With UMA playground, the crazy things Feynman could only ask us to imagine become something you can see. Heat, break, and build at https://t.co/bZFDORa9Mw
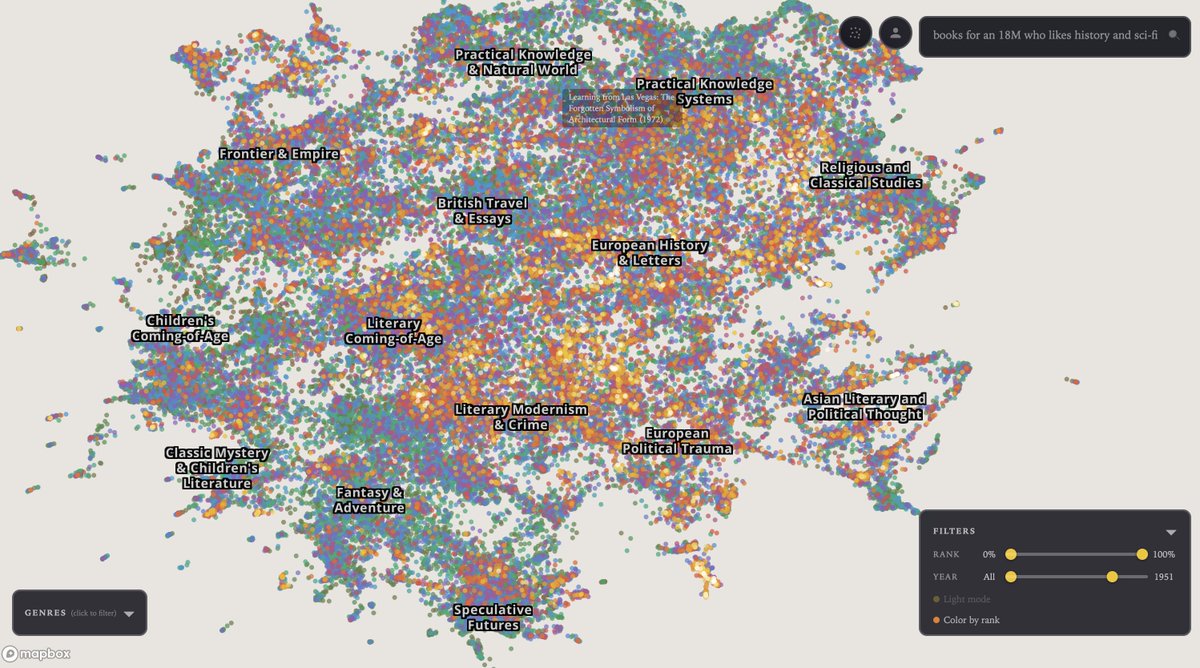
Dataset is a combination of Goodreads and Project Gutenberg. Goodreads dataset I found had too much self help and romance, and actually lacked some classics
Lot of dystopian AI discussion on here as usual. Much is out of my control on that front, but I did use AI to build nice map of (imo) best 80,000 books of all time: https://t.co/sb28LJS58E
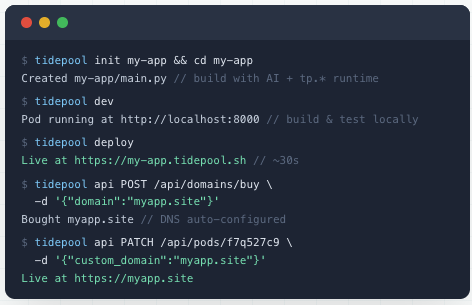
Takeaways: 1) really specific error messages in the API and dev server + a self-documenting API endpoint are essential 2) it's good to give the agent intermediary goals when building more complex sites 3) I think serious, scalable applications will be built this way someday
In the near future I'm going to keep building my own projects on top of it and tweaking it here and there. A lot of this is a learning experience wrt what is needed from infrastructure in the age of semi- and fully-autonomous AI agents
I have long wished that information - from movies, to books, to music, to websites, to really anything - were spatially organized.
The usefulness of Memory Palaces / Method of Loci suggest that this would help us. Perhaps an antidote to infinite scrolling?
@karpathy Yes! I built a humble attempt at solving this issue:
- minimalist dev server for building with Claude Code
- API for deployment, DNS setup, etc
- Stripe + email + database + storage + etc
- Self-documenting API (curl https://t.co/jDZJF6DHFw)
See https://t.co/Tqw7sYMCN3
Zooming in on eg "The Terminator" helps you discover similar but *much less popular* movies.
Helps with discovery of niche films on the long tail of content
This screenshots show interesting islands - a WWE island, a southeast asian cinema continent (bollywood, etc), Scooby-Doo, Peter Pan (+Hook etc)
The individual movies have different genres, cast, etc and yet since they share plot, characters & themes the UMAP puts them together