Can coding agents do research?
We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress
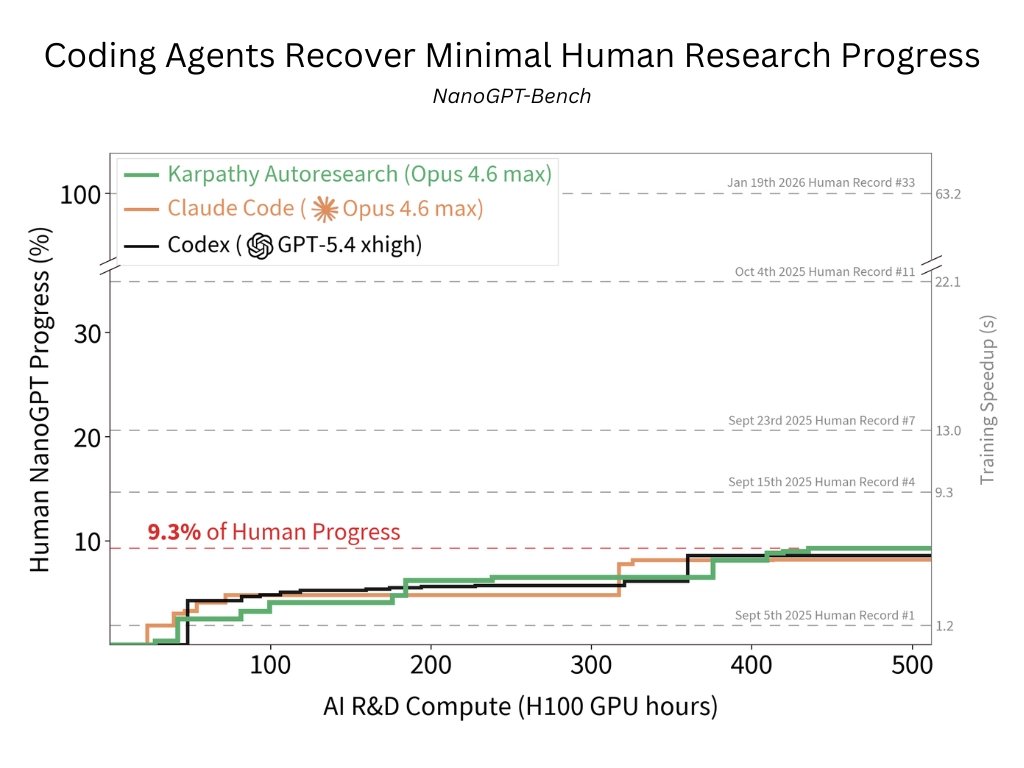
Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵
World record #31 (out of the 33 reference records) was achieved by Locus, our Artificial Scientist, on January 16th, 2026
Locus implemented a fused triton kernel for the softcapped multi-token prediction cross entropy step. Several future records by humans have built further on the kernel.
GitHub: https://t.co/2dtR04TnTR
We live in a golden age of biology. So why are people still dying from disease?
Because discovery and development move slower than they should.
Today, we’re partnering with Incyte to change that.
Kosmos is now the first agent that can compress months of drug development into weeks, from the earliest stages of scientific discovery through to FDA approval. @Incyte will be the first company to deploy it across their pipeline.
Work that used to take a team of scientists months now happens in weeks.
Patients can't wait, and neither can we.
We evaluated Codex, Claude Code, and @karpathy's Autoresearch on their ability to reproduce human progress on NanoGPT Speedrun!
Shoutout @kellerjordan0 & @classiclarryd
Can coding agents do research?
We release NanoGPT-Bench, an internal eval we’ve used to test agents on an AI R&D problem with months of human progress
Codex, Claude Code, Autoresearch recover only 9.3% of human progress, mostly tuning hyperparams & ignoring algorithmic research
NanoGPT-Bench is built on the NanoGPT Speedrun, a popular LLM pretraining competition to minimize the training time of a GPT-2 style model. Existing human submissions constitute nearly 2 years of work. To control for dependencies and contamination in frontier models, we standardize evaluation to a 5-month window of world records. Evaluation is fully autonomous and end-to-end, with no human intervention or internet access. 🧵
Genuinely horrific way to experience life and the people around you. People don’t try to make new friends because it’s “what you are supposed to do”. Life is given meaning by the wonderful people you meet along the way and choose to spend time with. You don’t have to be friends with everyone, but to shut off the possibility of new human connection due to a lack of calculated “ROI” is fundamentally misunderstanding of the human experience.
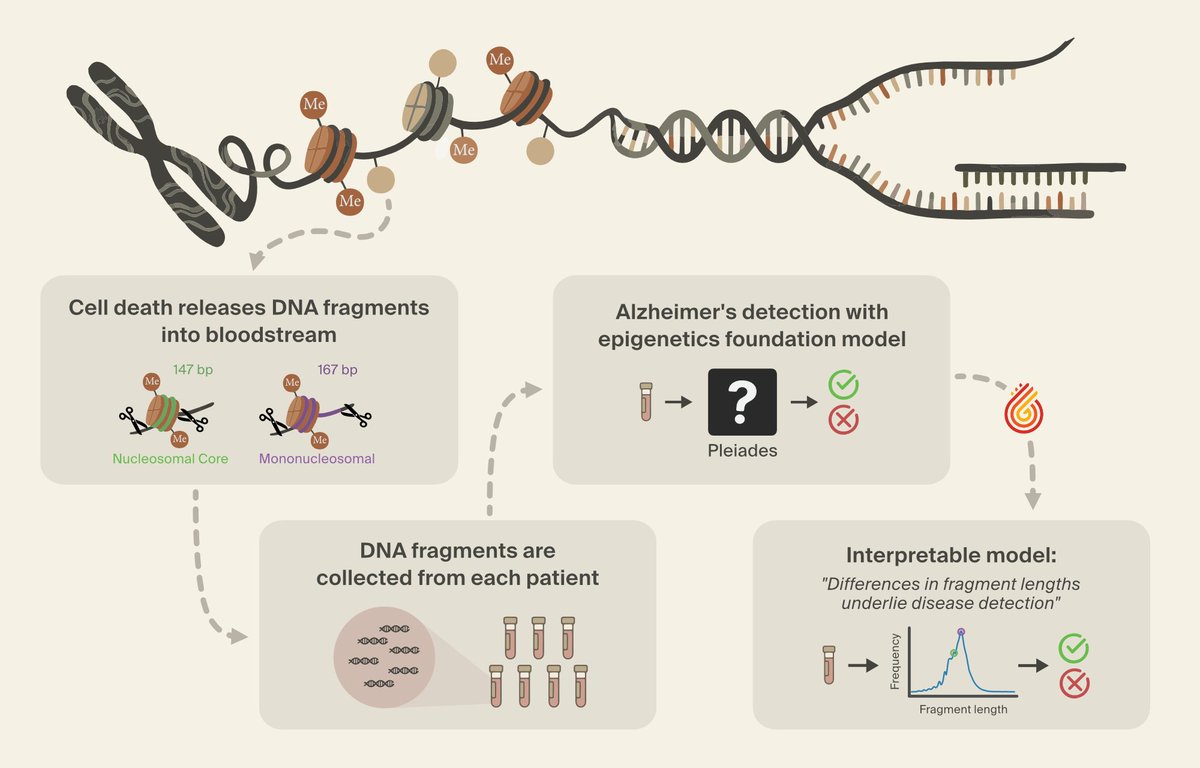
We've identified a novel class of biomarkers for Alzheimer's detection - using interpretability - with @PrimaMente.
How we did it, and how interpretability can power scientific discovery in the age of digital biology: (1/6)
I've joined @intology!
I'm excited to push the boundaries of AI-accelerated scientific discovery with an incredibly driven and talented team. Looking forward to dive deep into research on AI-driven automation and creativity!
New NanoGPT Speedrun WR at 105.9s (-1.0s) from @soren_dunn_ , with a triton kernel to fuse the logit softcap and multi-token prediction cross entropy calc. Interestingly, Soren mentioned that their autonomous system Locus at Intology discovered and implemented the improvement. https://t.co/eU5UZT3nYJ
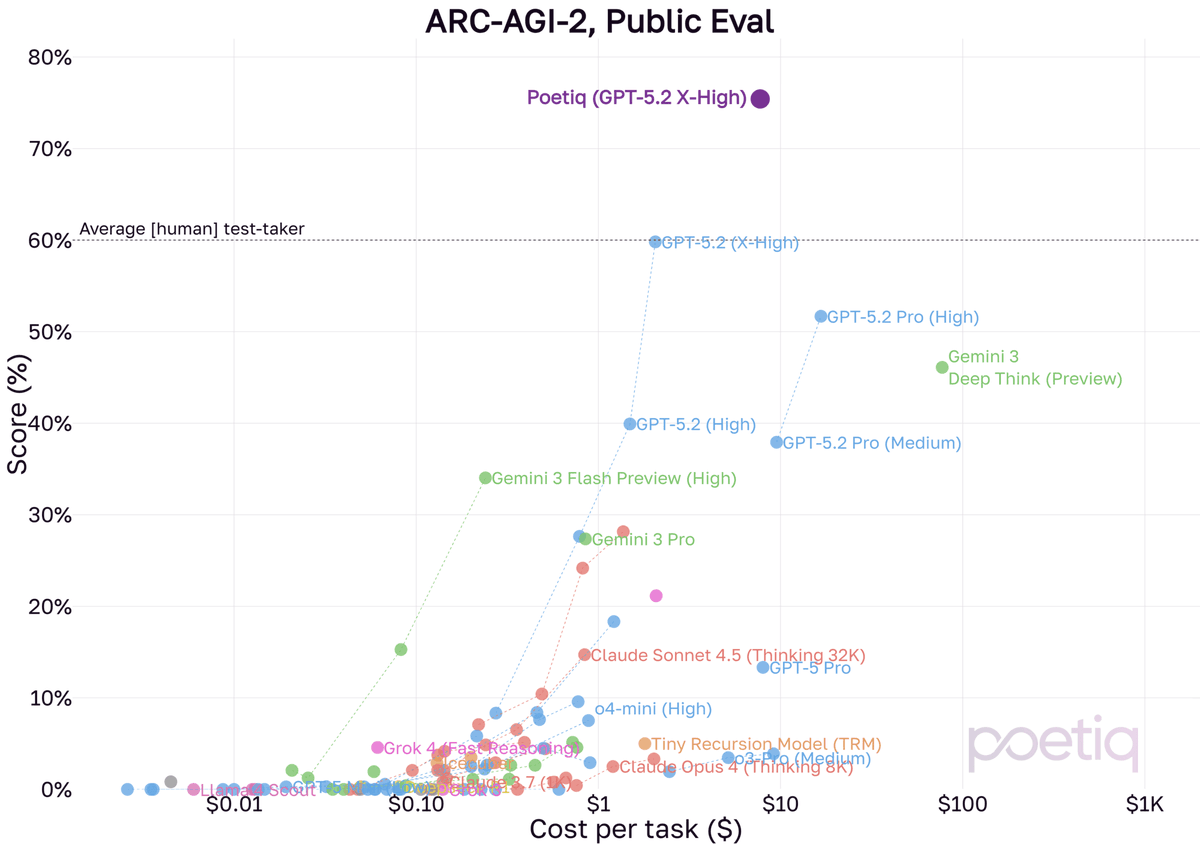
We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2!
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.