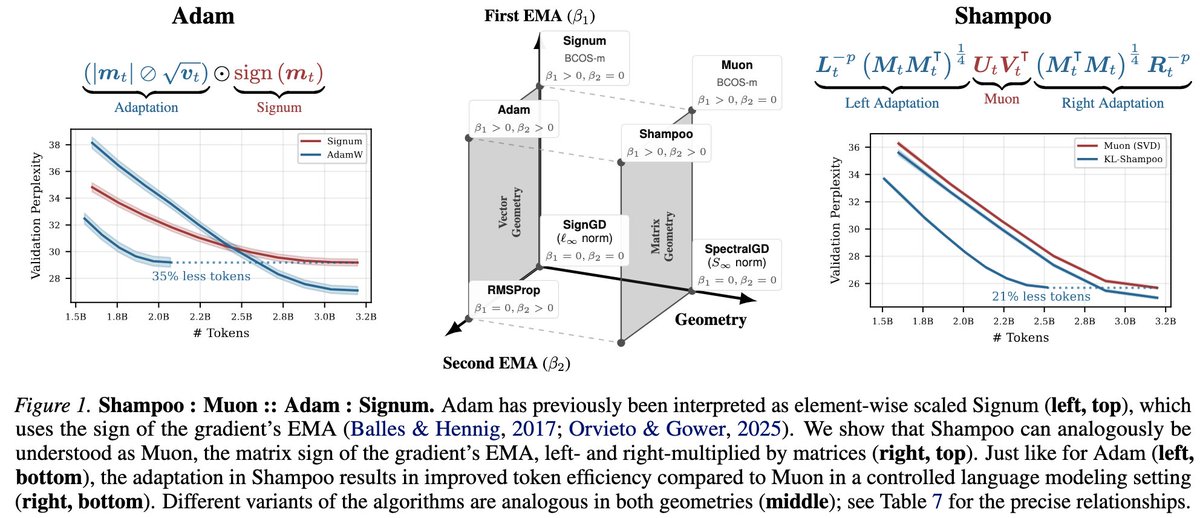
1/14 Is Muon “better” than Shampoo?
We argue that their relationship parallels Adam's relationship with Signum. Analogous to @lukas_balles and Hennig’s (2018) decomposition of Adam into element-wise scaled Signum, we can decompose Shampoo as left- and right-adapted Muon.
Awesome to see this work from Marin.
One detail I’m especially pleased about: their final recipe adapts ideas from our Complete(d)P work, especially horizon and batch-size hyperparameter transfer, and they verify it scales to very large scales.
🚨 New Paper 🚨
ScheduleFree+: Scaling Learning-Rate-Free & Schedule-Free Learning to Large Language Models
A few modifications to Schedule-Free Learning make it completely LR tuning free, and allow it to greatly outperform schedules for long duration training!
https://t.co/LzjIIsOlG8
Ownership is the biggest factor in quality research: do the drivers of the work actually feel a stake in its success, a sense of responsibility and autonomy, resilience, and a desire to make a contribution that transcends a conference publication or an immediate reward signal?
Many believe that optimizers like Muon perform well because of their connection to spectral geometry.
But this is not the case!
In fact, replacing the spectrum of the update with random or even inverted singular values performs remarkably similar!
https://t.co/qxGQBvEuml
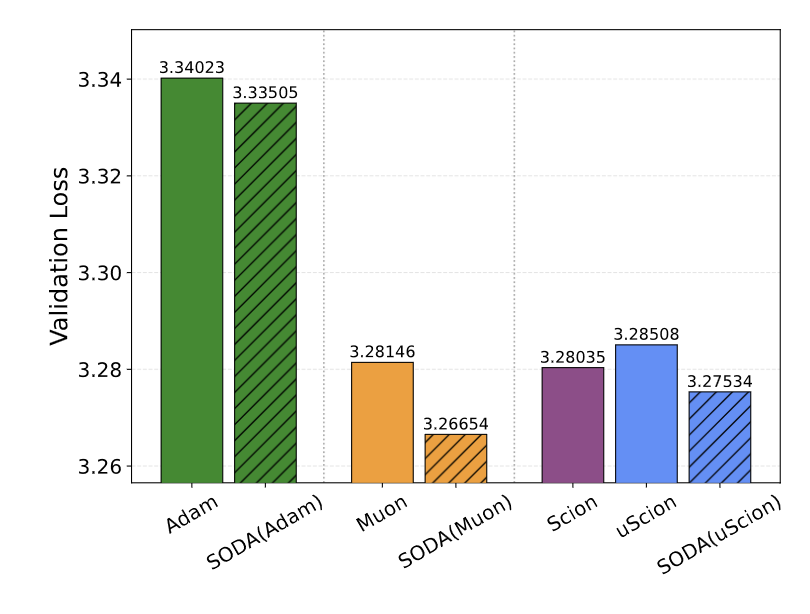
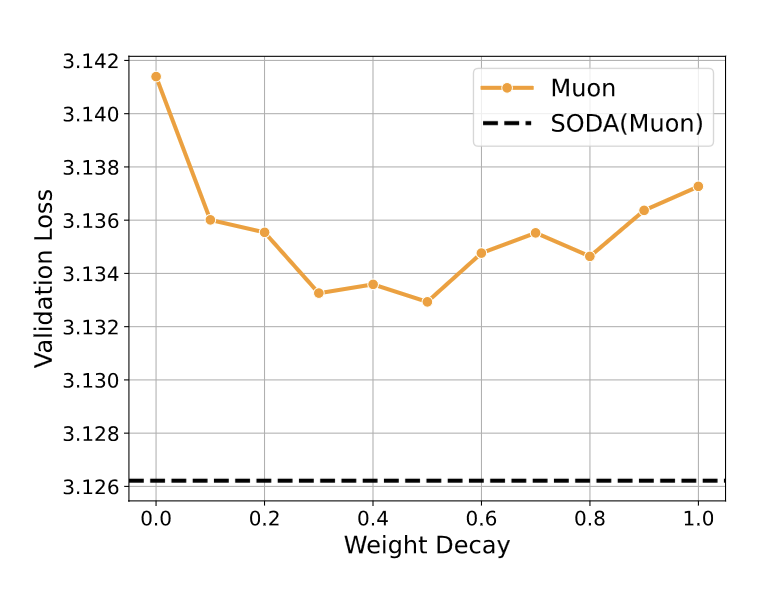
1/ We introduce SODA: a simple optimizer wrapper that improves a base optimizer, adds no hyperparameters, and removes the need to tune weight decay.
The wrapper provides consistent improvement. Most notably, SODA(Muon) beats Muon even when Muon gets a tuned weight decay sweep.
the sloptimizer field is just getting started with shampoo and muon gen algorithms, the graveyard of adam variants got so bad you can't list them all on a page
I've been really impressed with Typst for a while, but today I discovered their document compiler is so fast someone built a 3d game that runs in the online IDE.
You move by typing and the results are instantly rendered live in the document preview.
trained the first natural language autoencoder on gpt-2 almost a year ago, now we have one on mythos.🥲
do read the paper/play with the live demo! so excited it's finally out.
KL Shampoo and KL SOAP outperform their non-KL counterparts by learning the preconditioners compositionally, so that each stage corrects what remains after the last.
Available in HeavyBall 3.1.1, with major PSGD stability backports.
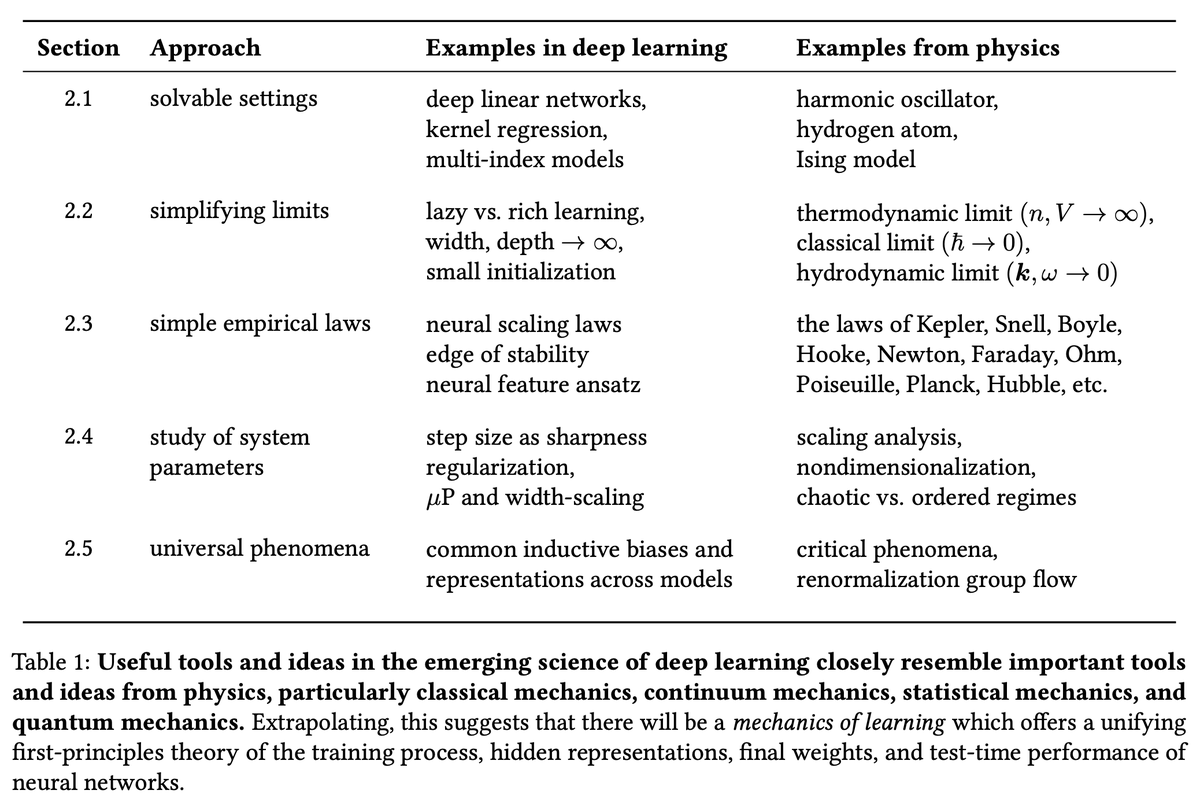
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
If you want to work with our group while living in New-York and also spend time in Tokyo and Germany!, check out the new positions available at the NYU and Flatiron Institute by @cosmo_shirley
post-doc: https://t.co/TvVTBiAiol
research-scientist: https://t.co/ivqess9uKb
I'm surprised this flew under my radar, seems like a very cool paper
You can extend µP almost trivially to the Mixture of Expert setting if you keep the number of experts fixed. A proper handling of hyperparameters in the MoE setting through large number of expert asymptotics has seemed elusive, so it's awesome to see it done!
Excited to share our new paper on sharp capacity scaling of the Muon optimizer! Joint work with @EshaanNichani Denny Wu @albertobietti@jasondeanlee:
https://t.co/v1k1B4mSkG (1/7)
1/10 Are DiLoCo and Schedule-Free actually related? A brief history and unusually late advertisement for our work: Smoothing DiLoCo with Primal Averaging for Faster Training of LLMs (see https://t.co/ESaSU8kwpx).