North Carolina scored the largest manufacturing investment in the state's history at $4.6B.
JezZero is breaking ground on the first greenfield large-aircraft production facility built in the United States in a generation.
The Z4 blended-wing-body (BWB) is the first clean-sheet American commercial aircraft program in 15 years.
The 8 million sqft facility will employ 14,500 direct, high-wage aerospace workers.
Open your eyes 🇺🇸
that's the best annotation. we are experience another productivity revolution. that's why you see new leaders rise and losers fade.
yet this time, financially, market is actually much more sober comparing to dot com.
anyone don't see this is either blind or choose to be blind.
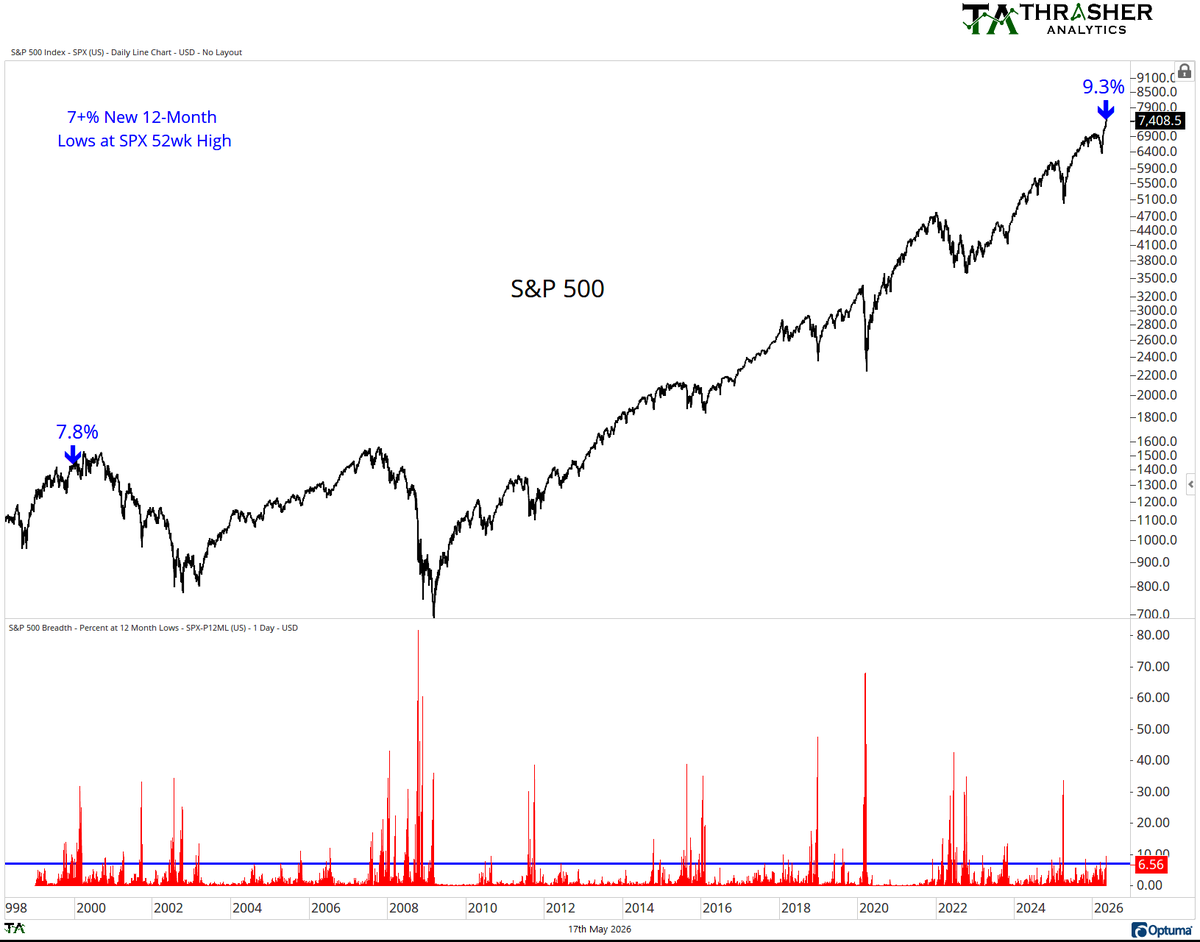
In the last almost 30 years, the number of times there's been at least 7% of stocks making a 52-week low when the S&P 500 was at a 52-week high: Two
Earlier this morning, I shared my thoughts on Substack about bottlenecks in general, and specifically about InP and $SIVE. Based on the feedback, the article was well received. If you’re interested, you can find it directly here
These are just my thoughts, and I don’t claim to be always right.
https://t.co/oLUdlDIG4F
We've published a paper that explains our views on AI competition between the US and China.
The US and democratic allies hold the lead in frontier AI today. Read more on what it’ll take to keep that lead: https://t.co/TgJBeodWYK
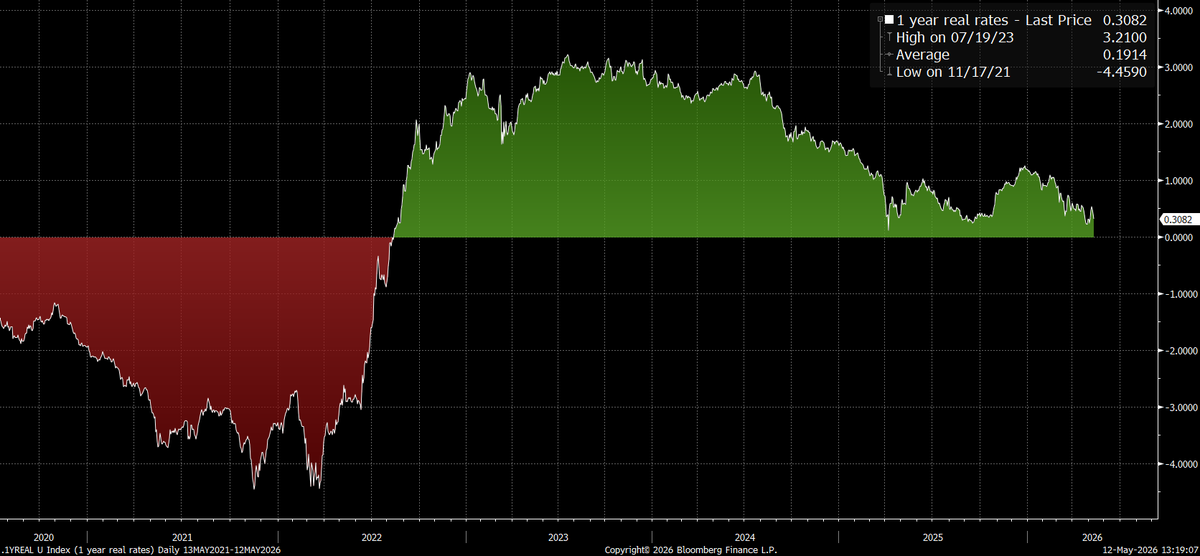
1y real rates have fallen and now sit only 30bps from turning negative. The last time real rates turned negative like this was during the credit cycle melt up of 2021
This is one of the most important datapoints to show people who want to keep denying that markets cant go higher. I assure you, markets can go higher.
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️