Data science in energy & ChE. Machine learning, molecular simulations, public policy, etc. Postdoc @ejmaginn @NDCBE, PhD with @SarupriaS. Views are my own.
Maybe, maybe not. Computers largely use numerical methods to do math instead of symbol manipulation. Meanwhile the LLMs themselves are fine for interpolating/manipulating human language, but that is much fuzzier and forgiving than formal logic/mathematical systems. And that’s all before you account for the difference in the amount of training data readily available.
JPMORGAN: “.. the US has achieved US energy independence for the first time in 40 years while Europe and China compete for global energy resources.” [Cembalest] #OOTT 🇺🇸
"The Tyranny of the Marginal User"
Why consumer software gets worse, not better, over time. Great post from @IvanVendrov, hard to not see it everywhere.
"Here’s what I’ve been able to piece together about the marginal user. Let’s call him Marl."
https://t.co/MVxAazFO0z
This has to be one of the more egregious headlines I’ve seen. IF humans still exist in 250MM years and IF we aren’t already off earth I’d think we’ll have plenty of time to engineer our way around such challenges. The research is probably 😎😎😎, but the headline 🙄🙄🙄
Good fun using known methods to address an engineering application. The latest with @ejmaginn. Many thanks to Ning Wang for pulling this across the finish line. https://t.co/2iOckhwQLd
Check out the latest on heterogeneous ice nucleation from @SAMPELatUMN. Great work all around and fun to be involved after so many years. https://t.co/ap9EzIWLXd
It's new paper day! MoSDeF-GOMC simplifies input file generation with @mosdef_hub (MoSDeF) for @GPUMonteCarlo (GOMC), and also provides support for complex workflows with @signacdata. Also a great resource for teaching Monte Carlo simulation.
https://t.co/k4hwP81yTT
The ability to train big models is not a moat. Anyone with enough budget can replicate your model in a matter of months.
A much better moat is to have a novel and clever way of using AI in a useful product.
Replica exchange is a popular method for improving sampling in #MolecularDynamics. #NormalizingFlows are a promising deep generative method. Their combination can reduce the computational cost of both by orders of magnitude! @inve_michele@FrankNoeBerlin
https://t.co/9RKRN3G29H
Take: Acceptance criteria for AI systems is going to be much higher than for humans performing the same task. Someone is always going to prod the system and say “well that’s a dumb/bad/misleading answer/decision” without realizing just how bad many human-informed decisions are.
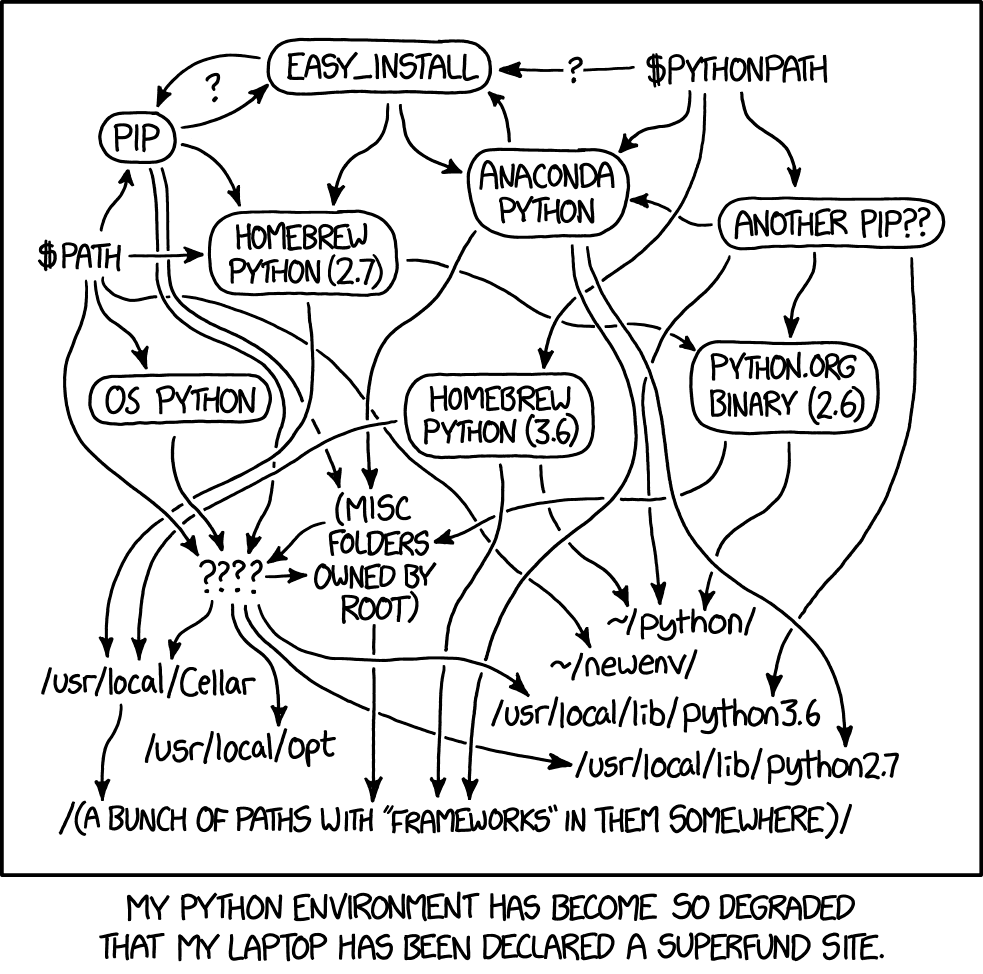
This (crazy dependency trees that could be susceptible to malicious code in downstream packages) strikes me as a major issue with the Python open-source ecosystem (e.g., conda, pypi).
It's good that PyTorch found this so quickly.
However it makes me worry that many packages share this issue without realizing. You could easily clone pip wheels and add exploits without being obvious.
The fragmentation of the ecosystem (see xkcd) is seeing some consequences...
@andrewwhite01 Accessible + license file. Outside of personal use I’m be hesitant to touch anything without a license file, so it’s hard to say it’s “open source”.





























![carlquintanilla's tweet photo. JPMORGAN: “.. the US has achieved US energy independence for the first time in 40 years while Europe and China compete for global energy resources.” [Cembalest] #OOTT 🇺🇸 https://t.co/D8QMkssO4m](https://pbs.twimg.com/media/GIHELytXEAA21GB.jpg)