity and faithfulness
🔹 Systems to deploy long-CoT or on-device reasoning in the wild
🔹 Safety & robustness of efficient reasoning pipelines
🔹 Real-time applications in healthcare, robotics, autonomy, and more
🤝 We invite perspectives from ML, systems, natural & social sciences, and industry practitioners to rethink reasoning under tight compute, memory, latency, and cost budgets.
Hope to see you there! 🚀
Cortices is mission control for AI agents, with support for Claude Code and Codex. Bring agents across laptops, servers, and workstations into one place.
Chat with agents, review diffs, and schedule work from any browser or phone.
Free, no waitlist: https://t.co/VGBRpWmbsq
🚨 New paper alert !!
🎥 Video VLMs are strong at high-level semantics and long-range temporal understanding.
🧠 JEPA is almost the opposite: better at dense, high-frequency dynamics, local physical consistency, and fast corrective control, but are less suited for rich semantic reasoning and long-horizon reasoning.
We try to get the best of both:
🧩 A VLM as a cortex-like reasoner for semantics and long-horizon planning
⚡ A JEPA branch as a cerebellum-like controller for fine-grained dynamics, physical consistency, and rapid corrections
Proudly, we present ThinkJEPA: a VLM-guided latent world model that FiLM-fuse the pyramid repr of VLMs encoding long-horizon semantic reasoning into the JEPA repr for fine-grained, physically consistent dynamics prediction.
🔗 Project: https://t.co/quro6Pf8un
📄 Paper: https://t.co/yO5rv3ZJT7
We introduce TIDES, the first work showing that test-time scaling can be adversarially exploited. By injecting small latent perturbations (DLT), we induce inference drift that amplifies with reasoning depth, causing longer reasoning traces to degrade performance.
#safety
🧠 Make models reason safely, not just respond safely
We introduce CRAFT (Contrastive Reasoning Alignment) to address a key gap: current safety methods mostly constrain outputs, while reasoning trajectories remain unaligned.
#VideoReason We are open-sourcing the entire VBVR stack to speed-up the arrival of video reasoning as the next fundamental paradigm of intelligence
- 150+ synthetic generators
- 1 million training clips
- Cloud-scale data factory
- Unified EvalKit
- 100 rule-based evaluators
- Strong baseline model
Checkout at https://t.co/lOtJzJYC52
New paper alert 🔔‼️🚨✨
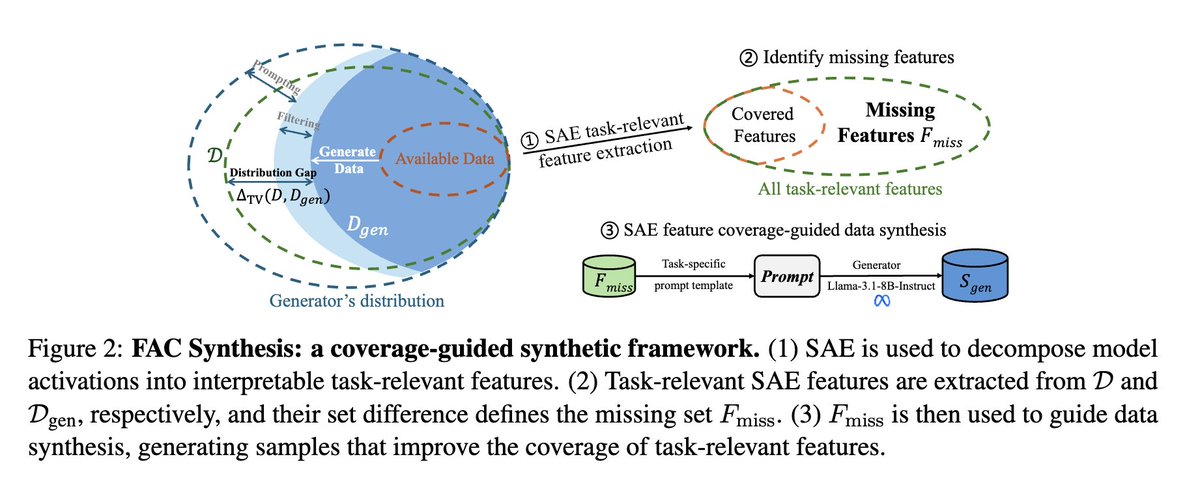
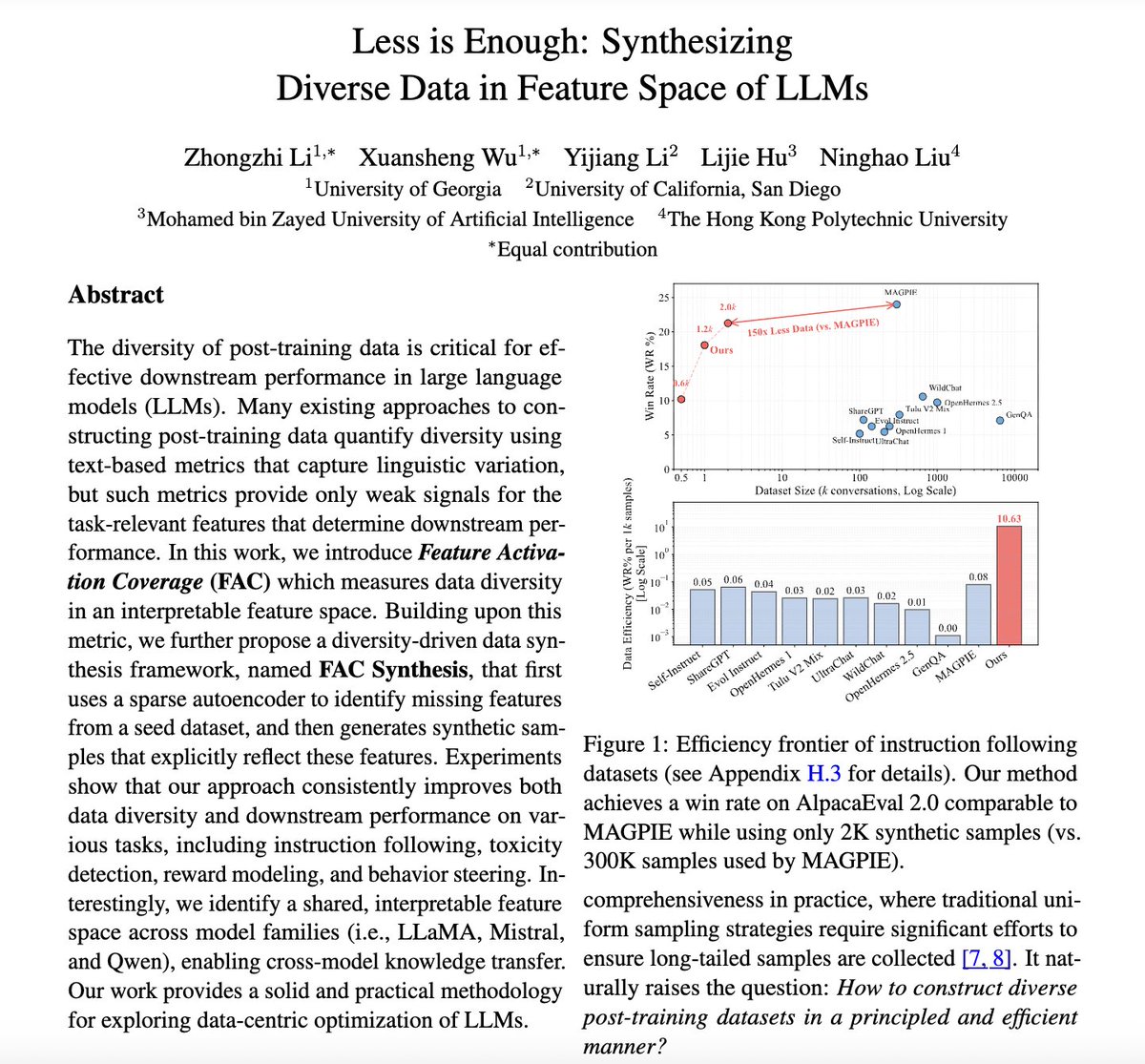
Super excited to share our latest work: Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs (arXiv:2602.10388) 🎉📄🧠
If you’re doing SFT / alignment / RM and “more data” feels like roulette… this is for you 🎰😵💫🫠
The annoying reality we show in this work is:
📚⬆️ bigger dataset ≠ 📈⬆️ better model ❌
Instead, it depends on whether your training data covers the abilities the model is currently missing 🧩🕳️✅
So the question isn’t “how much data?” 🤷♂️📦
It’s: what capability gaps exist, and does my data fill them? 🕳️➡️🧱🔦⚙️✨
Thrilled to be selected as a DAAD AINeT Fellow for Postdoc-NeT-AI 11/2025 on Explainable AI, supported by the German Federal Ministry of Research. Excited to contribute to trustworthy and transparent AI research!
Thanks to my advisors Yan Chen & Han Liu #AI#NU@northwesterncs
🚀 RHYTHM (NeurIPS’25): Hierarchical temporal tokenization + frozen LLMs for human mobility. Captures multi-scale periodicity & long-range deps. 📊 +2.4% acc, +5.0% weekends, −24.6% training time vs SOTA.
🔗 https://t.co/Z1re9TpIY2 #NeurIPS2025#AI#Mobility
@cwolferesearch Attention Sink and our work are contemporaneous, with one applying Softmax1 in the deployment stage and the other in the training stage. So, strictly speaking, they are the two main extensions of Softmax1.
@cwolferesearch I am the author of OutEffHop, a researcher who allocated in Northwestern university. I believe the gpt-odd also use our technology in their training . The paper link is below; https://t.co/yV9UqSY8Ki.
Attention Sink and our work are contemporaneous, with one applying Softmax1 in the deployment stage and the other in the training stage. So, strictly speaking, they are the two main extensions of Softmax1.
We are pleased to see GPT-oss adopting the one-off technique from Attention and our related work, Attention Sink. This is a good opportunity to highlight our two ICML papers on OutEffHop, which focus on optimizing the training process to enhance both LoRA and quantization.
The gpt-oss models from OpenAI are a synthesis of ideas from prior research. Here are 10 interesting papers that were directly used in gpt-oss…
(1) Longformer: Introduces sliding window attention, a form of sparse attention that is utilized in alternating layers of both gpt-oss models.
(2) StreamingLLM: Describes the concept of attention sinks in large language models (LLMs)—these are tokens within a sequence that the model assigns high attention or weight to, simply because the softmax operation prevents the model from assigning attention to no tokens at all.
(3) Off-by-one attention: Proposes a solution to attention sinks by allowing the attention mechanism to assign no attention to any token. This is achieved by adding a bias term of 1 to the denominator of the softmax operation within attention. In gpt-oss models, a similar approach is used, but the bias term is learned rather than fixed at 1.
(4) Switch Transformer: Presents several ideas foundational to modern mixture-of-experts (MoE) based LLMs. It’s important to note that many other papers, in addition to Switch Transformer, have contributed to this field.
(5) RMSNorm: A streamlined variant of layer normalization that is both more efficient and has fewer trainable parameters. Both gpt-oss models employ RMSNorm.
(6) RoPE: Stands for Rotary Positional Encoding, a hybrid absolute/relative positional encoding method used by gpt-oss models. RoPE encodes absolute position using a rotation matrix and incorporates relative position information directly into the self-attention mechanism.
(7) YaRN: A method for extending the context window in LLMs, which is adopted by gpt-oss models. YaRN works by adjusting the frequency basis used within RoPE and further training the LLM to handle longer contexts.
(8) Flash Attention: Utilized by gpt-oss models, flash attention leverages system-level optimizations to significantly improve the computational and memory efficiency of the attention operation.
(9) DeepSeek-R1: While the specific reasoning or reinforcement learning (RL) training strategies used by gpt-oss models are not fully detailed, the DeepSeek-R1 technical report offers a comprehensive overview of how RL training with verifiable rewards is implemented at scale.
(10) Deliberative alignment: This is the safety training approach used by gpt-oss models, designed to teach the models how to reason through safety specifications and determine when it is appropriate to refuse a request.
1. Outlier-efficient hopfield layers for large transformer-based models,ICML2024
2. Fast and Low-Cost Genomic Foundation Models via Outlier Removal, ICML2025