Can we find weight directions to modify LLM's behaviors?
Our new paper proposes contrastive weight steering, an alternative to activation steering for modifying behaviors using small narrow distribution data 🕹️
🧵👇
I’m really sad that my dear friend @FelixHill84 is no longer with us. He had many friends and colleagues all over the world - to try to ensure we reach them, his family have asked to share this webpage for the celebration of his life: https://t.co/1QoyHmAD3p
Thank you very much Adina, Ellie @Brown_NLP and @delliott for serving as members of my PhD committee! I enjoyed and learned a lot from our conversations. I hope our paths cross in the future!
Join me in extending the heartiest congrats to Dr. @ruixiangcui upon his successful and enlightening PhD defence today! It was my honor and privilege to be a part of your research story, Rui! I look forward to the impressive work you will do in your next chapter! 🎉
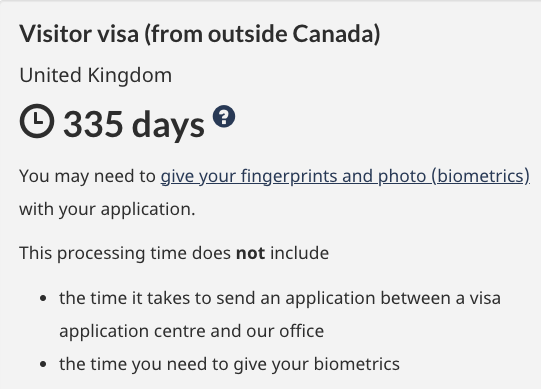
Thanks @aclmeeting for hosting the conference in Canada while ignoring all nationalities who won't be able to participate due to the strict visa procedure!
Given this, kindly stop claiming too much about the importance of diversity, equity & inclusion!
#ACL2023#ACL2023NLP
🚀 Accepted ACL 2023 main track🚀
I am pleased to announce the acceptance of our paper, "What does the Failure to Reason with 'Respectively' in Zero/Few-Shot Settings Tell Us about Language Models?" @ruixiangcui , Seolhwa Lee, @daniel_hers , Anders Søgaard
#NLProc#ACL2023NLP
Check out AGIEval, the bilingual benchmark to evaluate LLMs on human-centric tasks that I gladly contributed during my MSFT internship! Our release includes task data and model outputs for GPT3.5 and GPT-4, saving you time and effort in analysis and comparison.
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
GPT-4 surpasses average human perf on SAT, LSAT, and math competitions, attaining 95% on SAT Math.
repo: https://t.co/2GxabmiXaM
abs: https://t.co/Y6rTfGVC6d