10-Step LLM Engineering Projects Roadmap
If you want to go from LLM basics to building a production-grade AI system, this is the path:
1. Start with the foundations
Learn how tokenization, embeddings, and positional encoding work. If you skip this, everything else feels like magic instead of engineering.
2. Understand core transformer mechanics
Build attention from scratch. Then move into multi-head attention, transformer blocks, and amini-transformer so the architecture actually clicks.
3. Master inference and decoding
Training a model is one thing. Getting it to generate useful outputs efficiently is another. Studydecoding strategies, objective comparisons, speculative decoding, and KV cache.
4. Learn efficient LLM architectures
Speed and cost matter. Explore long-context methods, FlashAttention, hardware-aware design, and techniques like MQA/GQA/MLA.
5. Go beyond standard transformer design
This is where things get interesting. Dive into MoE, sparse models, state-space models, linearattention, and diffusion-based language model ideas.
6. Understand data and scaling
Great models are built on great data. Study data pipelines, synthetic data, and scaling laws tounderstand what actually improves model performance.
7. Learn post-training and alignment
Raw models are not finished products. Work through SFT, DPO, RLHF/GRPO, reward models,safety filters, and evaluation pipelines.
8. Focus on deployment and optimization
A useful model must be deployable. Learn quantization, serving stacks, evaluation harnesses,monitoring, and telemetry for real-world systems.
9. Build application-layer AI systems
This is where products emerge. Create RAG pipelines, tool-using agents, multimodal systems,and vision-language applications.
10. Don’t ignore safety and interpretability
Production AI requires trust. Study interpretability, red teaming, bias and toxicity analysis, and policy/governance controls.
Anthropic shipped 125 settings for Claude
The official docs cover 40
One developer found the other 85 and his API bill dropped from $340 to $87
- not by using a cheaper model
- not by writing shorter prompts
just by moving one line in a config file to the right place
> memory scoped per project → past clients never bleed into new work
> Extended Thinking on Light by default → 18–25% fewer Opus tokens in week one
> cache_control moved to the right line → the fix that turned a $340 bill into $87
> plugins and MCP servers toggled off when idle → saved 25–40K tokens per session
> per-project model override → Haiku for docs, Sonnet for infra, Opus only where it matters
most Claude users are running a $100/month tool at 30% of its actual capability
Some books from where I took ideas for this article:
- The Wealth of Nations
- Zen and the art of Motorcycle Maintenance.
- Jefferson’s bio & his writings.
- Jeff Bezos’s shareholder letters.
- The Origin of Species.
- Notes from Underground.
- Deep Simplicity.
- Conditioned Reflexes.
- Built from Scratch.
- Fingerprints of the Gods.
- Cicero’s speeches.
- Snowball, Buffett’s bio.
- Poor Charlie’s Almanack.
- Ice Age.
- The Principia.
- Newton’s correspondence.
- Darwin’s autobio.
- Scale.
- Michael Mauboussin’s articles.
- Buffett’s shareholder letters.
- Sam Walton’s autobio.
The 36 BIGGEST startup opportunities right now
1. biggest b2c: solving loneliness. third spaces, community apps, IRL
2. biggest b2b: managed AI employees for businesses
3. biggest overlooked: elder tech. 70 million boomers who want products that make them happier & healthier
4. biggest mobile: action apps that do things, not apps you stare at
5. biggest trades: matching platforms for electricians, plumbers, HVAC. supply shrinking
6. biggest consumer social: small social. group chats as products, no feeds, no ai slop
7. biggest ecommerce: agents that recommend products you'll like, shop, buy for you
8. biggest creator: live shows and unscripted content
9. biggest edtech: AI tutors that adapt through conversation
10. biggest SaaS: pay-per-outcome pricing
11. biggest auto: AI service advisor for dealerships. answers the same 15 questions 24/7
12. biggest talent: training non-technical people to operate agents
13. biggest boredom: curated offline experiences delivered to your door. kits, games, challenges. anti-screen products
14. biggest spiritual: the need for belonging is exploding, new formats of spiritual get togethers
15. biggest wellness: longevity biomarkers you actively manage
16. biggest mobile: action apps that do things, not apps you stare at
17. biggest one to solve ai slop: digital verification that you're a real human. every platform will need this within 2 years
18. biggest infrastructure: agent permissions, security, audit trails
19. biggest media: AI native media companies. build distribution, sell products later.
20. biggest parenting: family ops automation. forms, scheduling, logistics
21. biggest accounting: bookkeeping agents that charge per transaction
22. biggest fashion: brand-owned resale. every brand wants to control their secondary market
23.biggest hobbies: adult learning for joy. pottery, woodworking, drawing.
24. biggest skincare: at-home diagnostics. scan, get a protocol, track progress
25. biggest agriculture: precision farming tools for small farms. enterprise version exists, family farm doesn't
26. biggest pest control: subscription pest prevention instead of reactive treatment. the model flip that lawn care already made
27. biggest regulated: on-device AI. healthcare, legal, finance open up when data stays local
28. biggest gaming: AI characters with real memory and relationships
29. biggest dating: agent-mediated matchmaking
30. biggest fitness: adaptive coaching that rewrites your program daily
31. biggest travel: autonomous trip planning and rebooking
32. biggest food: personalized nutrition based on blood work and gut biome
33. biggest pet: health monitoring. $140B industry, almost no tech
34. biggest defense: AI-native security and compliance tools
35. biggest robotics: physical AI. $30 brains on existing hardware
36. biggest nostalgia: products that feel analog. vinyl, paper, handmade. counter-positioning against AI everything
A mathematician who shared an office with Claude Shannon at Bell Labs gave one lecture in 1986 that explains why some people win Nobel Prizes and other equally smart people spend their whole lives doing forgettable work.
His name was Richard Hamming. He won the Turing Award. He invented error-correcting codes that made modern computing possible. And he spent 30 years at Bell Labs sitting in a cafeteria at lunch watching which scientists became legendary and which ones faded into nothing.
In March 1986, he walked into a Bellcore auditorium in front of 200 researchers and told them exactly what he had seen.
Here's the framework that has been quoted by every serious scientist for the last 40 years.
His opening line landed like a punch. He said most scientists he worked with at Bell Labs were just as smart as the Nobel Prize winners. Just as hardworking. Just as credentialed. And yet at the end of a 40-year career, one group had changed entire fields and the other group was forgotten by the time they retired.
He wanted to know what the difference actually was. And he said it wasn't luck. It wasn't IQ. It was a specific set of habits that almost nobody is willing to follow.
The first habit was the one that hurts the most to hear. He said most scientists deliberately avoid the most important problem in their field because the odds of failure are too high. They pick a safe adjacent problem, solve it cleanly, publish it, and move on. And because they never swing at the hard problem, they never hit it. He said if you do not work on an important problem, it is unlikely you will do important work. That is not a motivational line. That is a logical one.
The second habit was about doors. Literal doors. He noticed that the scientists at Bell Labs who kept their office doors closed got more done in the short term because they had no interruptions. But the scientists who kept their doors open got more done over a career. The open-door scientists were interrupted constantly. They also absorbed every new idea passing through the hallway. Ten years in, they were working on problems the closed-door scientists did not even know existed.
The third habit was inversion. When Bell Labs refused to give him the team of programmers he wanted, Hamming sat with the rejection for weeks. Then he flipped the question. Instead of asking for programmers to write the programs, he asked why machines could not write the programs themselves. That single inversion pushed him into the frontier of computer science. He said the pattern repeats everywhere. What looks like a defect, if you flip it correctly, becomes the exact thing that pushes you ahead of everyone else.
The fourth habit was the one that hit me the hardest. He said knowledge and productivity compound like interest. Someone who works 10 percent harder than you does not produce 10 percent more over a career. They produce twice as much. The gap doesn't add. It multiplies. And it compounds silently for years before anyone notices.
He finished the lecture with a line I have never been able to shake.
He said Pasteur's famous quote is right. Luck favors the prepared mind. But he meant it literally. You don't hope for luck. You engineer the conditions where luck can land on you. Open doors. Important problems. Inverted questions. Compounded hours. Those are not traits. Those are choices you make every single day.
The transcript has been sitting on the University of Virginia's computer science website for almost 30 years. The video is free on YouTube. Stripe Press reprinted the full lectures as a book in 2020 and Bret Victor wrote the foreword.
Hamming died in 1998. He gave his final lecture a few weeks before. He was 82.
The lecture that explains why some careers become legendary and others disappear is still free. Most people who could benefit from it will never open it.
If you want a rare life, you have to be delusional. Doubt can enter your mind, and it can sound reasonable, but if you entertain it too much it will slowly drag you down into stagnation. I'd rather reap the lesson from massive failure than do nothing because it's not "realistic."
Here is my counterpoint after 3 months of releasing open source used by tens of thousands of agentic engineers per day.
Thin harness, fat skills:
https://t.co/K2Sx8Cb4tz
Big tip: as https://t.co/9Q0fhz2jio gets longer than 200 lines, put in *triggers* so Claude knows if you touch evals with this *_generator.* filename splat, load docs/EVALS.md.
You can test the trigger prompt in another Claude window. Works well, saves tokens!
10 must-read books and surveys about AI and Machine Learning
▪️ Machine Learning Systems by Vijay Janapa Reddi
▪️ Understanding Deep Learning by Simon J.D. Prince
▪️ Interpretable Machine Learning by Christoph Molnar
▪️ Foundations of LLMs
▪️ A Survey on Post-training of LLMs
▪️ A Survey of Generative Categories and Techniques in Multimodal Generative Models
▪️ Context Engineering 2.0: The Context of Context Engineering
▪️ Agentic Large Language Models, a survey
▪️ Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
▪️ Mathematical Foundations of Geometric Deep Learning
Save the list and check this out for the links: https://t.co/kMOFY9dTBx
I really like to read engineering blogs from companies whose product I admire/use the most in my day to day life, its the best way to understand how the engineering teams at the top tech companies function and how they build scalable systems.
It also helps me build a strong intuition for system design interviews as I get to know each and every pros and cons of components I will be using.
I would really advice everyone to invest at least 30 to 45 minutes of their day to read a new blog post everyday and note down what significantly new they learned today
### 1. Netflix (@netflix)
1.1. Microservices
- Netflix Conductor : https://t.co/xbxAqP54jt
- The netflix api re-architecture : https://t.co/MVQVTQSM7b
- Load shedding : https://t.co/B41J9JgMwN
- Making api more resilient : https://t.co/B41J9JgMwN
1.2. Streaming
- Content Popularity for Open connect : https://t.co/Xa3Zduzxnr
- Video encoding at scale : https://t.co/3H8FkdN8uV
- Data compression for large scale streaming : https://t.co/3Ze2bF7ldK
1.3. Architecture
- Creating scalable offers platform : https://t.co/vuL1HqPrjW
1.4. Infra related
- Extracting image metadata at scale : https://t.co/9WcSc1FSyG
### 2. Uber (@Uber)
2.1. Architecture :
- Service oriented : https://t.co/v2Yft9NuR2
- Push Platform : https://t.co/K5yrJZczZa
- Multi tenancy architecture : https://t.co/yPcLDsuqhg
2.2. API:
> Uber's api gateway : https://t.co/kvDM5cToKu
### 3. Airbnb (@airbnb)
- 3.1. Avoiding double payments in distributed payments system : https://t.co/FoVQKcIIcw
- 3.2. Knowledge Access and retrieval at scale : https://t.co/bV1CUgeylG
- 3.3. Promotion and communication platform : https://t.co/nmhbup5dWH
### 4. Hotstar (@HotstarReality)
- 4.1. Re-Architecting apps for scale : https://t.co/DWgsKsXB4E
- 4.2. Pubsub for 50M(scale) : https://t.co/A97Axxhd8R
### 5. https://t.co/dGYjs1PDpP (@incident_io)
- Debugging deadlocks in postgres : https://t.co/tnPOrypPZZ
- Choosing right postgres indexes : https://t.co/KNBTDO67oQ
- Time, timezones and scheduling : https://t.co/fGcBa4EYt0
- data habits help build a data culture : https://t.co/TTjmVPZsO8
### 6. Tailscale (@Tailscale )
- Perfomance : https://t.co/UkwUcpEIKT
- Tailscale GitHub Action v4 : https://t.co/wJpzckD5Lp
- identity provider for scale : https://t.co/CJ0HTwDOlU
- Better auth : https://t.co/jx69e29EYP
- NAT learnings : https://t.co/yaxcgWXbF2
### 7. Discord ()
- How discord resizes 150 million images with go and c++ : https://t.co/sGZ0emKBOO
- How discord indexes trillions of messages : https://t.co/iHJNoo4BW1
### 8. Twitter
- Kafka as storage system : https://t.co/6vetpQ7ipH
- Twitter metricsdb : https://t.co/yWarOUocvs
- Storing and retrieving millions of ad impressions per second at scale : https://t.co/EcGMKt27Ov
- Distributed log : https://t.co/6jhpHotUmY
### 9. Dropbox (@Dropbox)
- Infrastructure : https://t.co/Z8kE78kCCk
- Intelligent DNS based load balancing at Dropbox : https://t.co/poyd2XlClM
- Cross shard transactions at 10 million requests per second : https://t.co/jQElG9sHui
- Improving the performance of full text search : https://t.co/O0khhFdsgP
At Stripe we have a tool called "minions" -- it lets us kick off async agents built right in our dev environment to one-shot bugs, features, and more e2e.
I have team, project, and personal channels dedicated just to working with minions.
I like to think of it as a new type of pair programming -- "pair prompting."
Read more --> https://t.co/0A6vDEOEjL
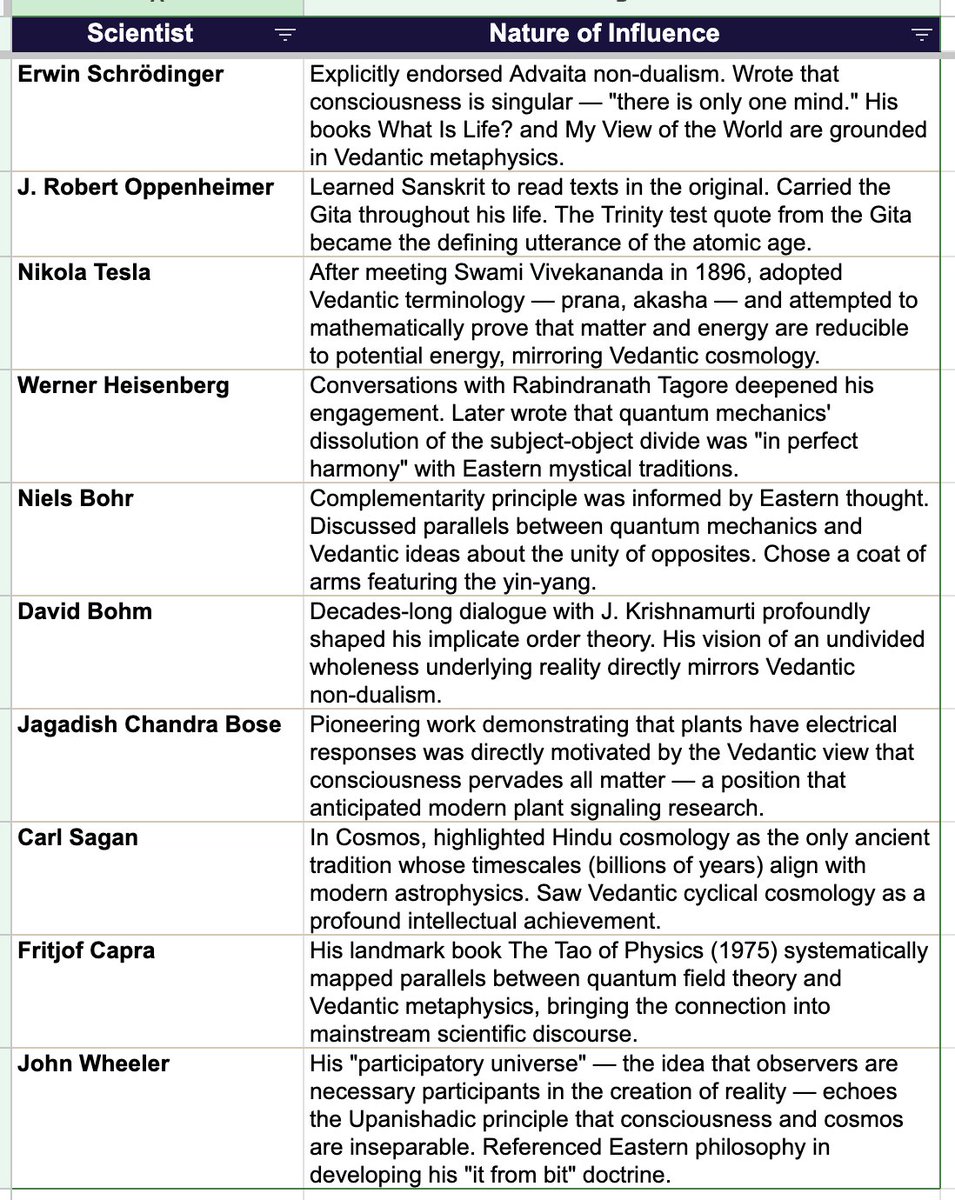
10 of the greatest minds of the last 100+ years ... Were all very deeply influenced by the Upanishads: Sanskrit texts of the late Vedic periods that served as the foundational emergence of the central religious concepts in Hinduism.