This was a super fun project we did with @nthngdy, trying to keep the best of both worlds between tokenization-free models and subword tokenizers.
Check it out!
💥 What if you could train and fine-tune the tokenizer with your LM?
We introduce a new neural tokenizer named MANTa.
Amazingly, it learns to segment words w/o explicit supervision!
📜 Preprint: https://t.co/LoxYce2Vlv
Accepted at #EMNLP Findings
Thread below ⬇️ (1/8)
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
Introducing: Cohere Command A+
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
⬇️R1-Distill-Llama-8B with 128 KV pairs ⬇️
🧵
Introducing Command R7B: the smallest, fastest, and final model in our R series of enterprise-focused LLMs!
It delivers a powerful combination of state-of-the-art performance in its class and efficiency to lower the cost of building AI applications.
https://t.co/e2ah5c5x5J
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier 🌿
Today, we release a technical report with extended evaluation for Aya Expanse, our new generation of 8B and 32B parameters multilingual language models 🌎
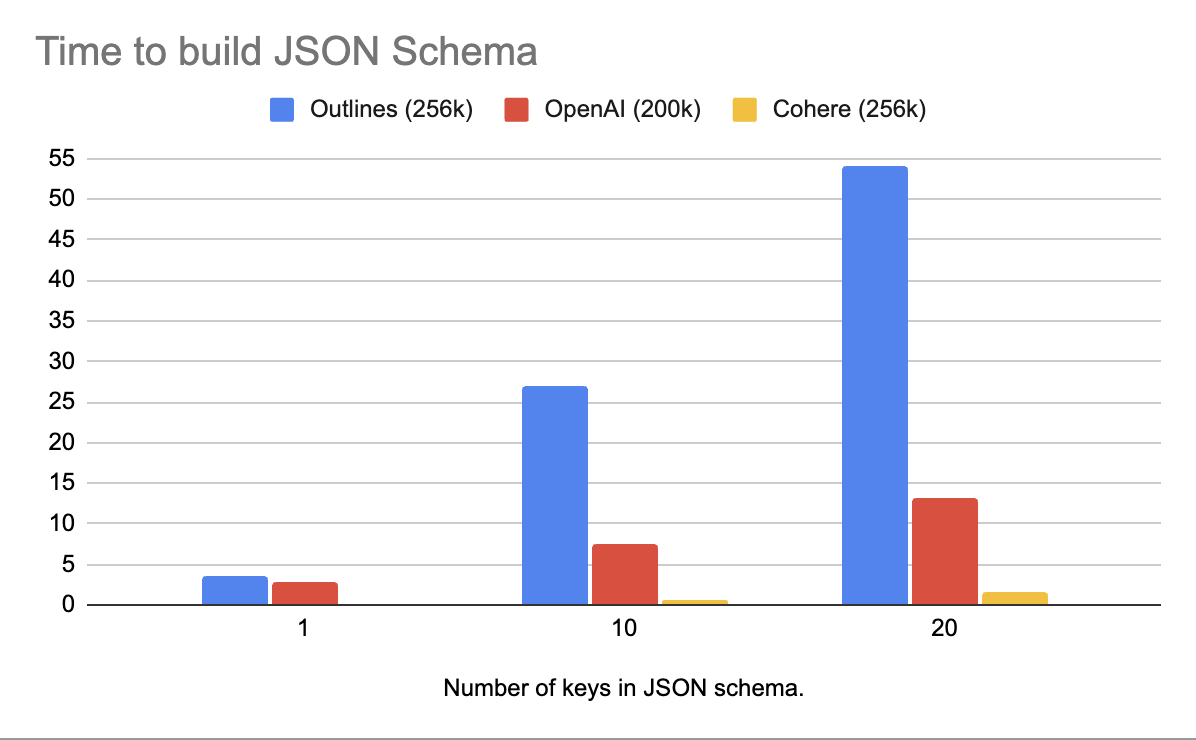
Building artefacts for JSON Schema is expensive to do on scale in production for LLM inference. Probably why OpenAI had "JSON mode" for a year but not "JSON schema mode" until @cohere released it first :)
* @cohere is >10x faster than OpenAI
* @cohere is >45x faster than Outlines
We’re excited to announce our Series D financing to accelerate growth, expand our team, & develop our next class of frontier, enterprise-grade, data privacy-focused AI technology.
We’re bringing highly scalable and secure AI solutions to global enterprises wherever their data is and in whatever language they speak.
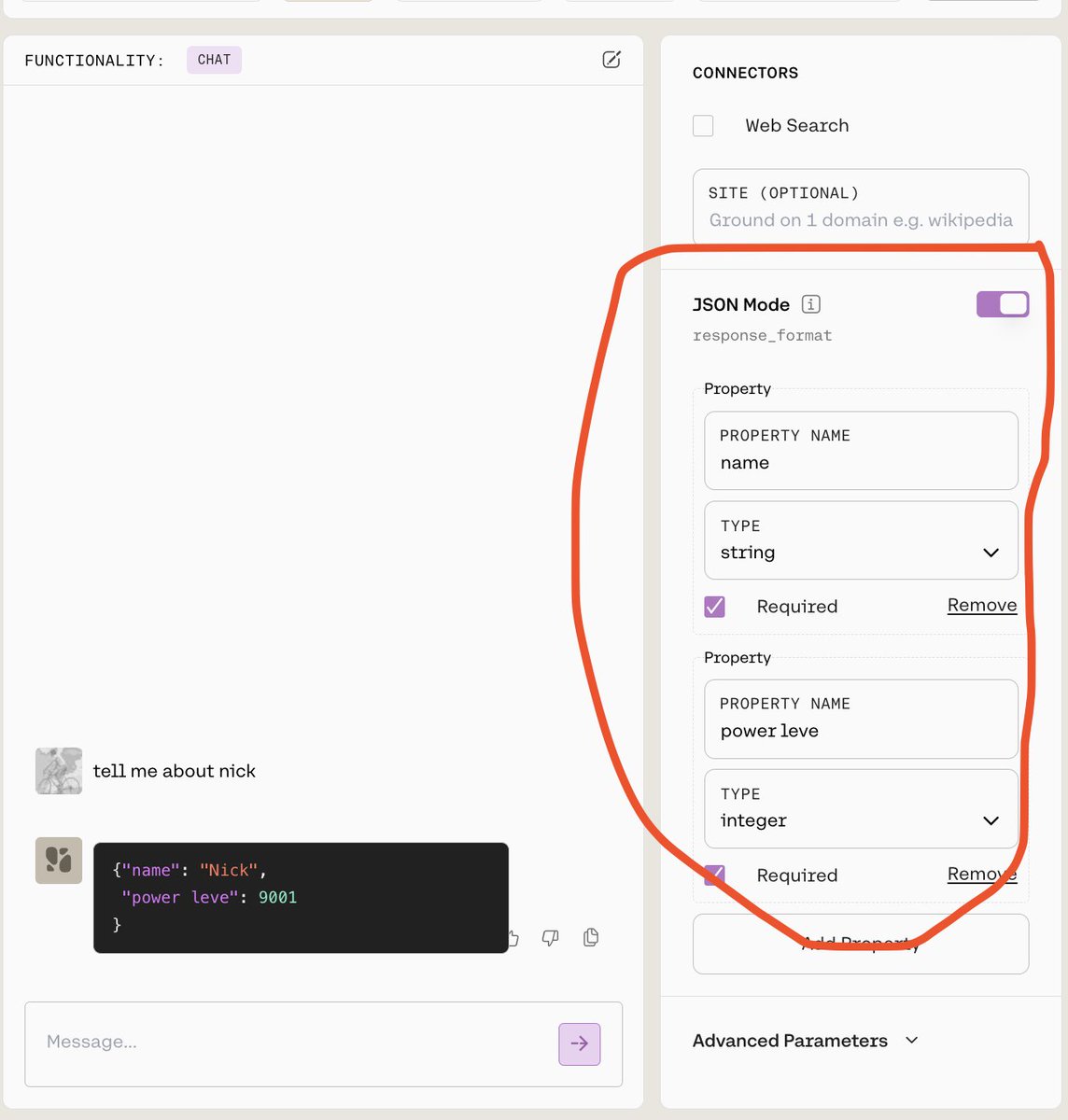
@cohere just shipped json schema sampling!
Now not only can you guarantee that the model returns valid json, you can actually ensure it returns json with a specific format!
Big win for people actually building with LLMs :)
https://t.co/fUEEqZxTAw
Exciting news - the latest Arena result are out!
@cohere's Command R+ has climbed to the 6th spot, matching GPT-4-0314 level by 13K+ human votes! It's undoubtedly the **best** open model on the leaderboard now🔥
Big congrats to @cohere's incredible work & valuable contribution to the open community!
More exciting updates:
- Qwen1.5-32B-Chat almost top-10
- Gemma-1.1-7B-it shows great improvement (1044 -> 1088, on par with Llama-2-70b)
- Starling-7B-Beta still the best 7B with over 13K votes!
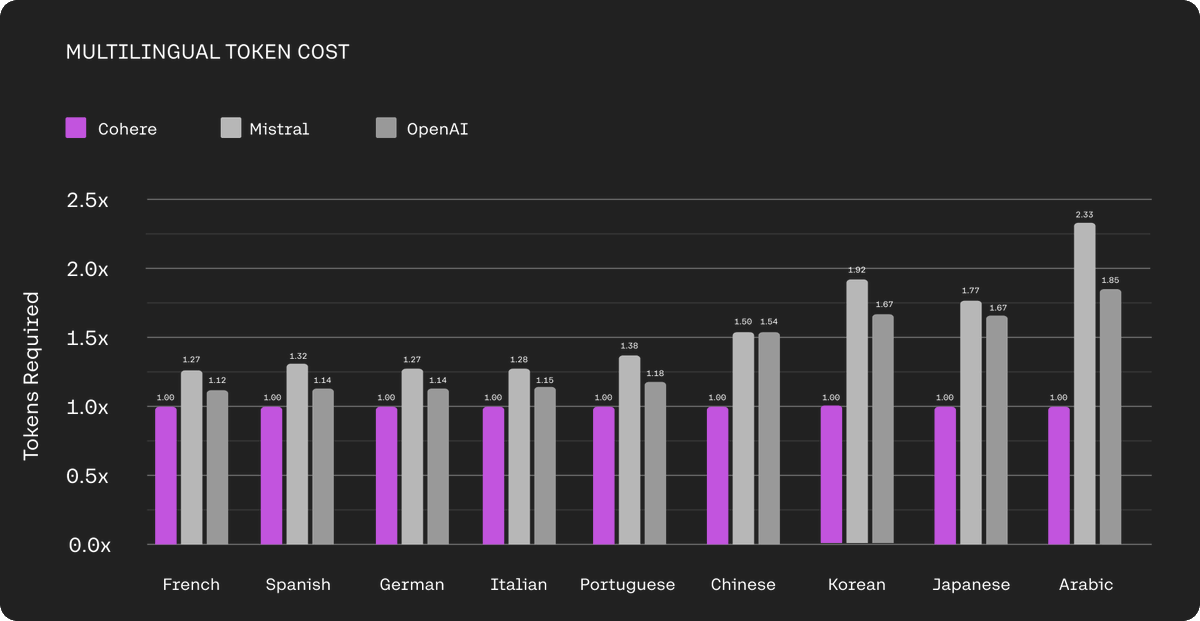
One subtlety worth mentioning is how significant the tokenizer is to the cost to use models in non-english languages. Our tokenizer is meaningfully better than others at the 9 non-English languages, achieving up to a 2x effective cost reduction to use.
Today, we’re introducing Command R+: a state-of-the-art RAG-optimized LLM designed to tackle enterprise-grade workloads and speak the languages of global business.
Our R-series model family is now available on Microsoft Azure, and coming soon to additional cloud providers.
Announcing C4AI Command R+ open weights, a state-of-the-art 104B LLM with RAG, tooling and multilingual in 10 languages.
This release builds on our 35B and is a part of our commitment to make AI breakthroughs accessible to the research community. 🎉
https://t.co/2UCLl5sfPB
⌘R+
Welcoming Command R+, our latest model focused on scalability, RAG, and Tool Use. Like last time, we're releasing the weights for research use, we hope they're useful to everyone! https://t.co/HgESxxEYlK