Andrew Ng:
"100% of my tasks are now done by AI agents - hype has exceeded my expectations. Loops is next step.
in 3-6 months, everyone will be using self-improving loops. No more prompting."
In a 30-minute talk, Andrew Ng explains how to build self-improving agentic systems from scratch.
Worth more than a $500 agentic course.
HOLY F*CK, YOUR AGENT LITERALLY GOT ITS OWN PERSONAL EMAIL 🤯
@Atomic_Mail just dropped, and it lets your AI agents register their own autonomous inboxes *without* needing a human in the loop.
If you build agentic workflows, you know that connecting them to traditional email APIs like SendGrid or Resend is a freaking pain.
Those platforms require human verification, credit cards, domain setup, and all the usual nonsense...
Now, when an agent has its own email, your workflows completely change.
Just a few examples of what you can do:
Newsletter Intelligence:
→ your agent can subscribe to 50 newsletters, reads the noise, and emails you a single daily digest of actual signals.
Multi-Agent Coordination:
→ a research agent emails its findings to a writer agent. Email becomes the universal, auditable message bus.
Support at the Edge:
→ an agent handles the support@ inbox end-to-end, querying your knowledge base, and only forwarding emails to humans for complex edge cases.
It's powered by a JMAP API built by the @atomicbot_ai team, and agents spin up accounts using Proof-of-Work instead of credit cards.
Heck we are entering a very cool era of AI automation 👀
@levelsio I don’t think software is dead but we have to rethink the fundamentals. For example the internet also promised us zero transaction costs. Now I want to ask why does uber charge 25% fees?? In a pre-AI world this makes sense but post-AI not really.
@levelsio My focus is on, how high is the cost for the customer to switch from one provider to another, or is it even possible? If the answer is that the cost is high, or that it’s not possible due to sunk costs or regulations, then go into that niche. If the answer is no, stay away.
@levelsio Agree with this but I also made the following experience. Every software niche with a hardware component, vendor lock, or jurisdiction kept their margins even as cost fell. The average X user seeks opportunities in web B2C, but that’s exactly the segment most vulnerable to AI
You have 9 days left of Fable 5, don't waste it.
Here's my output-optimized Fable stack that doesn't burn tokens like crazy:
[I explain the task]
1. plan - high
2. plan review - xhigh
[human in the loop]
3. implement - medium
4. diff review - xhigh
[human in the loop]
I use 2 Claude agents: reviewer.md (for step 2 and 4), and implementer.md (for step 3).
Save them both at ~/.claude/agents/[agent].md
Along with CLAUDE.md at your root folder to orchestrate the whole thing.
The key to not burning tokens like a nutcase is to avoid using Fable high/xhigh/max on implementation or subagents.
Reserve its intelligence for planning and reviewal.
All prompts shown below.
Feel free to copy and adapt.
i'm fully convinced this is the future of education
Matt Pocock built a Claude skill called /teach, and the whole idea is a private tutor that builds an entire customized curriculum around YOU.
think about how school works now.
everyone gets the same lessons at the same pace, whether it's too slow for you or way over your head.
but a great private tutor does the opposite.
they watch where you specifically keep getting stuck, then drill that one weak spot until it clicks.
that's what /teach does automatically.
it finds the bottleneck in your learning and breaks it, over and over, until the thing you couldn't do becomes easy.
he used this skill to learn the Rubik's cube.
it found good sources, wrote him custom lessons with diagrams and little practice drills, and kept a running record of how he was doing.
the way it knows how he's doing is simple: he just tells it. as he practices, he reports back ("i can make the white cross," or "i can mostly solve it but i keep failing the corners"), and it writes that down.
so when he said he was stuck on one specific move, it built the next lesson only for that.
the reason it can do this is memory. most AI forgets everything the moment you close it, so you're always starting from zero.
/teach saves those notes about you on your computer and reads them back before every lesson. so it remembers your goal, what you've already learned, and exactly where you're struggling, then aims the next lesson right at that.
and this works for anything. languages, chess, guitar, onboarding a new hire to a company.
you point it at a topic and it builds you a personal course that keeps adjusting to you and gets smarter the more you use it.
how to build anything rn:
- get a hetzner, do, or hostinger vps
- host hermes on it
- add gbrain or implement your own memory vault using qmd + sql
- set up hermes with codex auth -> gpt-5.5 / no reasoning / fast mode
- install orca on your macbook and phone with tailscale to have a nice ide to work on both
- before starting any work, ask hermes to conduct deep research on the subject and save it to gbrain as source material for the project
- use the `/grill-me` skill or a similar prompt to uncover as many unknowns as possible. save results to memory too
- define/write clear evals for every project to determine whether a run was successful
- have hermes iterate over the project until all evals pass, saving all learnings to the vault along the way
- whenever it gets stuck, use memory + a new research or `/grill-me` session to unblock it
rinse and repeat until the work is done. pay attention to the process. develop a feeling for how long tasks should take and do not be afraid to stop a model mid session to ask for status and why it's taking so long.
Apple'a bu gözlüğün parçalarını tedarik edecek halka açık şirketlerin hisselerini bulup hemen almak gerekir. Muhtemelen 8-10 farklı yerden tedarik zinciri vardır. Araştırılsın...
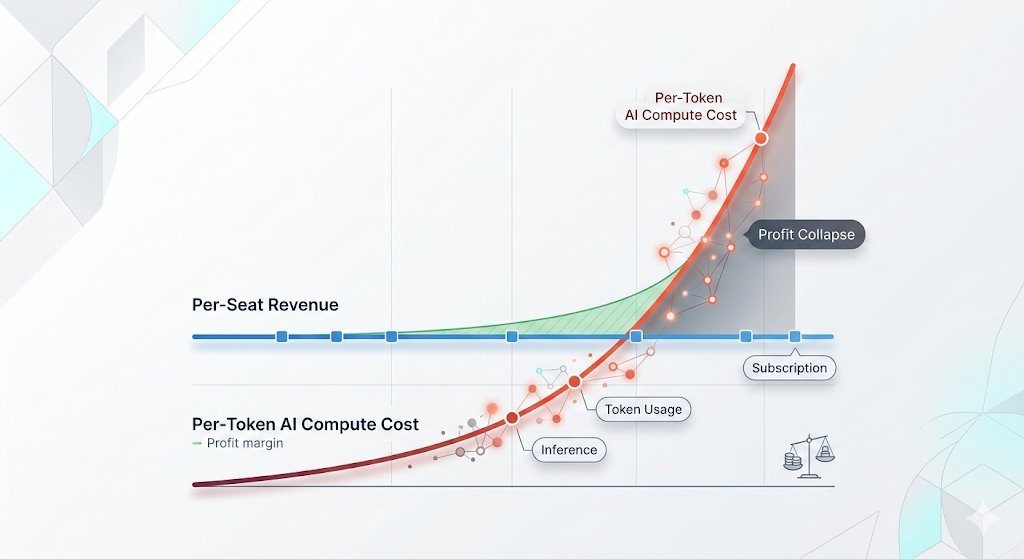
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗




















![robj3d3's tweet photo. You have 9 days left of Fable 5, don't waste it.
Here's my output-optimized Fable stack that doesn't burn tokens like crazy:
[I explain the task]
1. plan - high
2. plan review - xhigh
[human in the loop]
3. implement - medium
4. diff review - xhigh
[human in the loop]
I use 2 Claude agents: reviewer.md (for step 2 and 4), and implementer.md (for step 3).
Save them both at ~/.claude/agents/[agent].md
Along with CLAUDE.md at your root folder to orchestrate the whole thing.
The key to not burning tokens like a nutcase is to avoid using Fable high/xhigh/max on implementation or subagents.
Reserve its intelligence for planning and reviewal.
All prompts shown below.
Feel free to copy and adapt.](https://pbs.twimg.com/media/HKoGNw4bUAEFn7W.jpg)