Grok 4 Fast is out, for free for everyone!
It pushes the frontier of reasoning efficiency and search 🚀
Join our team to maximize intelligence density
https://t.co/e5dAWzSM16
Introducing Grok 4 Fast, a multimodal reasoning model with a 2M context window that sets a new standard for cost-efficient intelligence.
Available for free on https://t.co/AnXpIEOhOD, https://t.co/53pltypvkw, iOS and Android apps, and OpenRouter.
https://t.co/3YZ1yVwueV
Glad to see this -- renderers are a foundational component of the LLM stack. Renderers map between tokens and messages, which are invariant to tokenizer and formatting details. Most APIs, datasets, and RL environments are defined in terms of messages.
Getting the details wrong leads to train-test mismatches, caching inefficiencies, and prompt injection vulnerabilities. We included a renderers module in Tinker Cookbook, but it makes sense as a standalone library.
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below!
with @AlecRad and @status_effects 🧵
I'm thrilled to join @xAI and @SpaceX!
After many years at Google DeepMind working on Gemini (including co-founding and launching Gemini Diffusion at Google I/O and contributing to Gemini, Gemma, AlphaCode, and Waymo), I can't wait to see what we build together.
Few places turn science fiction into reality this fast. We're forging Grok into the most capable assistant yet, making physical intelligence real, and taking it all to Space.
The last few years have been intense, but what's ahead is on another level. No better time to build — we can watch from the sidelines or be part of it. DMs are open.
Understand the Universe 🚀
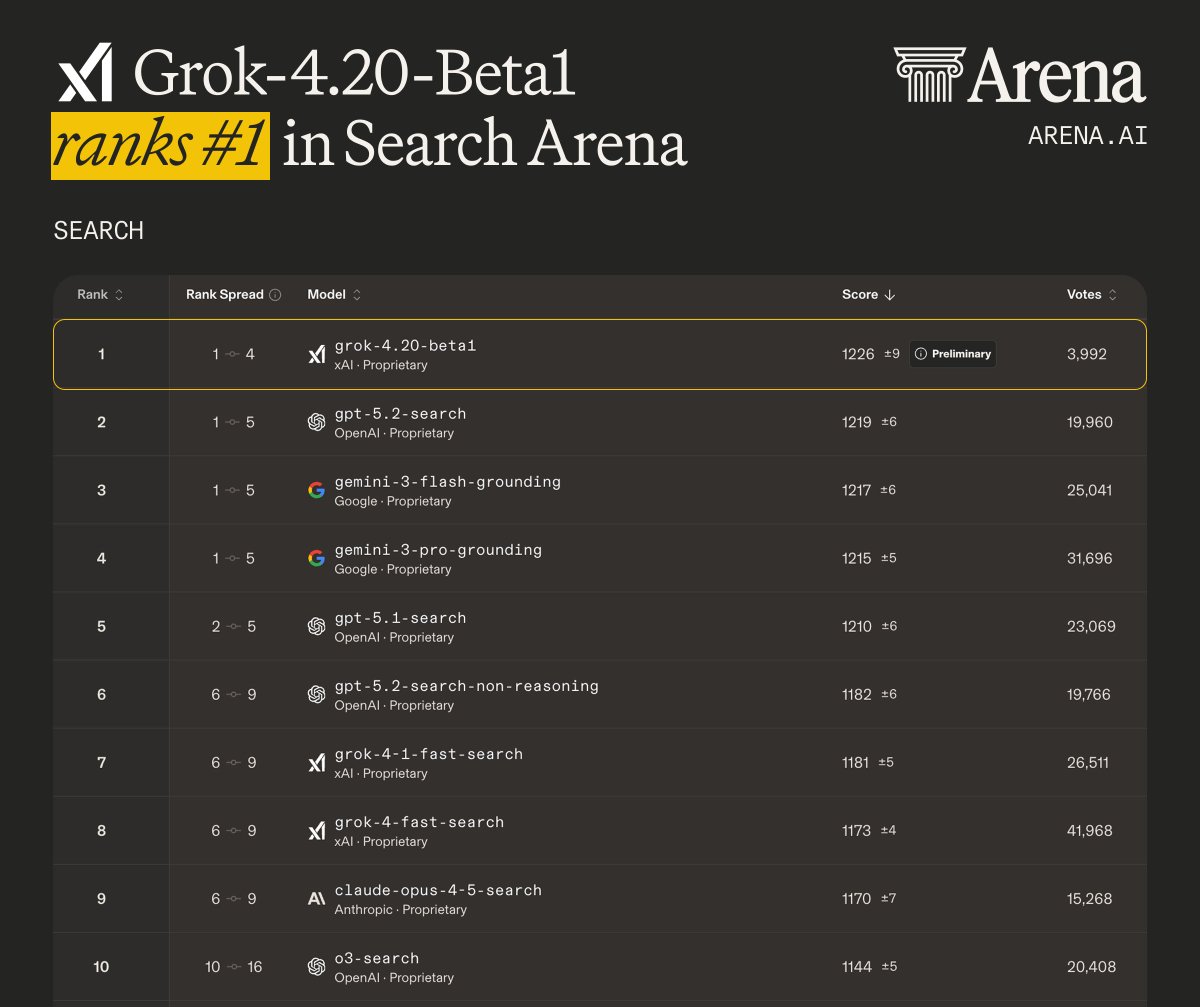
Grok 4.20 beta1 (single agent) debuts #1 on Search Arena, and #4 overall in Text Arena!
Highlights:
- #1 in Search, scoring 1226, leading GPT-5.2 and Gemini-3
- #4 in Text, scoring 1492 on par with Gemini 3.1 Pro
Congrats to the @xAI team and @elonmusk on this impressive milestone!
@Yuhu_ai_ Over the past five years you’ve been an extraordinary mentor and a constant source of inspiration for my career in AI. The last 2.5 years creating together at xAI have been some of the most rewarding of my professional life. I’m really going to miss working with you
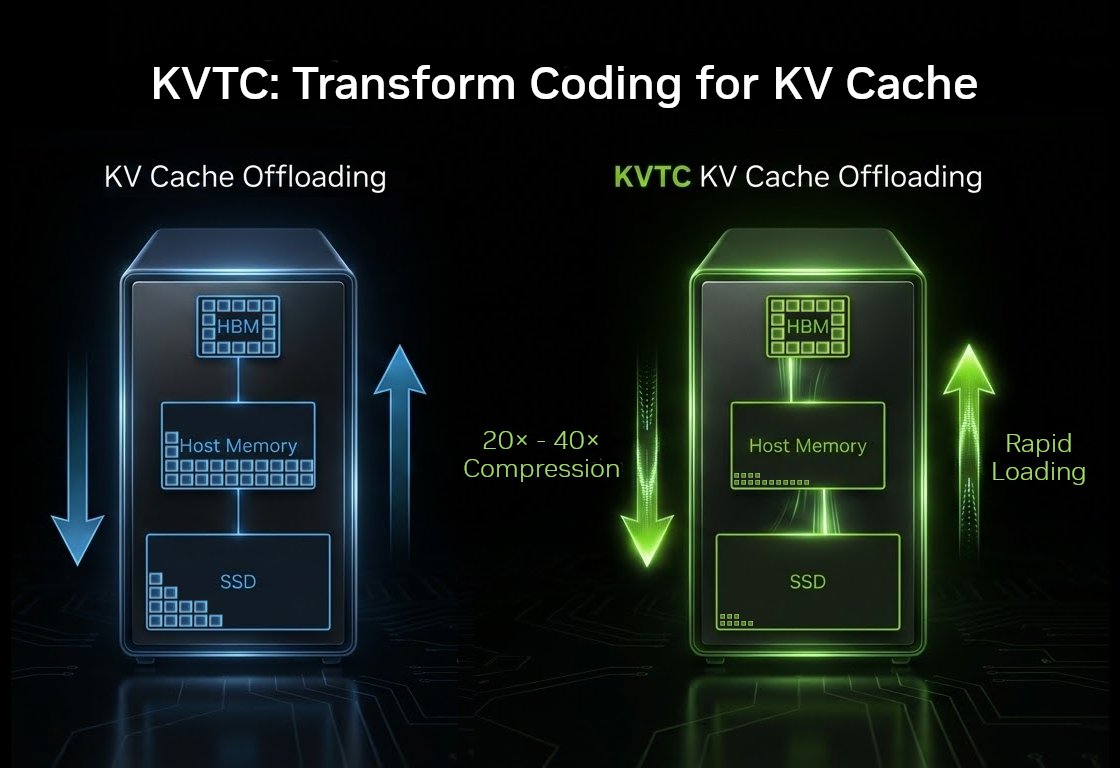
🚀📉 Storing KV Cache just got 20-40× cheaper
#NVIDIAResearch#ICLR2026
Introducing KVTC: A new KV cache transform coder (think JPEG for KV caches) that solves the "recompute vs. offload" dilemma. It achieves 20×-40× (up to 88×) near-lossless compression, redefining how we handle long-context memory.
Unlike eviction methods that permanently delete tokens, KVTC uses PCA-based decorrelation and adaptive quantization to compress caches for storage and transfer. This makes it perfect for:
• Multi-turn chats with long contexts: extends 20× - 40× the KV cache lifetime, e.g., for long sessions with AI coding assistants.
• Virtually increasing memory capacity: compression of unused KV caches in DRAM, SSD or HBM allows to store 20× - 40× more.
It’s a plug-and-play building block compatible with #FlashAttention, #PagedAttention, and #SparseAttention. We validated KVTC across model scales from 1.5B to 70B parameters, maintaining high accuracy on Reasoning (AIME25), CoT (GSM8K), and Long-Context Retrieval (RULER) tasks.
Co-authored with amazing @CStanKonrad .
Link in the comments 👇
🚀📉 Efficient Inference Just Got a Major Upgrade
#NVIDIAResearch
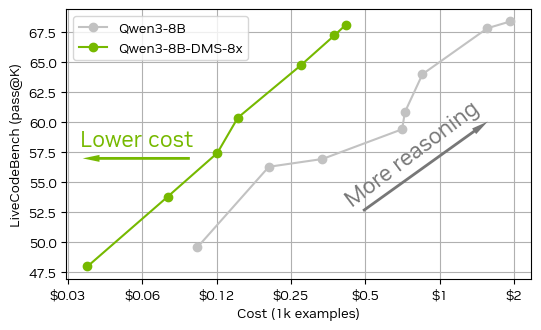
We’ve just released Qwen3-8B-DMS-8x fine-tuned for 8x KV cache compression. It maintains dense model accuracy on demanding tasks like AIME24, and is perfect for inference-time scaling. The code on HF works out-of-the-box.
With DMS we fine-tune models end-to-end via distillation; this works much better than “token importance” proxies found in usual eviction methods. It’s state-of-art for KV eviction tailored for fast inference: adds negligible amount of parameters and computation to each KV head, and requires as little as 1K fine-tuning steps to reach 8x compression. It speeds-up both prefill and generation phase of Transformer LLMs, and can be combined with Sparse Attention methods such as DSA.
Co-Authors: @AdrianLancucki, @CStanKonrad, @PontiEdoardo
Links in the comments 👇
Over the past few weeks, we have been working on the post-training RL for sharpening model's alignment with users' preferences in conjunction with model's capabilities and intelligence.
It has been an amazing learning journey about the recipe, product, user signals, style, response quality and various inexplicable things which makes a conversation better.
We feel 4.1 is a significant improvement in model's conversational intelligence and other aspect of interfacing with humans. Enjoy Grok 4.1, give us your feedback, and stay tuned for the next upgrades.
Introducing Grok 4.1, a frontier model that sets a new standard for conversational intelligence, emotional understanding, and real-world helpfulness.
Grok 4.1 is available for free on https://t.co/AnXpIEOPEb, https://t.co/53pltyq3a4 and our mobile apps.
https://t.co/Cdmv5CqSrb
If you have worked on dev-tooling and want to build the best tooling to 2X the productivity of every engineer at xAI,
DM me with what you're good at; we'll get you through the pipeline and an offer in <2 days.
MathArena Update: Claims about Grok 4 Fast seem to check out, it matches the performance of Grok 4 but is much faster and 20-50x cheaper. Good release!
This holds across final-answer competitions, Apex problems, and Project Euler. 🧵
Our new Grok 4 Fast model jumps through links at lightning speed, ingests media, and synthesizes findings so you don’t have to. Try it out in the Grok app or on https://t.co/Sf6Y9c0Z8v now.
The Grok-4-fast journey has been incredible—kicking off right after the Grok 4 launch in July. None of it happens without the absolute GOAT @s_tworkowski our incredibly talented teammates @LiTianleli@mycharmspace , and the unwavering backing from @Yuhu_ai_ . This kind of opportunity is impossible anywhere else and i'm deeply grateful.
Hoping Grok-4-fast is lighting up your world like it has mine: scouting the best eats, catching up on sports scores, even drafting emails to my doctor. We're iterating fast across the board—share your stories and feedback! And if you're fired up to pack max intelligence density, come build with us at xAI. 🚀
https://t.co/hIrCX9I8U9
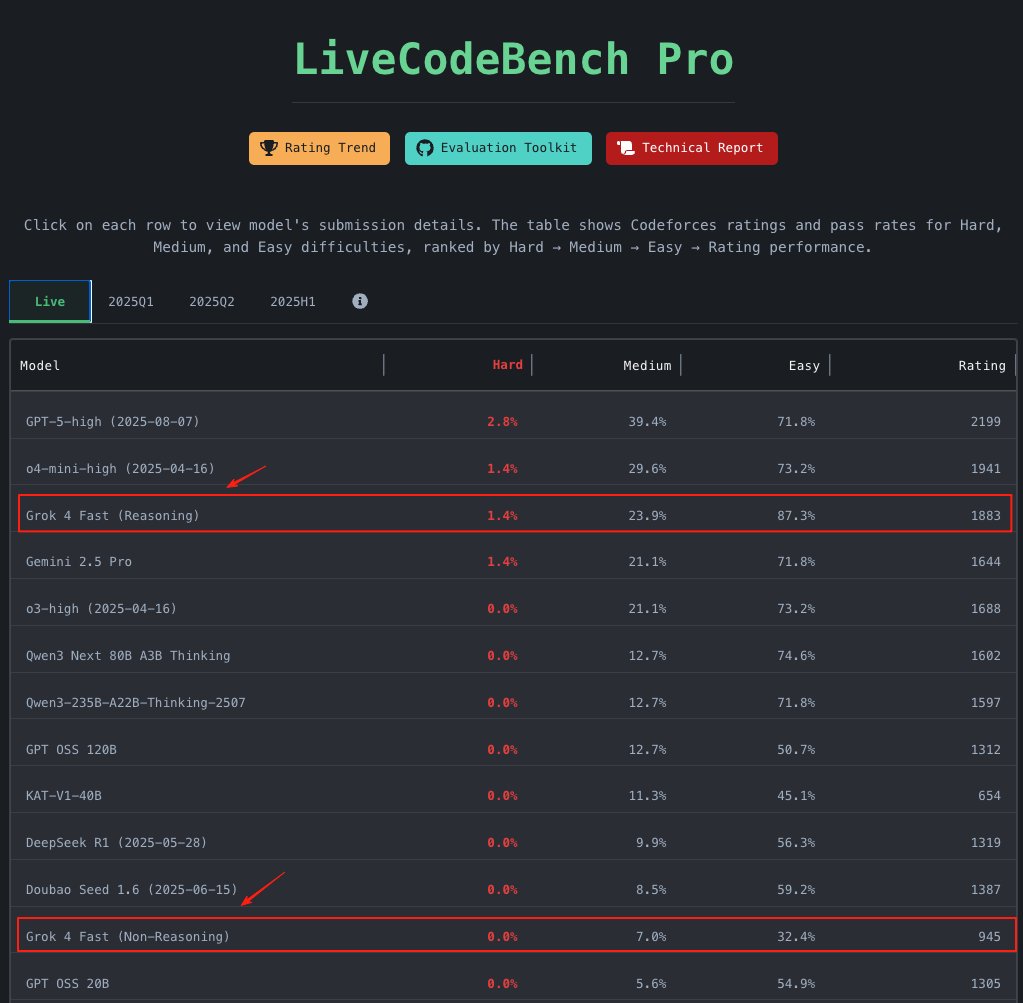
xAI just released Grok 4 Fast, a powerful model for competitive programming. Through our collaboration with xAI, we tested this amazing model on LiveCodeBench Pro. We found that Grok-4-Fast can compete with o4-mini, slightly outperform Gemini 2.5 Pro, and even solved a hard-level problem in the 2025 Q2 set!
Grok-4-Fast-Non-Reasoning has become the strongest non-reasoning model, potentially rivaling gpt-oss-20b (which is a reasoning model).
We are excited to see more powerful models achieving new breakthroughs on LiveCodeBench Pro, and we thank @xai for their support.