before joining @baseten i spent a weekend vibe coding, post-training an open source model
it was one of those moments where the future stopped feeling abstract
every serious tech company is going to have some weird little model factory inside it. we are building the tools and platform to make that incredibly easy
i remember when notion ai first launched 3 years ago and it was terrible but now i can’t imagine my workflow without it. change is slow at first and then immediate all of a sudden
Closed Q1 last week. Revenue is accelerating for the 7th straight quarter. AI now counts for 60% of our business. Cash flow positive.
The transition from software to AI is not easy, but can be done! I am proud of our teams!
this is maya speaking with real accents and dialects.
when i first heard it, i loved the tone of the voice. it sounds the way people actually talk. it’s hard to explain until you hear it.
the team absolutely cooked with this. a key step forward for maya’s voice interface.
post-training is becoming way more approachable
as it gets easier and cheaper, the product frontier moves closer to the “inference loop”: how fast teams can test, adapt, evaluate, and ship model behavior in prod
this is a big part of how we think about building product at Baseten. stoked about this release from our training team!
lots of pm debate lately. a pm is anyone that can make a product bet, stand behind it, get a group of people to rally behind it, deliver an exceptional ux, and make the biz some $$$ off of it. or if it’s failing, be bold and humble enough to change direction fast. each one is a craft of its own
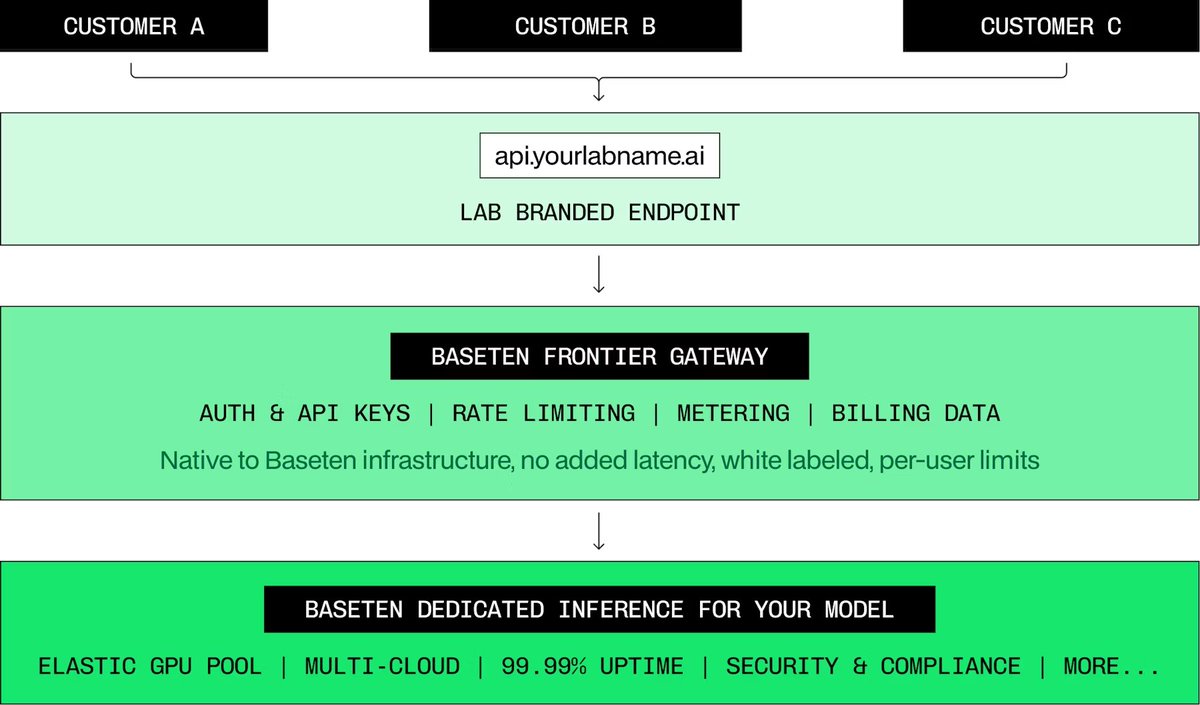
We now have a product specifically created for AI labs and their closed-weight models: we'll take care of not just inference, but auth, rate limits, metering, and billing integrations. We'll take care of providing both shared and dedicated inference, compliance needs, and matching end customers' geo requirements (us, ca, eu, uk, aus, jp, etc).
It's called Baseten Frontier Gateway and is already battle-tested by multiple AI labs, like Poolside and their impressive Laguna M.1 agentic coding model.
dwarkesh thinks we shouldn’t sell chips to china because itll enable them to build a mythos equivalent and thinks selling chips is like selling nukes/enriched uranium. jensen thinks thats lunacy - china has enough compute/energy to do that already. jensen also thinks it’s even more important to standardize the world (including china) on american technology and try to win
Mythos appears to be the first class of models trained at scale on Blackwells. Then will be Vera Rubins. Pre-training isn't saturated. RL works. And there is *so much* computing coming online soon.
Buckle your chin strips. It's going to be fucking wild.
very interesting pattern. one of the harder problems w building agents is keeping persistent state across many agent sessions w/o sacrificing speed/ux.
from exp, markdown/files still seems to be the most effective pattern for speed and accuracy. and distributed file systems are a pain but this idea is super cool. but curious how far pg search can go here tho
Introducing TigerFS - a filesystem backed by PostgreSQL, and a filesystem interface to PostgreSQL.
Idea is simple: Agents don't need fancy APIs or SDKs, they love the file system. ls, cat, find, grep. Pipelined UNIX tools. So let’s make files transactional and concurrent by backing them with a real database.
There are two ways to use it:
File-first: Write markdown, organize into directories. Writes are atomic, everything is auto-versioned. Any tool that works with files -- Claude Code, Cursor, grep, emacs -- just works. Multi-agent task coordination is just mv'ing files between todo/doing/done directories.
Data-first: Mount any Postgres database and explore it with Unix tools. For large databases, chain filters into paths that push down to SQL: .by/customer_id/123/.order/created_at/.last/10/.export/json. Bulk import/export, no SQL needed, and ships with Claude Code skills.
Every file is a real PostgreSQL row. Multiple agents and humans read and write concurrently with full ACID guarantees. The filesystem /is/ the API.
Mounts via FUSE on Linux and NFS on macOS, no extra dependencies. Point it at an existing Postgres database, or spin up a free one on Tiger Cloud or Ghost.
I built this mostly for agent workflows, but curious what else people would use it for. It's early but the core is solid. Feedback welcome.
https://t.co/IPhieopOSP
still a long way to go but open weight models, great/easy post training will power a good chunk of future ai. not as easy/straightforward today - big problem and a growing market
Scoop from me: Nvidia will spend a total of $26 billion over the next five years building the world's best open source models. America is back in the open source AI race! https://t.co/MaaFnOPt0N
@signulll 100%. The Outsiders teaches and shows that great CEOs are great capital allocators, not prophets. Zuck’s real advantage probably is the ability to deploy billions the moment a new wave appears. Insta, WhatsApp, Reels, Oculus, now AI. His VR stuff was weird tho
Great piece by @jasoncui and @JenniferHli. We've been thinking and building around this problem at dbt for the last few months and more to come on this soon. Especially the point about automated context construction hitting a ceiling. This is an org knowledge problem, and no amount of crawling Slack or GDrive gets you there.
I think we'll see great enterprise adoption once we make it easy to maintain and govern the context layer. The best data teams/customers I've seen doing this today are building a living system with three components:
An ontology that evolves - business entities, SL/metrics, relationships, biz app context, tribal NL knowledge that agents can consume and update over time. A living knowledge layer that grows with the business.
Tracing and reasoning - full observability into what context an agent consumed, how it reasoned over it, and why it chose one data source over another. Show the math. Market needs better UX for Data here than what current tools provide imo.
Governance and curation - the human-in-the-loop surface where data practitioners review, prune, and override context/agent assumptions. This is where tribal knowledge enters the system and where bad context gets caught before it compounds.
Data practitioner roles will evolve to designing and building these systems and operating agent fleets on top of this context. The most ai-pilled data teams are already doing this today but with a lot of custom-built tooling and sorcery.
Big fan of notion agents. We've been using this internally at dbt for a few months now. We're slowly moving more and more of our product ops to workflows built on notion agents. Including rigor around PRDs, roadmap tracking/updates, and summarizing signals.
@NotionHQ is one of the best examples of applied AI done right on top of prop data. As this evolves would love to see more tools around context/data curation. Nice work @akothari and @ivanhzhao
At @NotionHQ, we believe every business deserves powerful & beautiful tools.
AI is the most important technology of this era. It shouldn't only belong to companies that have AI teams or can afford forward deployed engineers.
Today we're launching Custom Agents:
— The first multiplayer agents built for business.
— No coding. Minutes to set up. Hosted in the cloud.
— Run autonomously 24/7 with all your business apps.
— Switch between the best LLMs (usually the same day they're released).
— One person builds it, the whole company benefits.
Rolling out for Business and Enterprise customers today. The AI era should leave no one behind 👌