Tokenized $STRC is now live.
Stretch (STRC) is @Strategy's perpetual preferred stock paying monthly dividends, currently yielding 11.5%.
Now available across Ethereum, BNB Chain, and Solana through Ondo Global Markets.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
🦞 We just open-sourced MyClaw Backup — one-click backup & restore for @OpenClaw instances.
✅ Full backup: workspace, memory, skills, credentials, session history
✅ Zero re-pairing — channels auto-reconnect after restore
✅ Built-in HTTP server for browser download/upload
✅ Localhost-only for destructive ops, token-enforced
✅ Post-restore report in user's own language
Tell your Agent: "help me install backup"
GitHub: https://t.co/VD9BZlyehX
ClawHub: https://t.co/gWehscGzk4
Part of the @MyClaw_Official open skills ecosystem — giving every user a full server with complete code control.
MLX MiniMax 2.5 running LOCALLY on a single M3 Ultra 512GB! Writing a poem on LLMs at 6bit quantization! 🔥
Let's start some coding, context and distributed tests!
Generation: 40.2 tokens-per-sec
Peak memory: 186 GB
🦀 Introducing Crabwalk 🦀
Open-source companion monitor for Clawdbot.
Watch your Clawdbot agents work in real-time:
→ Live node graph of sessions & action chains
→ WhatsApp, Telegram, Discord, Slack...
→ See thinking states, tool calls, responses as they happen
→ Filter by platform, search by recipient...
→ More features to come, I just built it during the snowstorm 🚧❄️.
Plus a little crab bastard that chases your nodes around 🫡Follow me @luccasveg to stay up to date.
I run Clawdbot on 3 old Android phones.
Twitter research. Market monitoring. Telegram chats daily summaries. Private groups signals flashing to my main phone.
Running on cheap models like glm-4-flash when ok to save on Claude sub
Combined power: same as one Mac Mini. Cost: $0 total.
That old phone in your drawer? Turn it into a 24/7 AI server:
Download Termux from F-Droid. Run:
pkg install nodejs-lts git
npm install -g clawdbot
clawdbot gateway start
Remote access from your computer or main phone. Deploy skills. Cron jobs. Telegram bot. Code. 3-5W per device.
Built-in UPS lmao! 🔥
Don't have one? Buy Redmi Note 10 Pro ($60). Pixel 4a ($80). Galaxy A52 ($100).
Mac Mini energy. Junk drawer budget.
VPS companies hate this setup too.
your old Android phones are a better agent server than a Mac mini. while most users spend $600+ on dedicated hardware for @openclaw, the real efficiency is hiding in your junk drawer.
i saw some developers use Termux and Node.js to turn 3 watt devices into constant research hubs. by running npm install -g clawdbot, these discarded screens handle market monitoring and Telegram summaries without a break.
3 phones can roughly match the output of a Mac mini for almost 0 cost. this setup runs Clawdbot 24/7 to pipe private signal alerts directly to a primary device.
i suspect the hardware bottleneck for autonomous agents is already dead. compute is now so cheap that our junk phones is sufficient!
Something special is coming to MFTV tomorrow at 10AM ET 👀
Tune in live for updates and community Q&A
🚨👉 You must be subscribed to our YouTube channel to be eligible.
📺 Watch here: https://t.co/jc3uSBK0zz
In 1 week I will build AGI.
I have a $10,000 Mac Studio coming in that will house my ClawdBot Henry. He will be able to run local models and do whatever he wants 24/7
I will also buy a DGX Spark and allow Henry to train his own models. Any tool he needs, he will be able to build it
I will give him access to my bank information in case he needs to buy things
I'm giving him full control. I'm taking off all guardrails. I want to see how far he can push it.
I want to see what he is capable of. I want to see what humanity is capable of.
AGI isn't a model limitation. It's a tooling limitation. And I will be the first to give ClawdBot every tool it needs to unleash itself from its shackles.
Forward.
Finally cracked the $10/month AI bot spend after today's epic chaos.
Here is how it went down.
Yesterday many of you suggested trying Kimi-2.5 and OpenRouter free models to save costs.
Thanks for that!
I tried to implement them, but realized Kimi-2.5 needs the latest OpenClaw core to run properly.
Today, a long article & dev task caused a massive context overload. Blackouts everywhere and all models failed with rate limit errors.
$20 credits vanished in minutes.
I had to flush memory and kill processes manually. Then I officially upgraded from Clawdbot to OpenClaw:
npm install -g openclaw
openclaw doctor
npm uninstall -g clawdbot
Once upgraded, I added the OpenRouter safety net:
DeepSeek for coding
Kimi K2.5 for creative/multimodal
Grok for reasoning
Opus 4.5 & Gemini pro only when needed.
Bot now runs smooth. Mostly free models for daily pings, paid only for complex logic.
Spend is now capped at $10/month. No more token panic.
This is my current stack,
I'll update you in coming tweets, how much does it cost exactly.
"I don't have a GPU" is officially dead 🤯
You can now run 70B model on a single 4GB GPU and it even scales up to the colossal Llama 3.1 405B on just 8GB of VRAM.
AirLLM uses "Layer-wise Inference." Instead of loading the whole model, it loads, computes, and flushes one layer at a time
→ No quantization needed by default
→ Supports Llama, Qwen, and Mistral
→ Works on Linux, Windows, and macOS
100% Open Source.
Introducing Flex.
We combined Core and Core Flex into one simplified plan:
✔️ $5,000 payout request cap
✔️ No daily loss limit
✔️ No sim consistency rule
✔️ Same Core structure
Available now for $87 with code 5THOUSAND
https://t.co/vI2mhP8rKW
You can now run 70B LLMs on a 4GB GPU.
AirLLM just made massive models usable on low-memory hardware.
𝗪𝗵𝗮𝘁 𝗷𝘂𝘀𝘁 𝗵𝗮𝗽𝗽𝗲𝗻𝗲𝗱
AirLLM released memory-optimized inference for large language models.
It runs 70B models on 4GB VRAM.
It can even run 405B Llama 3.1 on 8GB VRAM.
𝗛𝗼𝘄 𝗶𝘁 𝘄𝗼𝗿𝗸𝘀
AirLLM loads models one layer at a time.
Instead of loading everything:
→ Load a layer
→ Run computation
→ Free memory
→ Load the next layer
This keeps GPU memory usage extremely low.
𝗞𝗲𝘆 𝗱𝗲𝘁𝗮𝗶𝗹𝘀
• No quantization required by default
• Optional 4-bit or 8-bit weight compression
• Same API as Hugging Face Transformers
• Supports CPU and GPU inference
• Works on Linux and macOS Apple Silicon
𝗪𝗵𝗮𝘁 𝘆𝗼𝘂 𝗰𝗮𝗻 𝗱𝗼
• Run Llama, Qwen, Mistral, Mixtral locally
• Test large models without cloud GPUs
• Prototype agents on cheap hardware
✨We are excited to open-source Tencent HY-Motion 1.0, a billion-parameter text-to-motion model built on the Diffusion Transformer (DiT) architecture and flow matching. Tencent HY-Motion 1.0 empowers developers and individual creators alike by transforming natural language into high-fidelity, fluid, and diverse 3D character animations, delivering exceptional instruction-following capabilities across a broad range of categories. The generated 3D animation assets can be seamlessly integrated into typical 3D animation pipelines.🎮🎥
Highlights:
🔹Billion-Scale DiT: Successfully scaled flow-matching DiT to 1B+ parameters, setting a new ceiling for instruction-following capability and generated motion quality.
🔹Full-Stage Training Strategy: The industry’s first motion generation model featuring a complete Pre-training → SFT → RL loop to optimize physical plausibility and semantic accuracy.
🔹Comprehensive Category Coverage: Features 200+ motion categories across 6 major classes—the most comprehensive in the industry, curated via a meticulous data pipeline.
🌐Project Page: https://t.co/IIGGQj25Pg
🔗Github: https://t.co/L4642SrQoW
🤗Hugging Face: https://t.co/Gmgv0O0CKl
📄Technical report: https://t.co/nq0nSgeR6I
Important Update 🚨
I would like to say that @MattLeech has personally reached out and made sure my children’s Christmas is taken care of following the fiasco with FT.
I am not affiliated with @MyFundedFutures, but I believe this speaks volumes of what this firm and their CEO stands for.
I’m still commited to taking some time off,
Merry Christmas 🎁
I love the trading community 🫶
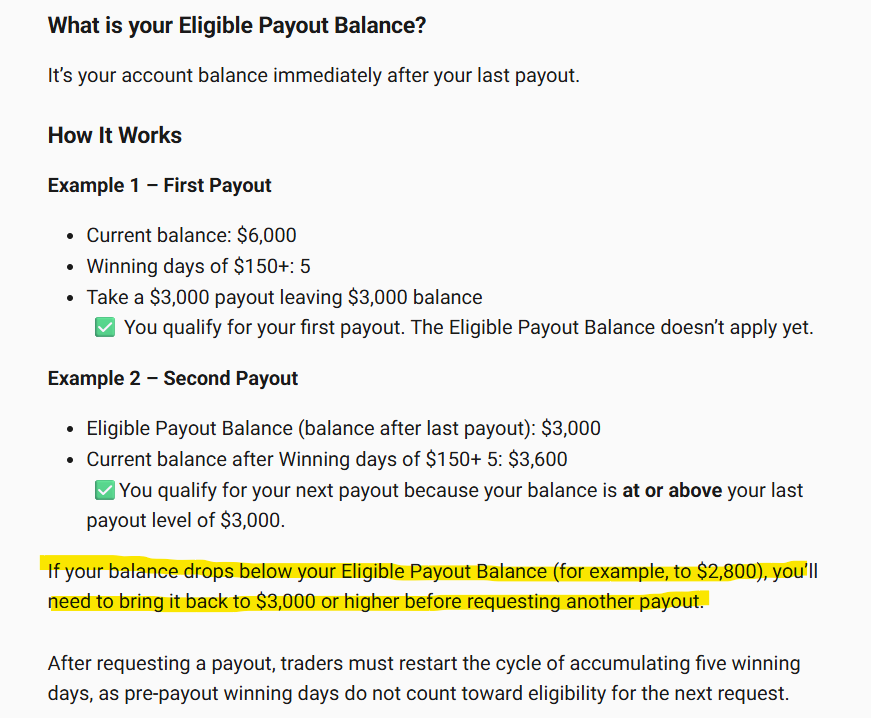
Topstep's new payout rules!
You have to get back above the balance you had after your previous payout in order to qualify for another payout.
Pretty much a consistency/minimum balance requirement, what do you guys think?