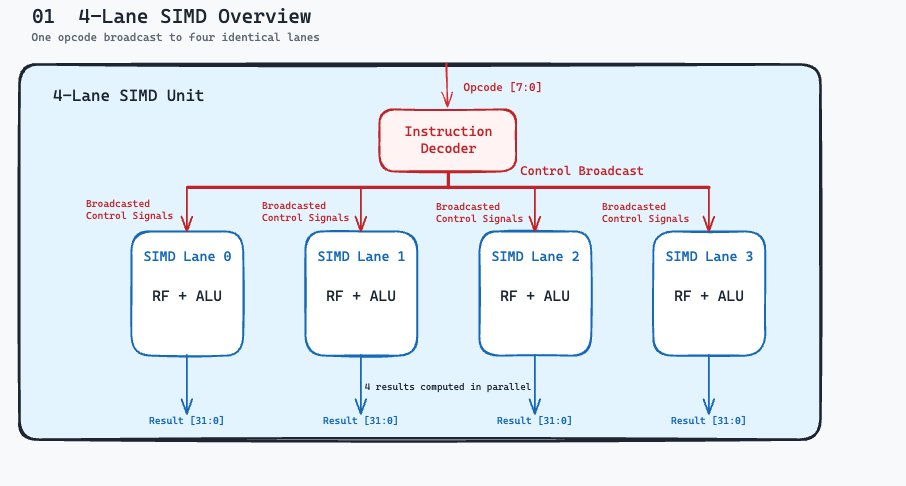
Recently @arjunharinath1 and I started building our own version of Nvidia's Blackwell GPU.
We built the ALUs and a 4-lane SIMD core in Verilog.
Here is a breakdown of how we did it.
@sakshambatraa and I have now implemented Softmax on our toy LPU!
after overhauling the VXM pipeline, we set our sights on implementing the Softmax module in hardware 🧵
@sakshambatraa and I have now implemented Softmax on our toy LPU!
after overhauling the VXM pipeline, we set our sights on implementing the Softmax module in hardware 🧵
another progress update on reinventing Groq's LPU with @sakshambatraa:
we redesigned out vector execution module (VXM) to better support overlap on operations, and introduce compatibility to run self attention!
another progress update on reinventing Groq's LPU with @sakshambatraa:
we redesigned out vector execution module (VXM) to better support overlap on operations, and introduce compatibility to run self attention!
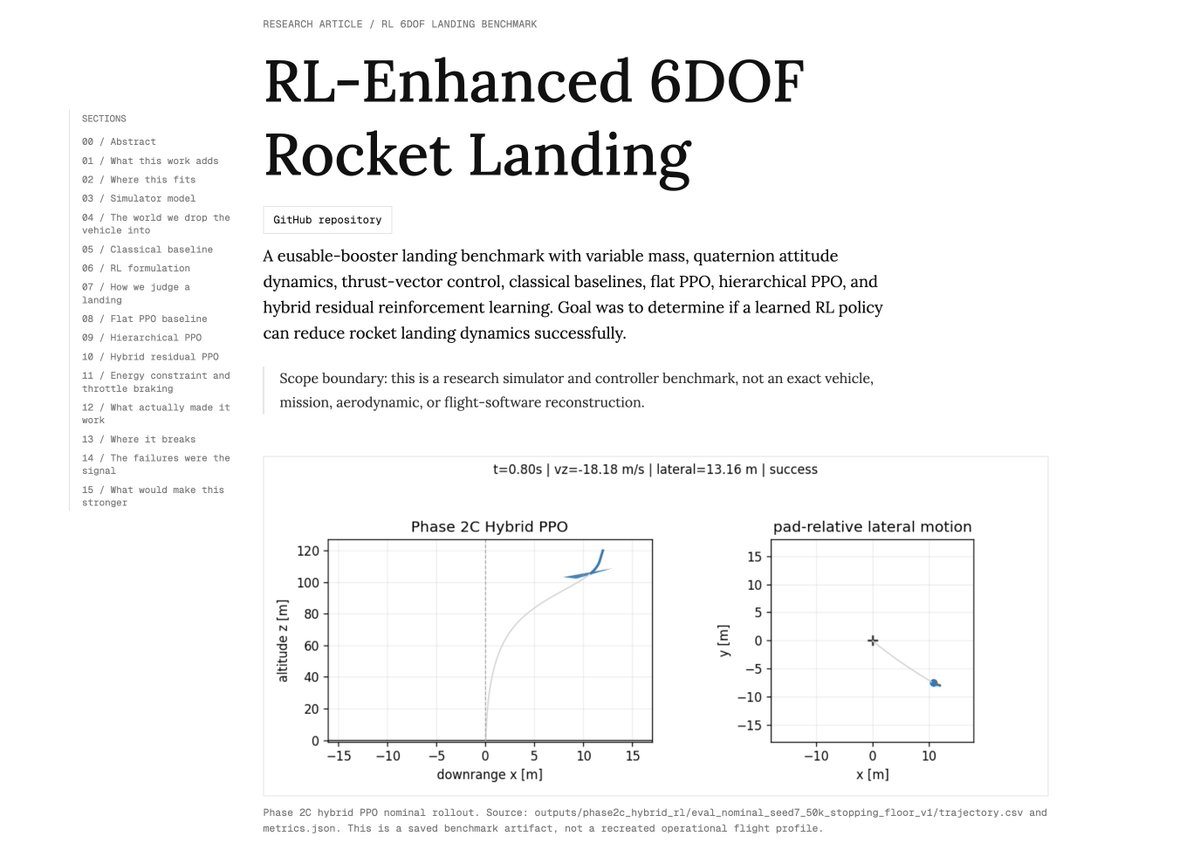
after 3 months of continuous crashing, i finally got rl to land a rocket by itself! yes, the complete 6dof dynamics: translation + rotation, variable mass, tvc, disturbances, all of it done by the rl itself.
the core issue is that landing is a constrained braking problem, not open-ended control. rl fails because the feasible solution manifold is extremely narrow.
once the search space was shaped properly, rl converged. i tried various rl policies and architectures to figure all this out.
full technical analysis here check it out!: https://t.co/IYrlPlmiPQ
A few months ago, I saw Karpathy build NanoChat in PyTorch, and it made me want to understand how these models work underneath the abstractions.
So I decided to try building one myself, but in a different framework: JAX.
Here’s how I did it: 🧵
Full stack:
→ Transformer implementation in raw JAX
→ Custom Optax training loop
→ Modal serverless GPUs
→ Alpaca fine-tuning
→ DuckDuckGo RAG pipeline
→ FastAPI + React chat interface
Building this gave me a much better understanding of transformer internals, inference optimization, and how modern LLM systems are actually put together.
Github: https://t.co/IksdAwW4un
Website:https://t.co/viGnjYlNYT
The project still has clear limitations.
162M parameters are enough to learn meaningful language patterns, but not enough for strong reasoning or reliable long-context conversations.
A lot of the remaining gaps are less about implementation correctness and more about scale and compute budget.