4K. That's the max depth you can hide text to and embedding models can still retrieve it. Beyond that, it's gone. Using jina-embeddings-v3, we reproduced the new Needle-in-a-Haystack from recent NoLiMA paper - by removing literal matches between queries and the relevant information (the needle) hidden in the haystack. We ask ourselves:
- How do embedding models perform retrieval across long-context?
- Can query expansion mitigate this performance gap?
Elasticsearch Open Inference API now supports @JinaAI_! Developers can now build search and RAG applications using the latest Jina AI embedding and reranking models without additional integration or costs. Learn more: https://t.co/MdFwzlCWdo
For every model we release, there are 3 ways of using it at scale: Jina API, CSP (e.g. SageMaker), self-hosted K8s. Here we evaluate latency, throughput, neighborhood problem, cost/token across three options to help you decide which one best suits you.👇https://t.co/wbdUTWZ1Mv
My colleague @saahil wrote a detailed review of model deployment options, api vs cloud providers vs self-hosting, full of numbers and insights for serious developers:
Jina-CLIP-v2: a 0.9B multilingual multimodal embedding model that supports 89 languages, 512x512 image resolution, 8192 token-length, and Matryoshka representations down to 64-dim for both images and text. https://t.co/26xLxLKvBl With of course strong performance on retrieval & classification tasks. Like Jina-CLIP v1, the text encoder of Jina-CLIP v2 can function as a standalone dense retriever, giving performance comparable to jina-embeddings-v3, which is currently the best multilingual embedding model under 1B parameters.
At #EMNLP2024 Miami next week? Join us on November 14, 2024, from 10:30 AM to 12:00 PM (Miami Time) for a BoF session on Embeddings, Rerankers, and Small LMs for better search. This 1.5-hour in-person session will bring together researchers in embeddings, rerankers & information retrieval; offering an excellent opportunity to explore recent advances in search foundation models, share your work with a specialized audience, and discuss emerging trends in search models in 2024. All EMNLP on-site participants are welcome to attend. Topics of interest:
- Multimodal, multilingual, cross-lingual, and cross-modal embeddings and rerankers
- Late-interaction models (e.g., ColBERT, ColPali) and late chunking
- Long-context embedding models
- Instruction-tuning for embedding and reranker models
- LLM-based embedding and reranker models
- Small language models for document reading
- Efficient and lightweight embedding architectures, attention mechanisms
- Zero/few-shot retrieval and adaptation methods
- Contrastive learning approaches for retriever
- Matryoshka representation learning, embedding compression and quantization
- Hybrid sparse-dense retrieval systems
- Task-LoRA, domain adaptation, OOD, fine-tuning for embedding models
- MTEB, LongMTEB, RAG evaluation metrics and benchmarks
- Embedding models for code and structured data
- Privacy-preserving embedding techniques
curl https://t.co/0iNSUvqigB This is our Meta-Prompt. It allows LLMs to understand our Reader, Embeddings, Reranker, and Classifier APIs for improved codegen. Using the meta-prompt is straightforward. Just copy the prompt into your preferred LLM interface like ChatGPT, Claude, or whatever works for you, add your instructions, and you're set. In this example, we copied the entire prompt into Anthropic Claude and asked it to grab every sentence from Hacker News front page and visualize them using UMAP with matplotlib. This task is nontrivial as it combines multiple APIs from our Search Foundation, like Reader and Embedding where Claude may not have knowledge of. So if you asked Claude directly, it probably wouldn't give an optimal answer. But with the meta-prompt, Claude now has good knowledge about our APIs and can generate much better code! We can copy paste the code directly to Google Colab and with minimum modification, the code just works!
Classification is the #1 downstream task for embeddings. It's recently popular for routing queries to LLMs too. We're excited to launch new Classifier API https://t.co/5EJqKQSCmH - supports both zero-shot and few-shot online classification for text & image, powered by our latest jina-embeddings-v3 and jina-clip-v1.
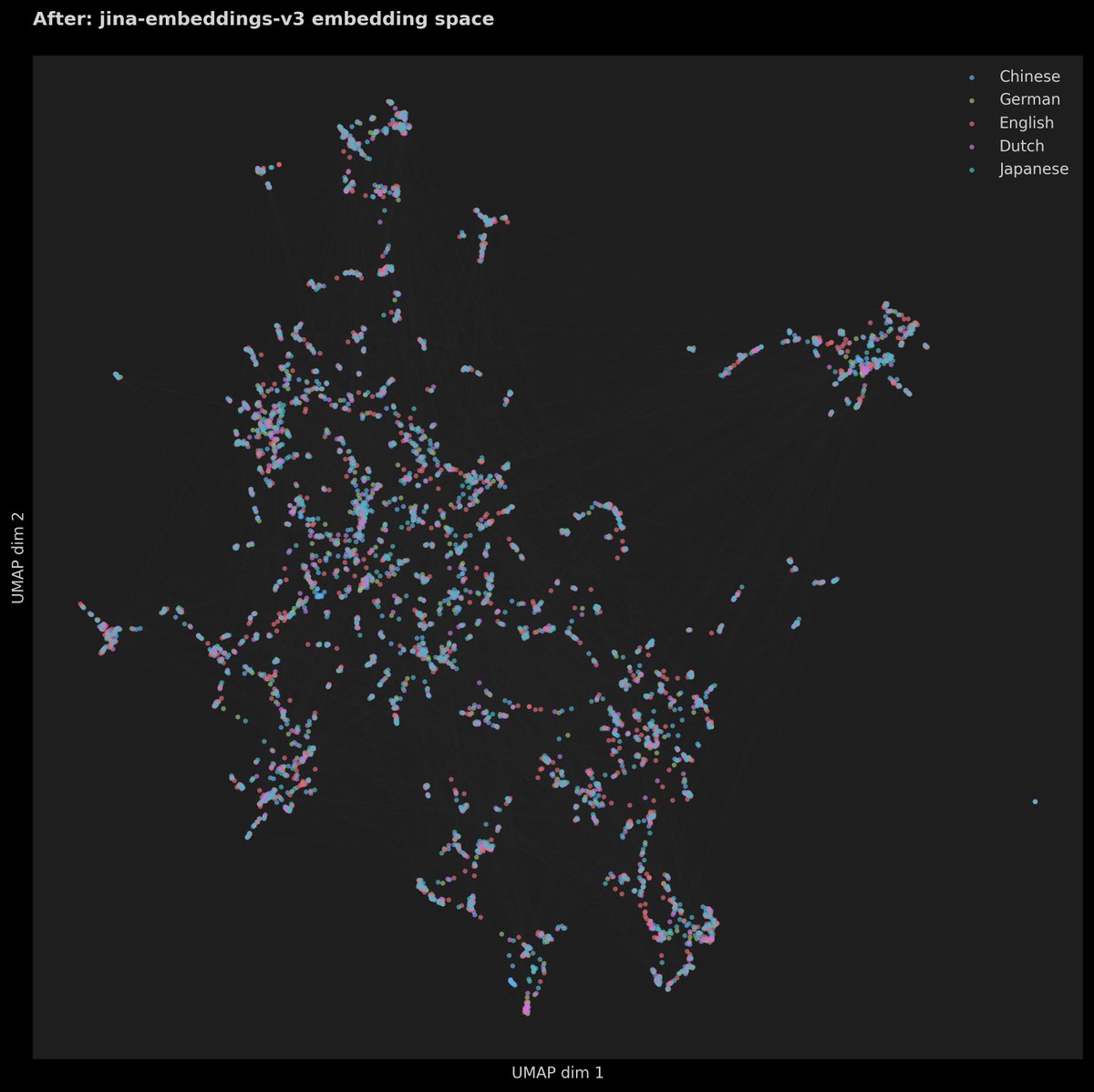
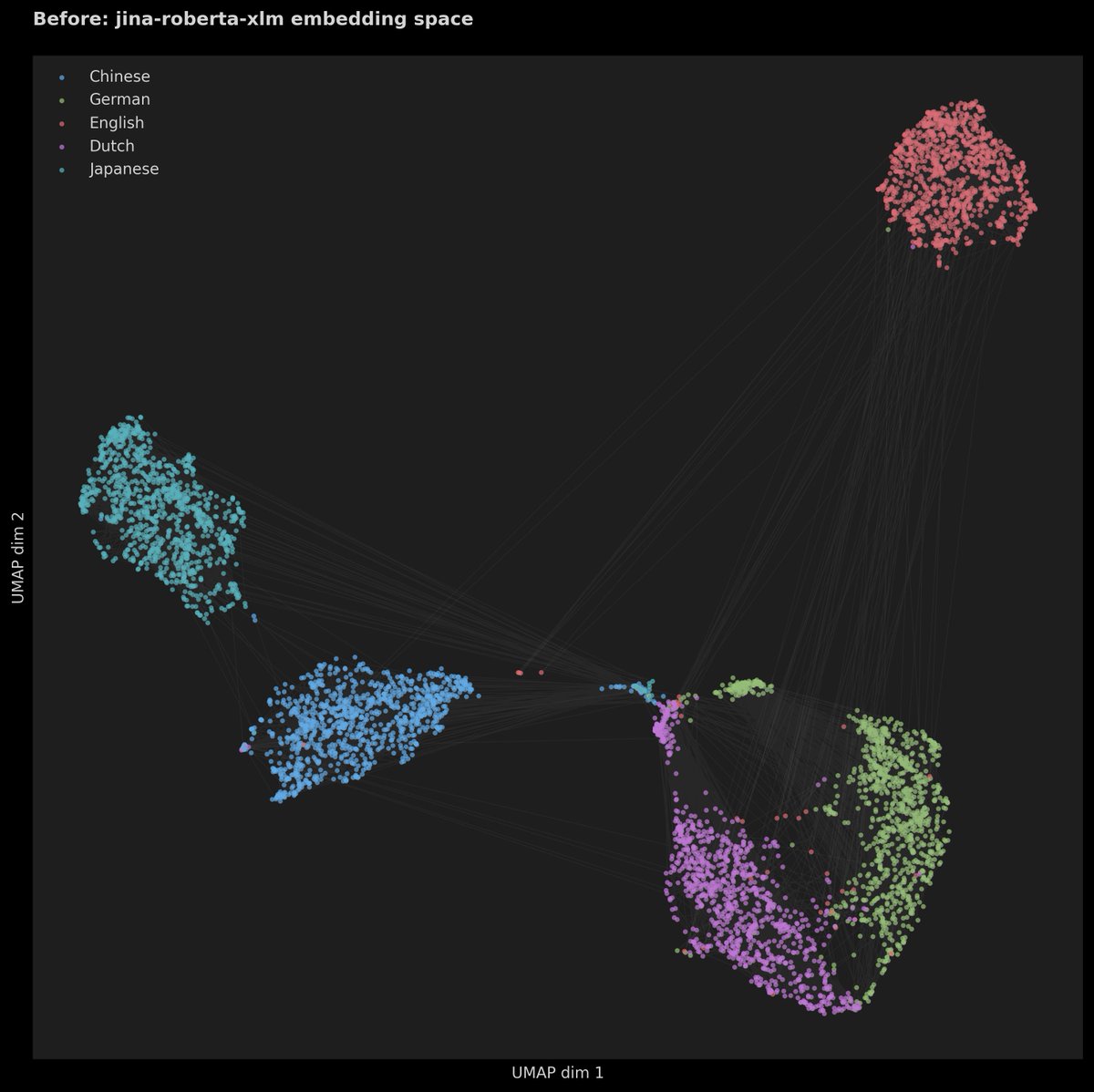
"It's a multilingual embedding model"—okay, but what's that mean? Does it mean you can search German docs with a German query, French docs with a French one, all within the same model? Or can you also search French docs using Japanese queries? A lot of these multilingual models are pretty vague about this: is it just about handling multiple languages separately, or can it do true cross-lingual retrieval? In fact, most models can only manage the former because of the 'language gap'—where similar phrases in different languages don’t align as closely as they should. This makes them less useful for cross-lingual search, which would be much more valuable for global businesses.
While training jina-embeddings-v3, we realized that bridging the language gap isn't straightforward. The two figures below illustrate this. We pre-trained jina-roberta-xlm (the backbone of v3) to see how well it could learn cross-language equivalencies through masked language pre-training. We used UMAP to plot 2D sentence representations for a set of English sentences and their translations into German, Dutch, Simplified Chinese, and Japanese. And it's bad. Comparing this with the final v3 model, it’s clear that the language gap has been significantly reduced. The embeddings in v3 show minimal language-specific clustering, and semantically similar texts produce close embeddings, no matter the language.
We extended our priprint about late chunking, a novel method to make embeddings of chunks context-aware. We added:
- Algorithm for long documents
- Training method to make late chunking more effective
- Comparison to Anthropic's contextual embedding
https://t.co/bqIH3zAxdI
jina-embeddings-v3, reader-lm-0.5b, and reader-lm-1.5b models are now available on AWS SageMaker and Azure Marketplace. Deploy these frontier models within your company’s cloud infrastructure to maintain compliance and full data ownership. Learn more at the link below:
AWS
v3: https://t.co/pDsk5GWl4Q
reader-lm-1.5b: https://t.co/7rAj0muNBJ
reader-lm-0.5b: https://t.co/nWT6obK168
Azure:
v3: https://t.co/WqLOUmZaFf
reader-lm-1.5b: https://t.co/hfvcOj03AR
reader-lm-0.5b:
https://t.co/6161A0Fd2k
We will use the latest multilingual text embedding model from @JinaAI_ to encode over 100 million entries of human knowledge and make it easier to reach:
What a day! Today we got
🎉Qwen Party of models (base, code, math,...)
💬 Kyutai Moshi on-device speech-to-speech
📹 CogVideoX image-to-video
🤏 Jina releasing one of the best open embedding models
my personal favourite about jina-embeddings-v3 (beyond fancy features) is, we manually checked the common failures made by different text embedding models, created failure taxonomy, and try to fix them one by one. This involves a lot of painful, manual work:
Optimizing your chunking techniques is one of the top places to improve performance in your RAG pipelines, but what’s the best one?
@JinaAI_ just released a new method called late chunking that takes the same amount of storage space as naive chunking, but solves the problem of lost context similarly to ColBERT.
You can implement it super easily with just a few extra lines in your embedding step!
Blog: https://t.co/ydo4nKXOXr
Notebook: https://t.co/ocXOcKD7k9
Thanks so much to @DanielW966 again for the awesome collaboration 💚
📄 Papers
Late Chunking: https://t.co/Oa2CrDSqtD
ColBERT: https://t.co/FhDf6bTycF
Thanks to @NVIDIAAI for including our 𝕁𝕚𝕟𝕒-𝕣𝕖𝕣𝕒𝕟𝕜𝕖𝕣-𝕧𝟚-𝕞𝕦𝕝𝕥𝕚𝕝𝕚𝕟𝕘𝕦𝕒𝕝 in their recent benchmark on text retrieval for Q&A! It’s great to see more focus on reranker models in this benchmark, as there's still a lot to explore in this area.