GitHub was hacked via a malicious VS Code extension that compromised an employee’s laptop.
This is *exactly* why we built 'Aikido Device Protection'
https://t.co/kfS8HRkZOV
It protects devices from installing malicious IDE extensions, browser extensions, and packages.
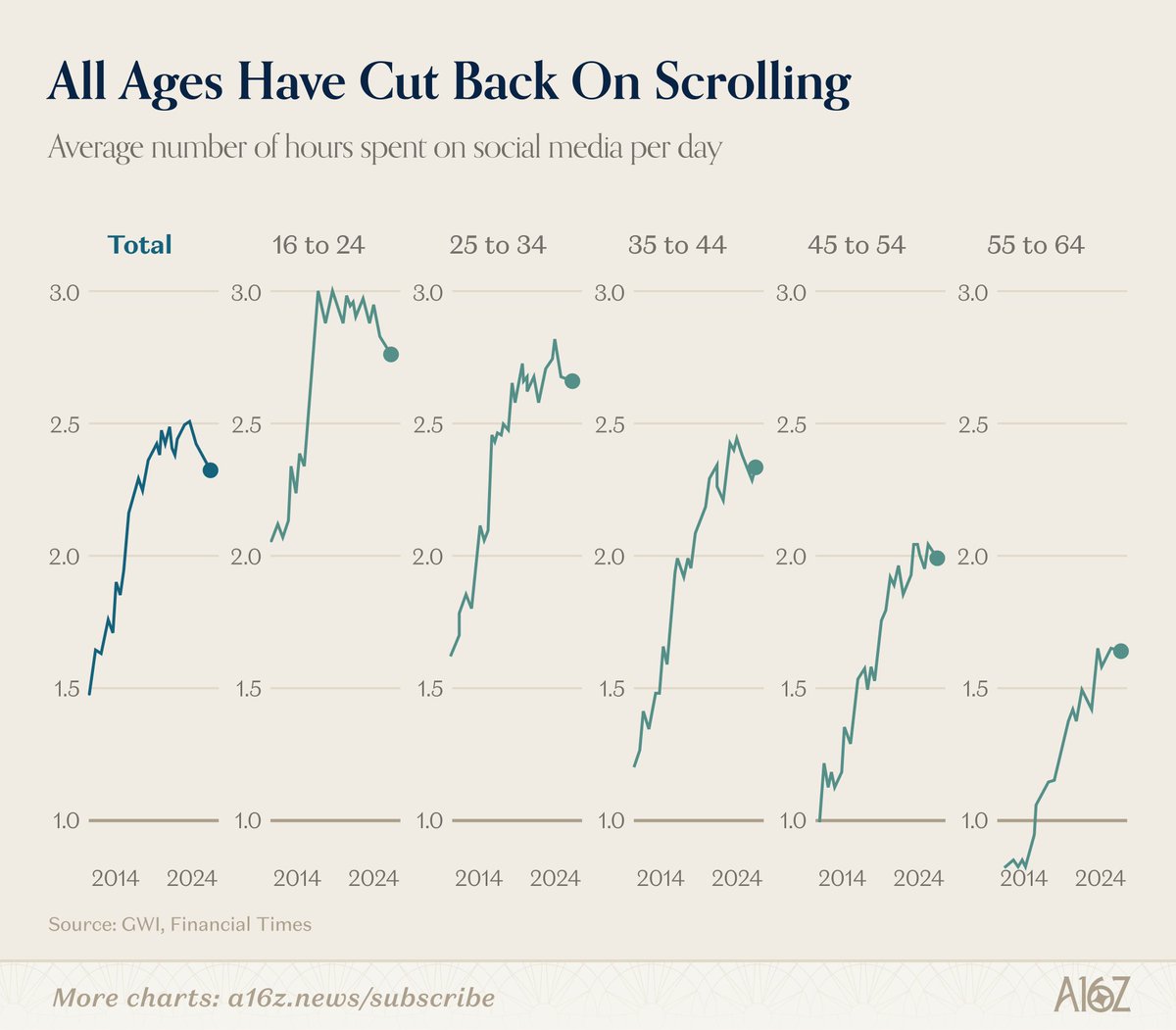
You check your Apple Watch in the morning. Sleep score: 62. You decide it's going to be a foggy day. And then it is.
A 2014 Colorado College study suggests the score itself causes the fog.
164 people walked into a lab. Researchers hooked them up to fake EEG equipment and told them the readout would show their REM percentage from the night before. Then they fabricated a number. Half the room was told 28.7%. Half was told 16.2%. The machine wasn't measuring anything.
Participants took four cognitive tests. The Paced Auditory Serial Addition Test, where you add numbers spoken at increasing speed and hold your last sum in working memory while computing the next. And the Controlled Oral Word Association Task, where you generate as many words as you can starting with a single letter under time pressure. Both are gold-standard measures of attention and executive function used in clinical neurology.
The 28.7% group outperformed the 16.2% group on both. Significantly. How rested participants actually felt that morning predicted nothing.
The mechanism is mindset priming an executive resource. When you believe you slept well, you allocate cognitive effort more aggressively. You don't conserve. You don't pre-disengage. Belief about the resource changes how you spend it.
Two control conditions ruled out demand characteristics. Participants weren't trying harder because they thought they should. Real measurable cognitive performance shifted with the number on the readout.
The Apple Watch sleep score. The Oura ring readiness number. The morning ritual of checking either one is taxing the resource you're about to need.
The performance gap from a fabricated REM percentage was larger than the gap from how rested participants actually felt. The number was louder than the night.
@ghostdevoid@tailwiinder yeah i believe the same, and once we have a workflow setup with the local models nobody would force to switch to a diff model it's entirely a personal choice
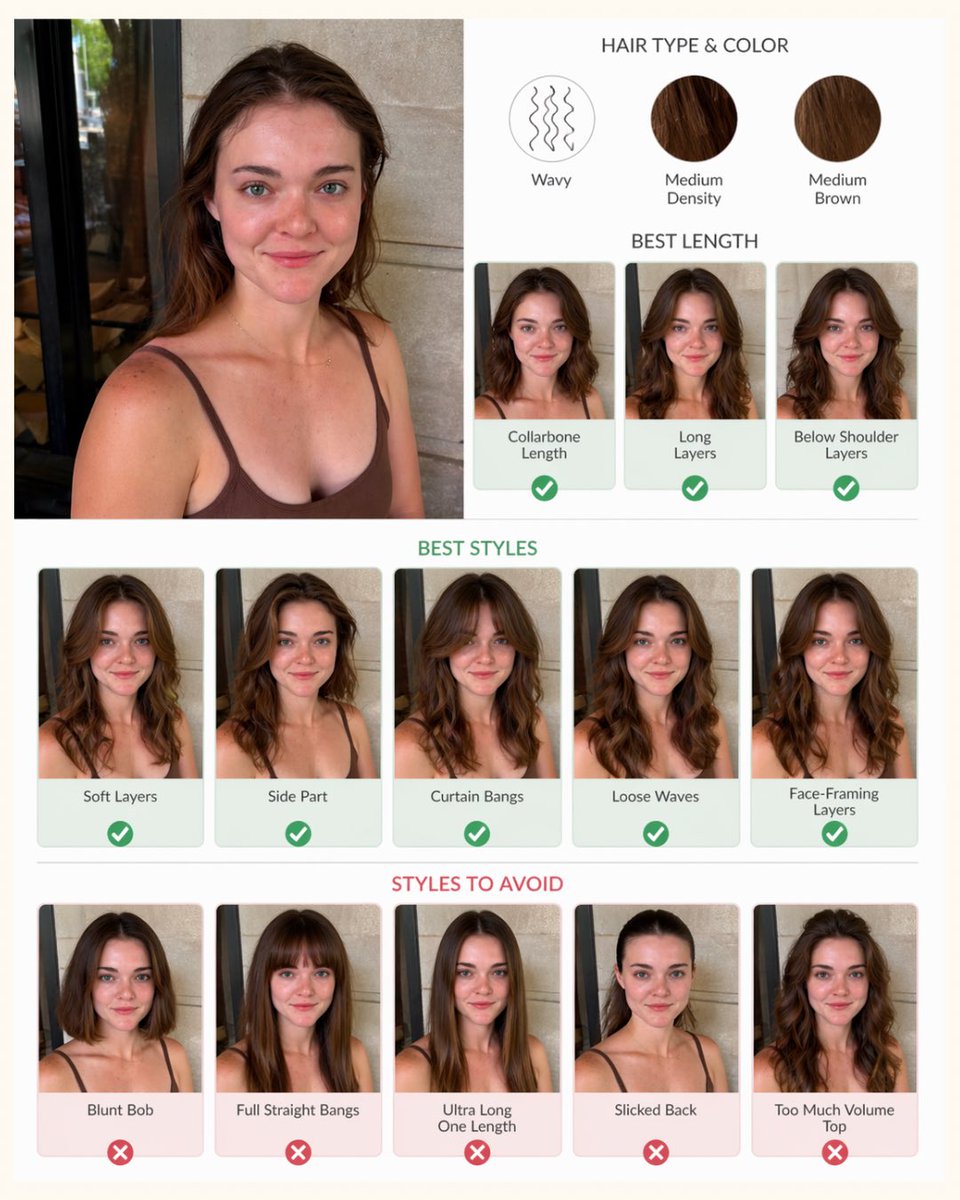
Did a color & hair analysis with ChatGPT Images 2.0! Been wanting to do this for a while.
I have done this in the past with selfies but I think having someone take a pic of you in indirect sunlight gets the best results.
Do you agree with the analysis?
See the prompt below.
GPT 5.5 underperforms Opus 4.7 on SWE-Bench Pro. Couldn't find any reported SWE-Bench scores at all and an internal benchmark is reported instead.
That footnote is trying really hard to bury the lede. GPT 5.5 isn't SOTA for coding.