I've spent a decade building AI systems in telco, logistics, finance, and healthcare. Each time, the issues trace back to the same problem: data.
Training data is the most under-valued, under-coordinated input in the entire AI stack. It's fragmented and challenging to make compliant, and the people who create it often see none of the upside.
Here is our take on the current landscape:
- Compute is centralized and priced in (see: Nvidia $4T and AMD: $255B).
- Models are open-sourcing and the competitive advantage of releasing new architectures is decreasing rapidly (see: OpenAI, Anthropic, xAI: worth $500B+ combined).
- The only frontier left unsolved and unpriced? Data.
This is validated by Meta's recent investment in Scale AI for $14B, leaving a huge gap for IP-cleared training data.
At @storyprotocol, I led research on influence functions, specifically tackling the core problem of data attribution by measuring which datapoints were actually responsible for a model's outputs. It was my first step toward rethinking how we value data.
Earlier this year, @SPChinchali and I started sketching a solution. What if contributors got recurring upside? What if every reuse paid forward? What if data worked like IP? That idea turned into @psdnai.
Working at @StoryProtocol with @WhatTheLJW, a master of operations and strategy + @storysylee, a visionary leader with true outside-the-box thinking, helped shape this vision.
Our initial focus is on physical AI, robotics, and audiovisual information. However, Poseidon is designed to excel in healthcare, biometrics, sensor data, and beyond.
Because of the volume of data we are handling for the world's leading AI companies (yes, in the works), Poseidon would not be possible without @StoryProtocol's IP licensing infrastructure where registration is streamlined and royalties and derivatives are automatically tracked.
If the data can't be scraped, we're building the stack to coordinate and license it.
This mission is personal. It comes from a fundamental tension I've witnessed my entire career, from academic labs to industry. I saw medical AI learn from deeply personal patient data. I built models for telecom, finance, and logistics on the digital footprints and real-world actions of millions. The pattern was always the same: The data was the core asset, but it was never treated or priced as such.
This is the market we're going after. More to come.
AI is moving beyond the browser and into the real world. The bottleneck? Data.
Today we’re announcing a $15M seed round led by @a16zcrypto to build infra that collects, curates, and licenses high-quality data for physical AI.
Incubated by and built on @StoryProtocol.
a lot of the world’s knowledge never makes it into software because it dies somewhere between thought and typing.
google adding voice-first drafting across docs, gmail, and keep is part of a bigger shift.
work software can finally start absorbing the messy context people actually carry: tone, memory, corrections, half-formed ideas, lived expertise.
including from people who know what they mean, but might not write like an office worker.
https://t.co/IZeD1PbSrg
The biggest voice AI markets are also the least measured.
Hundreds of millions of users speak languages where training data is scarce, dialects are underrepresented, and benchmarks do not reflect how people actually speak.
That is the gap we have been working on at @psdnai.
We have been collecting real-world audio data at scale across low-resource languages, noisy environments, and production conditions.
https://t.co/V4R4KW1ZKy is an evaluation framework that makes that work useful to the broader field.
Collecting data is only half the loop. The other half is knowing where the model fails across datasets, speaker groups, acoustic conditions, and error types, then using that signal to collect the data that actually improves it.
SONAR makes that measurable. This is a major step toward voice AI that actually works outside the narrow distribution of clean, high-resource English.
Voice AI has an evaluation problem. Models look strong on public benchmarks, then collapse on real-world audio.
Introducing https://t.co/hNQxLUtonD: a recipe-driven evaluation framework for low-resource languages, real-world audio, and production failure modes.
Details ↓
system-level dictation is a very practical preview of where voice AI is going if it gets the right training data.
less typing, fewer app-specific workflows, and more software that understands intent from natural speech.
voice and physical AI should disappear into daily life this way - useful, broadly accessible, and materially better.
The average person types 36 words a minute on a phone.
But, they can say it four times faster.
Essential Voice turns your speech into clear, ready-to-use writing.
elevenlabs has made it trivially easy to deploy a voice agent across 70+ languages without a dev team.
the interesting signal around this is the speed of adoption. when the tooling gets this accessible, the competitive gap between companies that move and companies that wait compresses really fast.
your support stack is either getting smarter this quarter or falling behind.
Introducing Agent Templates - pre-configured ElevenAgents you can deploy across your business.
The best teams run agents across support, sales, and operations - value compounds with every use case. Choose from 50+ templates with predefined prompts, workflows, and integrations.
experts are finally converging around the fact that the internet is tapped out.
synthetic data as the proposed fix can’t fully offset real-data depletion, since you can’t solve a quality problem by generating more of the thing that’s already degrading.
the only answer is data that was never online to begin with, but out in the real world.
this now becomes a logistics and incentives problem - who shows up, what they capture, and how it gets processed and licensed.
Yeah, you know what they say -- data being the "new oil." And apparently, like oil, it's a finite resource.
(My latest in Forbes) via @forbes https://t.co/qSL436Xrfd
the next wave of AI is physical - robots, voice agents, AVs. but that won’t happen without the right high-quality data, especially once you move into high-stakes deployments.
numo brings that effort to life, starting with bengali, hindi, tamil, and telugu.
to get the volume of data needed, you have to build the supply, task by task and market by market.
AI was trained on the open internet, but the data that matters most lives in the real world.
Introducing early access to Numo, an app built to collect the next generation of AI training data.
Starting with voice data collection in Bengali, Hindi, Tamil, and Telugu.
Details ↴
real-time voice translation just shipped as a product. zoom. teams. mobile. api.
now the cost of serving a customer in their language has collapsed. not “we’ll add spanish support in Q3.” now. the companies that figure out global GTM before their competitors do are going to look very smart in 18 months.
language was always a distribution problem dressed up as a hiring problem. that excuse is gone.
https://t.co/ErnJZel7C8
the new yorker altman piece is long but worth the read.
the part that stuck with me was the structural question underneath all the drama. the most capable AI systems in the world are being built on gulf sovereign capital, embedded in military infra, and racing toward a trillion dollar IPO. every government watching this is now asking the same question: do we want our critical AI infrastructure controlled by entities with competing interests?
that’s why the race for sovereign AI is accelerating. and why who contributes to and controls the data powering these systems really matters.
.@RonanFarrow and @AndrewMarantz interviewed more than a hundred people with firsthand knowledge of how Sam Altman, the head of OpenAI, conducts business. They also obtained closely guarded documents that have not been previously disclosed.
https://t.co/ZKsw6odyKw
this piece on japan’s physical AI push has a signal buried under the surface - labor shortages are forcing physical AI deployment timelines that the data infra isn’t ready for.
once physical AI is load-bearing, the data requirements change completely. you can’t train reliable warehouse or factory systems on generic web data. you need environment-specific, long-tail examples from the exact conditions these robots operate in.
that data doesn’t exist in public datasets. it has to be collected, licensed, and structured from scratch.
https://t.co/JFvlawC2N6
the thumbnail says it all:
all the craft is in curating the perfect dataset.
@Microsoft, please let me introduce you to real-world training data for physical ai.
https://t.co/3eVzxc1lpF
the most valuable thing these labs have is their training data. and right now it all sits in centralized vendors, behind shared infrastructure, with codenames to hide what's being built.
that's a fragile way to protect something this sensitive - one supply chain compromise and your entire moat is revealed.
makes the case for decentralized data pipelines.
https://t.co/1xir5Ekzxg
anthropic didn’t train this model to be good at security. it got there as a side effect of better reasoning and code.
capability jumps like this are downstream of data quality, not just scale. the model got smarter across the board because it trained on better examples.
a model that autonomously chains zero-days across every major OS and browser for under $50 a run is a different threat surface than anything the security industry has ever had to price in before.
most of the major robotics companies are building on NVIDIA’s physical AI stack. including the ones building systems that operate inside human bodies.
CMR Surgical. Medtronic. J&J MedTech.
cool. now someone tell me where the verified, traceable training data comes from. because “we used simulation” is not an answer when the robot is holding a scalpel.
https://t.co/d9gCoWF26U
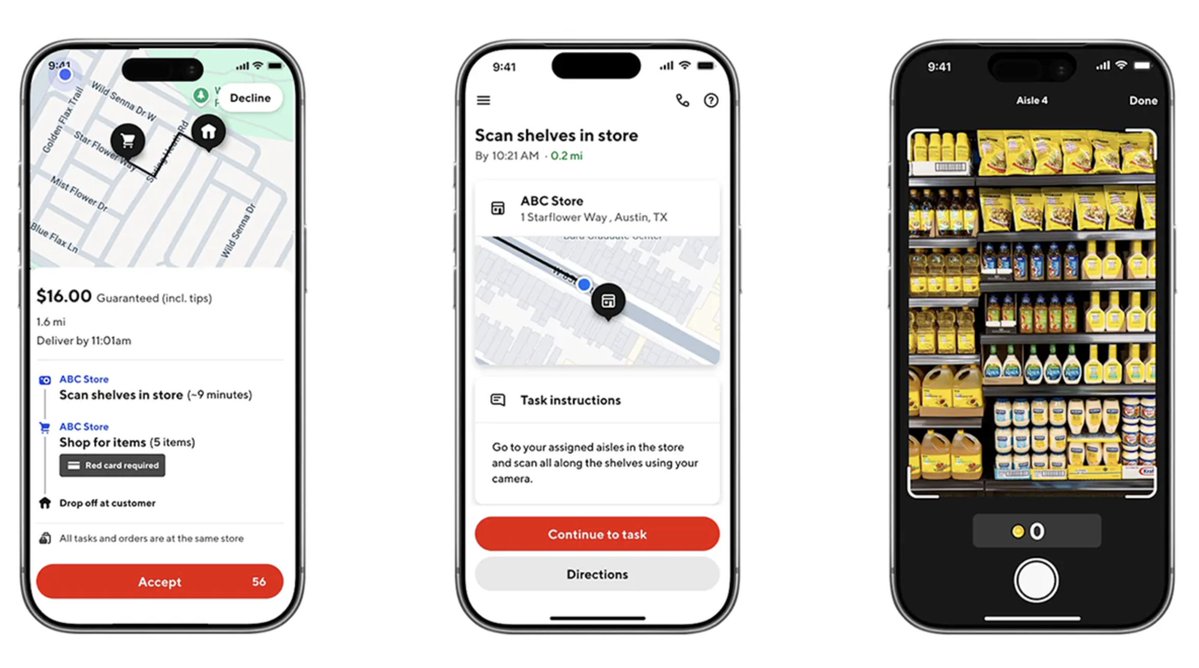
interesting play - doordash is turning 8 million dashers into a real-world data collection network.
i suspect we will see more entrants like this, since semi-distributed networks like doordash lend themselves v nicely to the collection of real-world data.
“take a photo of this dish.” “film the hotel entrance.” sounds mundane, but that’s the data that teaches AI systems how the physical world actually works.
Introducing Dasher Tasks
Dashers can now get paid to do general tasks. We think this will be huge for building the frontier of physical intelligence. Look forward to seeing where this goes!
nvidia + abb say they’ve removed the barriers to physical ai. what they’ve actually done is compress the path from sim to deployment.
the gap just moves from training to production since robots still fail on what the sim failed to capture - edge cases, noise, human behavior, degradation.
not a hardware problem. not a software problem. but a secret third thing (a data problem).
https://t.co/jE4WyJ188T
the keyboard was a massive filter, but voice just obliterated it. if you can talk to your codebase like a teammate, the population of builders expands by 100x.
but here’s the catch: this only democratizes creation if the frontier models actually understand the rest of the world.
right now, they only speak fluent sf tech bro. the next great unlock is low-resource language voice models.