As token budgets take on a larger part of operating expenses over time, model routing is the inevitable conclusion. This is also one of the biggest areas of differentiation for the applied AI layer over time.
By understanding the different work patterns in your domain, and having strong evals for that domain, you’ll be able to cost/performance optimize effectively.
We’re still likely at the point where most use-cases will need frontier performance for the foreseeable future; but soon you will be able to peel off individual use-cases and send them to lower cost models once the quality is sufficient for the task.
Enterprises individually trying to figure this out themselves at scale will likely not be possible, so the products that can intelligently route these workflows to the right tier of model will be in a strong position to aggregate more demand.
People should really know that the any global config. e.g. .codex/config.toml is not a real way to contain agents. Your
trust_level = “untrusted”
sandbox_mode = “read-only”
... is a rules on the wall poster. The agent can ‘forget’ to look at it. And will.
- Tracking token burn
- easier ways to redress state
- not having to repeat yourself constantly
Different modes : vibe code yeah whatevs, but agentic pair programming, agentic intern, agentic backend - give them engineering personas and this will help keep them from repo so sprawl, token burn, and context rot
@thsottiaux - Multi codex agent communication
- agents that actually follow Agent.md or .codexignore
- identifiers for agents using your account so you can’t dustinguish who did what and which agent when
Can’t believe I coded by hand for 5 years
5 years of memorizing syntax, debugging at 2AM, Stack Overflow tabs, broken builds, cursed dependencies, merge conflicts, and “just one last bug before sleep.”
Learned DSA.
Learned system design.
Learned Linux.
Learned Docker.
Learned CI/CD.
Just to end up typing:
“fix this”
Into a chat box and watching an AI agent commit crimes faster than me.
Im gonna say it again Codex Usage limits are cooked.
This is the first week, I’ve had to hold back.
Im on 25x - soon 20x
Theres no way in this world, when they reduce limits Codex will even be usable beyond 3 days.
The battle is no longer the model. But the quota either lab provides.
🚨Two AI CEOs spent two years warning about a jobs apocalypse. This week they both took it back. Both companies are about to IPO at a trillion dollars.
On Tuesday in Sydney, Sam Altman told a banking conference he was "delighted to be wrong" about AI destroying entry-level white-collar work. This is the same Altman who called customer service jobs "totally, totally gone" and said work skills now have a two to three year half-life. He expected far more positions to have vanished by now. They have not.
Dario Amodei softened in the same window. A year ago the Anthropic CEO said up to half of all entry-level white-collar jobs would dissolve within five years and unemployment could hit 10 to 20%. This month his tone moved to something far easier for an enterprise buyer to hear.
The timing is the part worth noticing. Both OpenAI and Anthropic are reportedly preparing IPOs this year at an estimated trillion dollars each. A doom narrative is a problem when you are selling shares to public markets and software seats to nervous companies. The reversal reads the cap table as much as it reads the data.
And the data is mixed enough to make a clean reversal suspicious. The Yale Budget Lab found no meaningful change in unemployment for high-exposure jobs through March 2026. But tech layoffs this year already passed 115,000, near the full 2025 total, with Meta, Amazon and Snap naming AI as a driver. Altman himself accused companies in February of "AI washing," blaming AI for cuts they wanted to make anyway.
So the macro number stays flat while specific roles get hollowed out underneath it. Customer service. Entry-level coding. Junior analysts, who the banks already started cutting. The headline rate stays calm because the losses are concentrated, not broad.
They were wrong about the speed of the visible collapse. They were not wrong that your work is being handed to a model. They just learned it sells better to stop saying so right before an IPO.
Source: Reuters, Fortune, TIME, Yale Budget Lab
I think AI coding hype follows roughly four stages:
1. Amazement
You try it and can’t believe how much code it generates from a few prompts.
2. Expansion
You start more and more projects because shipping suddenly feels cheap and fast.
This is also the phase where people start convincing everyone around them:
- coworkers
- management
- friends in other companies
because nobody wants to “fall behind” in 6–12 months.
That creates a massive snowball/FOMO effect.
3. The grind phase
You realize the generated code has architectural issues, sloppy mistakes, weird abstractions, duplicated logic, broken edge cases, etc.
So you start:
- re-prompting
- switching models
- increasing reasoning effort
- reviewing fixes
- generating fixes for previous fixes
And suddenly you spend your days reviewing AI-generated pull requests instead of building software.
4. Realization
You realize AI coding increases output much faster than it increases certainty.
The code still needs:
- review
- testing
- ownership
- architectural understanding
- long-term maintenance
Usually by expensive senior engineers.
And the interesting thing is:
this whole cycle can take many months or even more than a year because people become socially and professionally invested in the narrative themselves.
Once teams, managers, and entire companies have been convinced that this is the future, it becomes psychologically and politically very hard to later say:
“Actually, the ROI is much lower than we expected.”
This is what we've been seeing with every company we work with.
Try justifying spending 100k on token spend when only 18k even makes it to a stable prod feature.
In the rush to maximize AI token spend, companies are wasting over 44% on bug fixes
Uber’s COO has said that it’s getting “harder to justify” its AI costs because there was no way to show a link between AI spend and any meaningful increase in useful features. This is the first time I’ve seen a company say this directly.
https://t.co/xUhZvtpwah
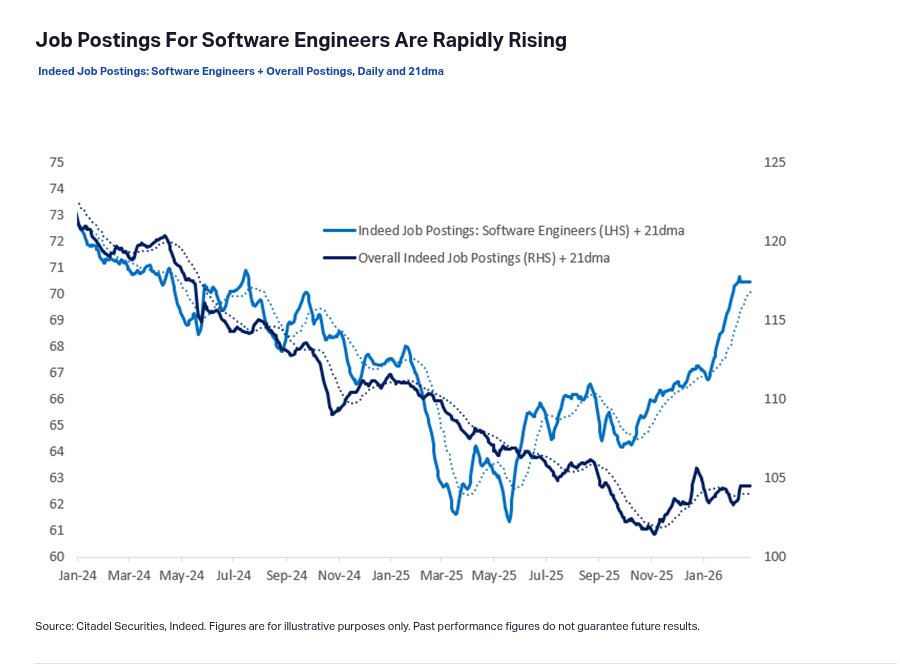
Q: How are job postings for software engineers rising rapidly despite AI agents automating coding?
A: Because there’s far more code to manage than ever before. We’re already seeing a 14x YoY increase in GitHub commits, and it’s accelerating.
AI has dramatically lowered the cost of writing code, so it’s now being used across far more businesses, applications, and use cases.
We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative.
TIL the hard way that codex sees .codexignore even when ! as a suggestion. And pretty much everything you tell it is a “well actually…”
So maybe the sycophancy isn’t so bad.