Helix (SparseRL) is now OPEN-SOURCE!
Training massive models like DeepSeek-V3? Moving 1.3TB of weights (671GB×2 in BF16) between the RL trainer and rollout can add >2 minutes per step just on data transfer.
Everyone talks about compute. But for large-scale AI systems, weight movement is quietly becoming just as critical a bottleneck.
At ScitiX, we've spent months attacking this problem — not with faster GPUs, but with system-level optimization across the entire weight loading pipeline.
Built on Supernode C2C + NVSwitch with Memory Pooling, GSCP, Multicast, and end-to-end orchestration, we've developed two core capabilities:
· FlashLoad — local weight loading, dramatically accelerated
DeepSeek V3-pro: 45s → 1.47s (31× faster)
DeepSeek V3-flash: ~14s → 0.34s (up to 42× faster)
· FlashClone — seed-node based distributed weight cloning across 8 nodes over NVSwitch
110s → 13.5s (8× faster)
The most surprising finding: the actual weight transfer itself only takes ~0.37s. The remaining ~13s is NCCL connection setup overhead. The bottleneck is no longer bandwidth — it's coordination and initialization.
Our next milestone: 110s → ~0.5s. Weight synchronization that's nearly invisible at cluster scale.
This matters more than ever for RL training, elastic inference, fast failover, dynamic scheduling, and large-scale agent workloads. As models scale, infrastructure efficiency will increasingly be defined by how fast systems can load, clone, and sync weights.
More details coming soon.
🔬 Ever wonder WHY large-model RL fine-tuning creates such sparse weight updates?
It’s not magic; it’s the "Three-Gate Theory." The ~99% sparsity is a structural consequence of how RL fundamentally operates under the hood:
Gate I (KL Anchor): RL uses small learning rates and KL constraints, tightly bounding the step magnitude.
Gate II (Model Geometry): The pretrained spectrum steers these bounded updates away from principal directions onto off-principal, low-curvature coordinates.
Gate III (BF16 Precision): The final cast from FP32 to BF16 acts as a filter, suppressing these tiny sub-threshold updates.
Together, these three gates explain the extreme sparsity we exploit in SparseRL-sync. We built the infrastructure so you can build the future.
Read our tech report to dive deeper: https://t.co/UtrGP8OOnM
🧠 Did you know? In large-model RL training, over 99% of your weight updates might be completely invisible to the inference engine.
Let’s look at the "Precision-Gated Gap" we discovered while building SparseRL-sync:
• On the Trainer side, the FP32 master weights are almost constantly changing (over 99.4% of elements update every step).
• But when cast to BF16 for Rollout, the changed elements drop below 1%!
Why? Most RL updates are micro-changes that fall below the BF16 quantization threshold. ()They get fully absorbed during the FP32-to-BF16 cast and vanish after rounding.
SparseRL-sync capitalizes on this exact phenomenon, slashing redundant data transfers by up to 100x. Stop sending data that doesn't exist!
🌍 The future of scalable RL is cross-cluster.
Since rollout (offline inference) is typically the bottleneck in RL, SparseRL-sync makes cross-region training a reality.
Typical Deployment:
Cluster A: Training & partial rollout
Clusters B & C: Pure rollout
Fully utilize nation-wide GPU resources without the data-moving headache. Build the next-gen AI with us at Scitix! 👇
🔗 https://t.co/UtrGP8OOnM
🔬 Built for extreme scale and versatility, Helix is battle-tested:
• Scale: Validated on models from 8B dense to massive 671B MoE.
• Algorithms: Fully covers the most popular RL methods—GRPO, DAPO, and GSPO.
• Flexibility: Supports both generic & agentic training.
• Ecosystem: Seamlessly compatible with Slime & Miles.
Say goodbye to network bottlenecks without sacrificing a single drop of model performance.
🚀 Helix (SparseRL) is now OPEN-SOURCE!
Training massive models like DeepSeek-V3? Moving 1.3TB of weights (671GB×2 in BF16) between the RL trainer and rollout can add >2 minutes per step just on data transfer.
Enter SparseRL-sync from Scitix: An efficient framework that slashes data movement by 30x ~ 100x with exactly 100% accuracy.
Code & Tech Report: https://t.co/UtrGP8OOnM
#ReinforcementLearning #OpenSource #AIInfrastructure #Scitix
🥂What an epic night! Our #GTC2026 Happy Hour co-hosted with the SGLang team was a massive success! @lmsysorg@sgl_project
⚡️The venue was packed, and the conversations around SGLang's Scalable Multilingual LLM Serving Engine were electric. From tech deep-dives to future trends, the AI community energy was unmatched!
Thank you to everyone who came out! Catch you at the next GTC! 👇🎥
#SGLang #NVIDIA #LLM #TechEvent
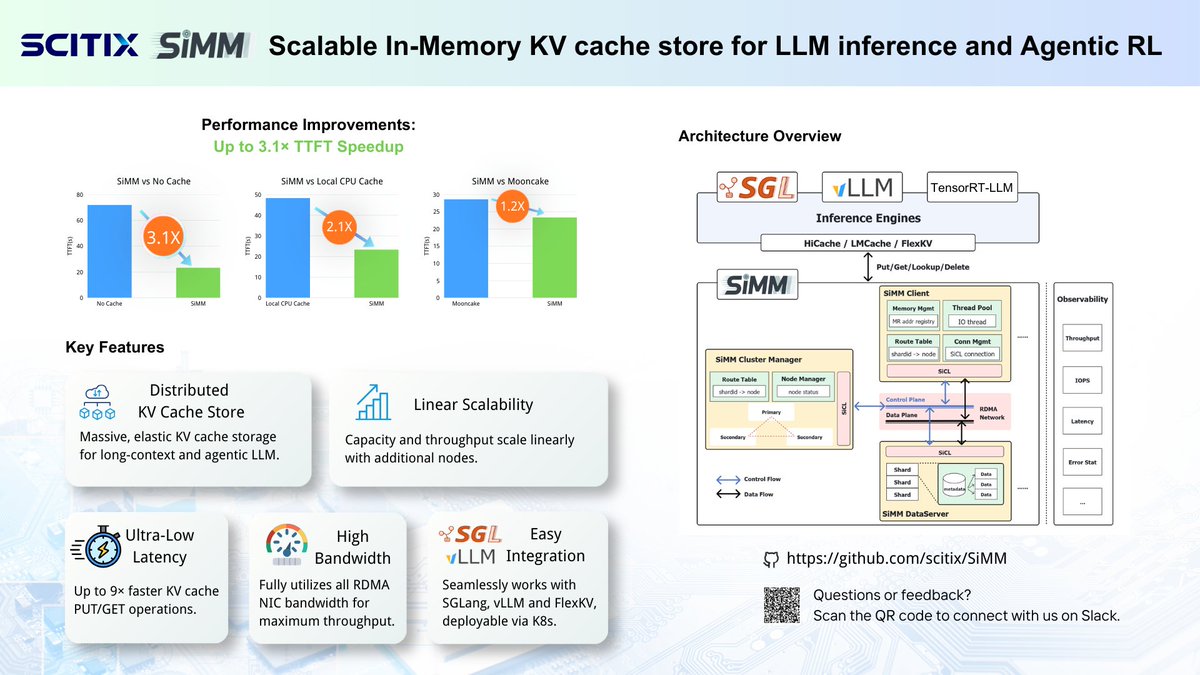
We didn't just build a cache; we built it for extreme scale.
🔥 Up to 9x lower latency via end-to-end zero-copy.
📈 Linear scalability & full utilization of ALL RDMA NICs.
🚀 3.1x TTFT speedup (at 32K context) vs. no-cache baselines!
Built for multi-turn agents and long Chain-of-Thought reasoning, SiMM is already proven in production and deploys easily via K8s.
Ready to accelerate your LLM serving and Agentic RL ? try it now!
🔗https://t.co/Ze22vXlLK2
#LLMs #OpenSource #AI #MachineLearning #KVCache
LLM context lengths have grown 4x in the past year, causing skyrocketing GPU costs and painful Time-To-First-Token (TTFT) latency. Today, we are thrilled to open-source SiMM ⚡️: an ultra-fast, scalable in-memory KV cache engine that breaks the long-context bottleneck!
SiMM transforms heavy prefill compute into high-speed I/O retrieval. It provides a scalable and low-latency memory pool for KV cache that seamlessly integrates with leading engines like @sgl_project and @vllm_project .
#LLM #OpenSource #AI #MachineLearning #KVCache
Thrilled to partner with @lmsysorg and an amazing crew for this! 🚀 If you're at GTC, come grab a drink and let's talk the future of AI compute. See you in San Jose! 🍻
🍝🍷 Taking a break from the GTC rush? Join us for an exclusive Happy Hour.
SGLang × @radixark are hosting a GTC 2026 Happy Hour with friends across the AI infra ecosystem! Expect great food, unlimited drinks, and conversations with researchers & engineers from OpenAI, xAI, DeepMind, Meta, NVIDIA, Ollama, and top AI startups.
📅 Mar 17, 6:30–8:30 PM
📍 Walking distance from GTC (location shared after approval)
Last year’s GTC meetup was the first time we met the SGLang community in person. Since then, we’ve been shipping nonstop: LLM inference breakthroughs, RL infra, diffusion framework, and more. Let’s push AI infrastructure forward together.⚡
🎟 Register: https://t.co/j9sPmU9AZ2
🔔 Subscribe to our meetup calendar so you don’t miss future events: https://t.co/LbyWoPgVoO
With appreciation to our partners:
@radixark@ZZZZZPotentials@scitix
Looking forward to seeing many friends there. ✨
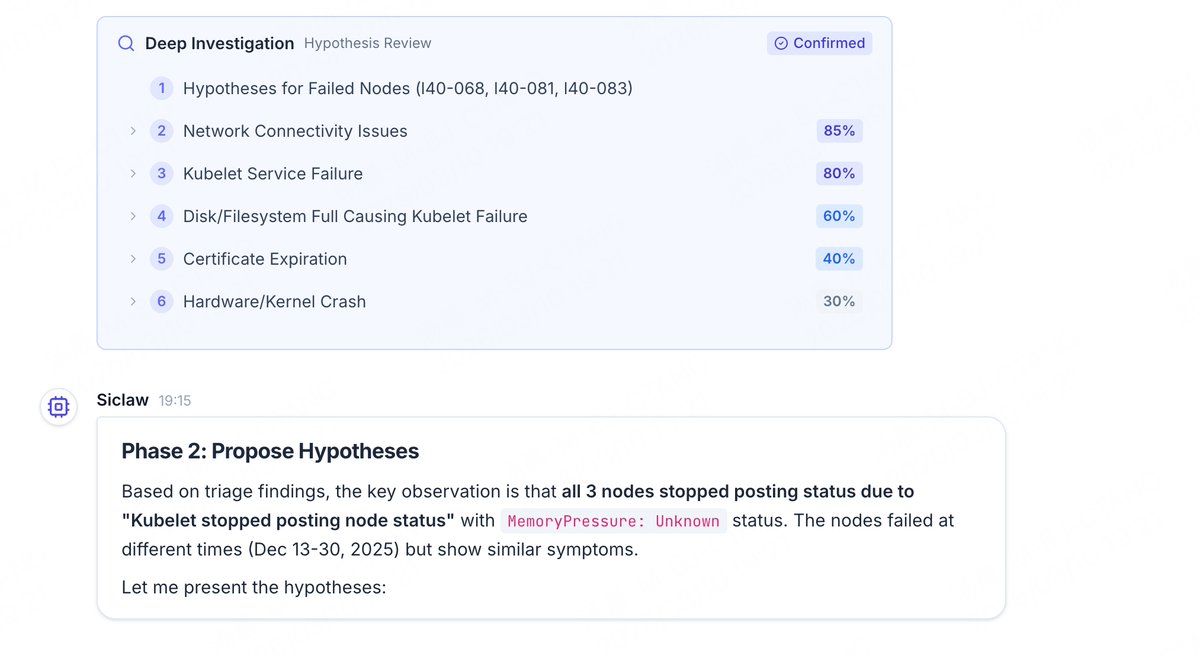
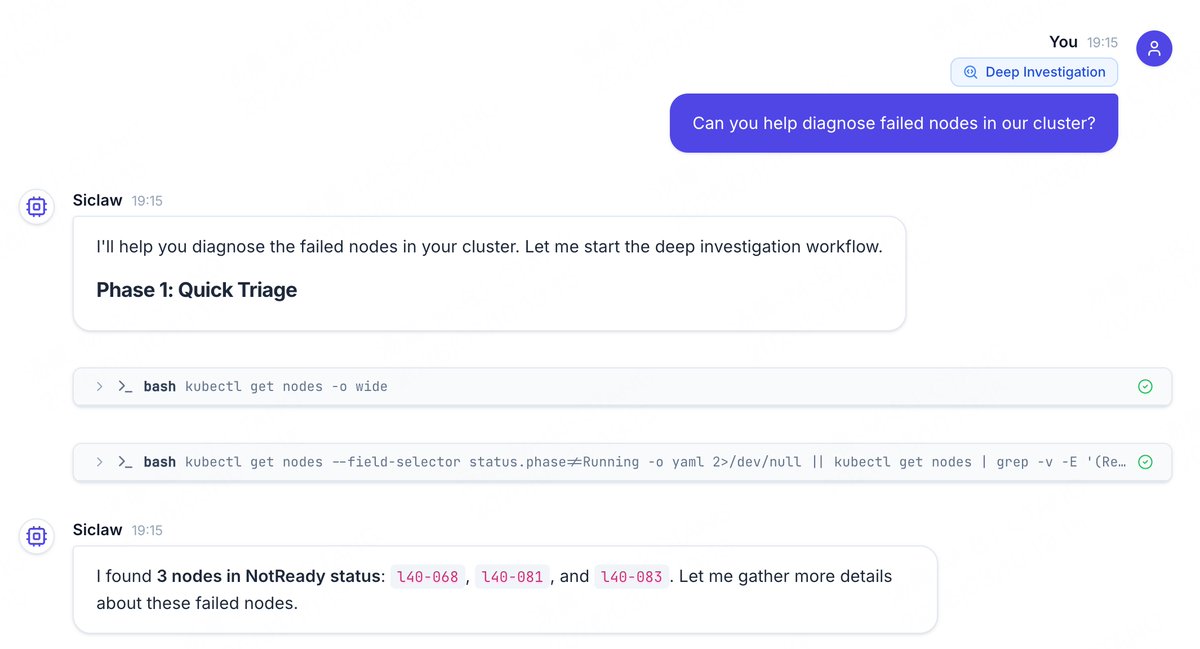
🛠️K8s down? Don't panic, ask Siclaw.
It troubleshoots like a Senior SRE on their best day:
1️⃣ Checks state
2️⃣ Builds hypotheses
3️⃣ Runs concurrent deep-dives
4️⃣ Delivers the fix < 1 min.
Why not put it to the test? Try it out here: 👇
https://t.co/XK0KZJ08pn
What makes SiClaw different from OpenClaw?
🔐 Security Governance
A strict permission layer between agents and infrastructure: read-only by default, command whitelists, per-action approval for writes, and workspace-isolated credentials to protect production environments.
👥 Team Collaboration
Built for enterprise teams with multi-workspace support, multi-user management (SSO/OAuth2), and isolated AgentBox sandboxes for different teams and environments.
⚡ Proactive Operations
Integrates with mainstream monitoring and alerting systems to detect anomalies, automatically generate diagnostic plans, and execute remediation actions—moving from reactive to autonomous operations.
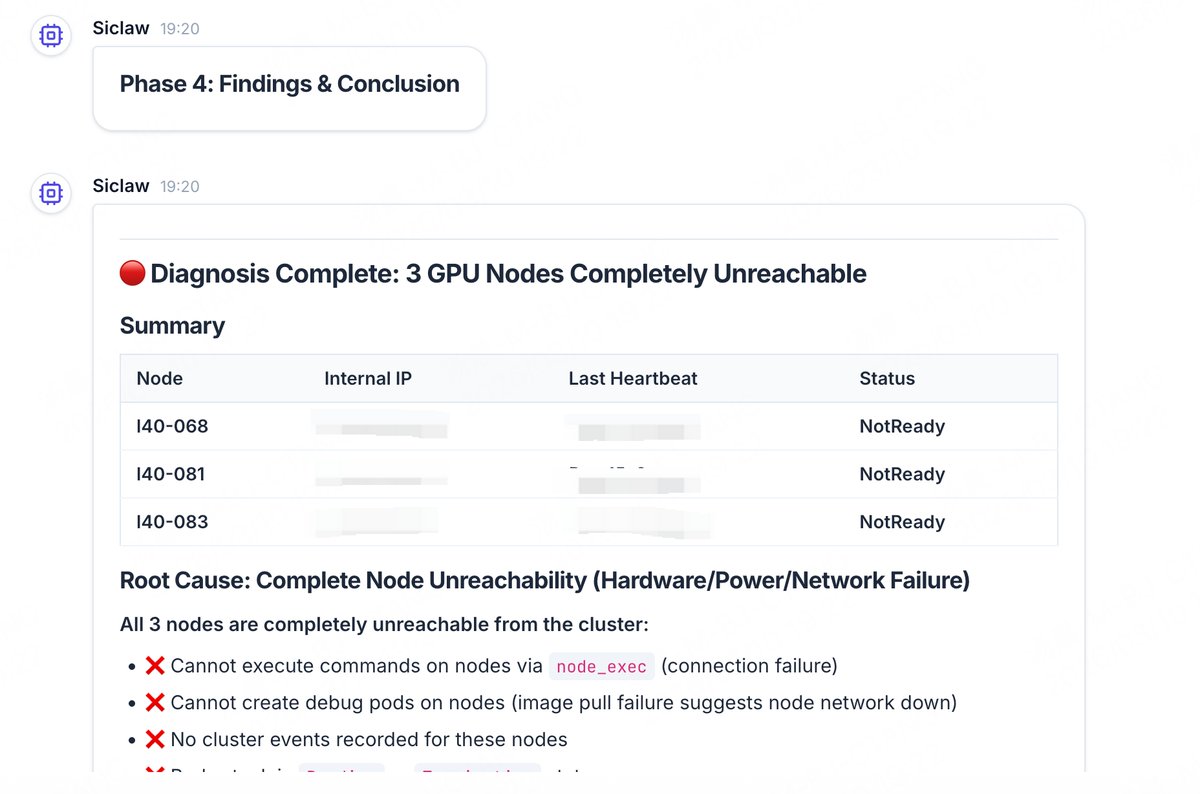
🔍 Deep Diagnostics
A hypothesis-driven 4-stage diagnostic engine: Context collection → Hypothesis generation → Parallel validation → Root-cause conclusion.
Bringing “Deep Research” capabilities into real-world operations.
💬 Join our community:
https://t.co/gJaVnDY0ol
🚀 We’re building SiClaw, an open-source AIOps platform based on Pi-Agent.
SiClaw focuses on Intelligent Infrastructure, DevOps Automation, and Dev–Ops Collaboration.
We welcome developers to try it out, share feedback, and contribute!
🌐 Website: https://t.co/QiLZ5dqeTu
💻 GitHub: https://t.co/9B6CWmY58d
#AIOps #DevOps #OpenSource
In AI infrastructure, comparing raw GPU models or TFLOPS is often not enough to see the full picture.
What truly matters is how much of that theoretical power translates into actual training efficiency.👇