Want to see distributed computing explained via Pong?
Inspired by TinyTPU and TinyTapeout workshop at FOSSi, I wrote a paper under a week pairs this demo with a proposed next-gen optical I/O chip architecture & a roadmap to prototype it.
Read it on GitHub: https://t.co/td2oIRfIDW
A few months ago, I saw Karpathy build NanoChat in PyTorch, and it made me want to understand how these models work underneath the abstractions.
So I decided to try building one myself, but in a different framework: JAX.
Here’s how I did it: 🧵
We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000+ tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
@satvikgari and I have been building our own version of Nvidia’s Blackwell GPU.
We just designed a 4x4 systolic array in Verilog!
Here’s a breakdown of how it works and what we learned building it.
bit late to the recruiting cycle, but looking for a summer internship in ML/hardware/inference!!
i've been working on CUDA kernel writing, FPGA acceleration and RTL. would love to find a team doing similar work this summer
dual US/Canada citizen, can relocate anywhere
DMs open :)
wrote an article breaking down the math behind TurboQuant by @GoogleResearch.
I walk through a toy example using concrete numbers to show every single operation that goes on under the hood.
link below:
I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: https://t.co/m5vkJxWIY6
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep@GavinSherry
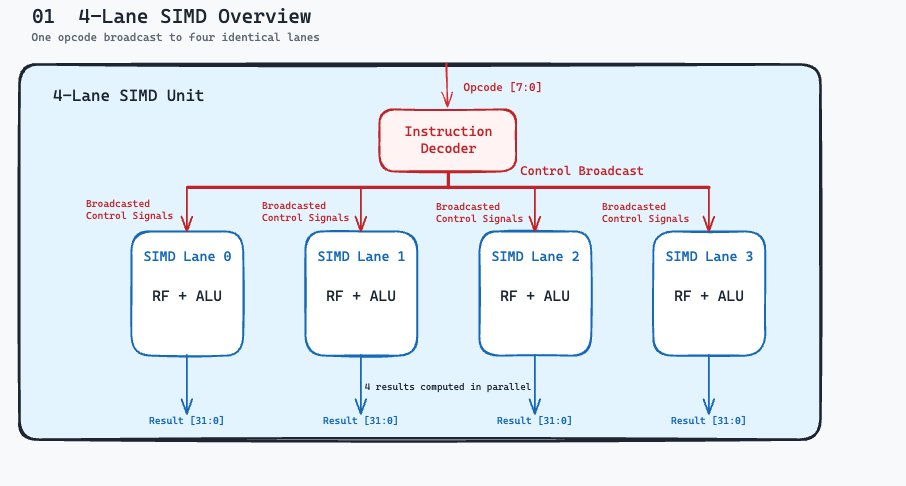
Recently @arjunharinath1 and I started building our own version of Nvidia's Blackwell GPU.
We built the ALUs and a 4-lane SIMD core in Verilog.
Here is a breakdown of how we did it.