Our new product, KoalaLinks, has finally been released!
It automates creating internal links, related posts, and entity schema markup for all existing pages on your site and will work on autopilot to optimize new pages
Check it out: https://t.co/JQFNCm9sgD
Introducing KoalaLinks, a powerful and easy way to boost engagement and SEO with just a few clicks 🥳
Add internal links, related posts, and entity schema markup to your site on autopilot 🔥
Learn more: https://t.co/WmT3F6gTh2
@yoyaoh@OpenAI Most schema is redundant and/or noise compared to the text content though, so I personally lean towards them stripping it out
And when it comes to real-time data, virtually everyone strips everything except cleaned text before passing to the LLM
@yoyaoh@OpenAI There's lots of published research about cleaning CC data before training. In all the research they stripped out schema. That said, OpenAI does not make public what their current filtering does so it is possible they are incorporating schema these days
@yoyaoh@OpenAI It wasn't at root due to technical reasons because I didn't realize the sitemap protocol didn't allow that
It's a NextJS app and we had an issue preventing the static site generation from working correctly, so another technical reason
@yoyaoh@OpenAI Beyond that, for brands you might want to check what pages in Common Crawl are recommending your competitors and see how you could get mentioned there instead...
Meanwhile people seem focused on schema which is removed from crawl data before training LLMs
@yoyaoh@OpenAI It's strict when parsing sitemaps and if your sitemap is not at the root of your domain then it can ignore the pages inside it, unless those pages are in the same subpath. So we fixed that and made sure the pages had the important content without JS
@yoyaoh@OpenAI It's interesting because I don't have any search features explicitly enabled in ChatGPT (afaik), but it virtually always searches and cites websites for all my ChatGPT queries even with just using 4o
@patrickstox@ahrefs Hmm nope I didn't enable anything it was just default with 4o. Could be an AB test thing
But anyways this gets away from my actual question which was whether or not you guys used "ChatGPT" (as marketed) for your report or the API? Because they are very different things
@patrickstox@ahrefs Well that response doesn't cite *any* sites. So obviously that's not the method you guys used to generate your report. Is that the free version? Maybe it doesn't search the web
@patrickstox@ahrefs I don't know, I just happened to see that chart after I asked you.
But if you are marketing your product as monitoring "ChatGPT" responses your answer should be very clear that it's using *actual* ChatGPT responses and not the API, otherwise it's misleading
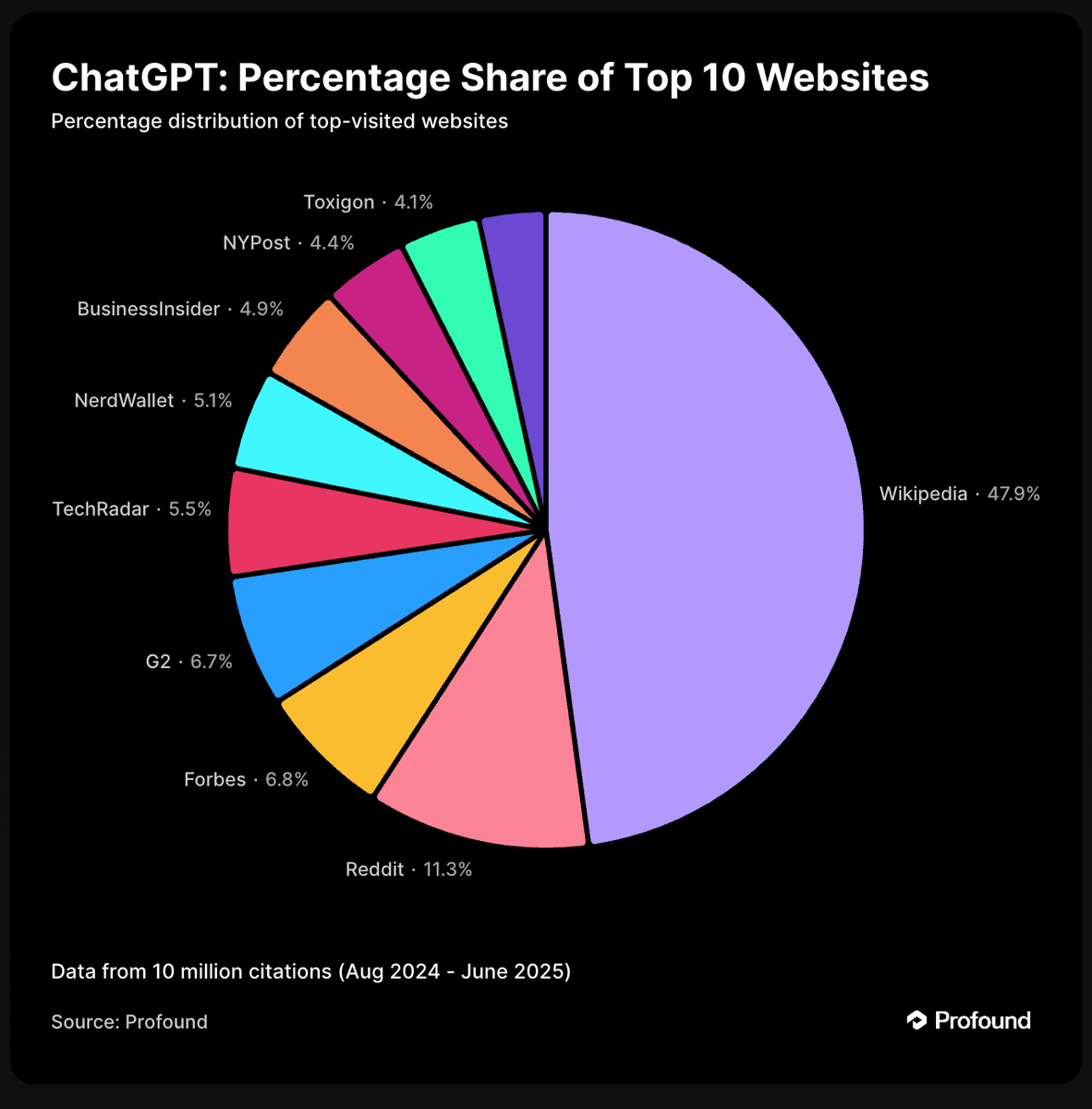
@patrickstox@ahrefs It also cited YouTube which also shows 0 mentions in your data (unless I'm reading it wrong, let me know if I'm mistaken in my interpretation)
@patrickstox@ahrefs As an example, I just entered a random query "is Ahrefs worth it" in ChatGPT (with default settings using 4o) and it cited reddit. I see it use reddit data for almost every query, so that's why I was asking because I suspect your testing did not use their web search features...
@patrickstox@ahrefs You guys have a typo in your charts too, it's just a small mistake. But your data showing no results for reddit is very weird, isn't it? I'm just asking how you are getting the responses and you didn't provide any clarity :)
@patrickstox@ahrefs I'm just asking how the responses were generated. I assumed it was through the API which does not use search data by default. However when you use ChatGPT as a normal user it does use search data. When I see reddit completely missing from the ChatGPT data it makes you think
@patrickstox@ahrefs For ChatGPT was this through the API without Web Search enabled? Maybe I am reading it wrong but it seems to indicate ChatGPT never cited reddit which is very different from what I've observed